xv6源码剖析 008
其实我发现顺序好像错了,应该先更新kalloc.c的,因为进程也是来自于内核的,但是更都更了,先写完proc.h和proc.c先。
直接开始。
全局变量
struct cpu cpus[NCPU];
struct proc proc[NPROC];
struct proc *initproc;
int nextpid = 1;
struct spinlock pid_lock;
procinit(void)
这个函数是在内核的main函数中调用的,用来初始化进程表(process table)。
这里补充一点,proc::lock是进程锁,上一期因为着急追剧,所以没有看到这个属性在最上面。
void
procinit(void)
{
struct proc *p;
initlock(&pid_lock, "nextpid");
for(p = proc; p < &proc[NPROC]; p++) {
// 初始化进程的进程锁
initlock(&p->lock, "proc");
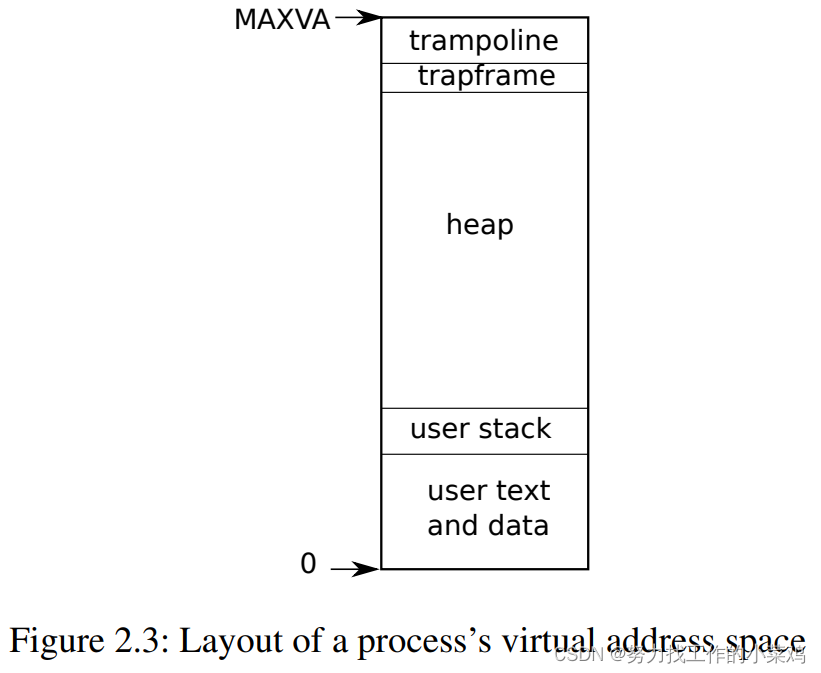
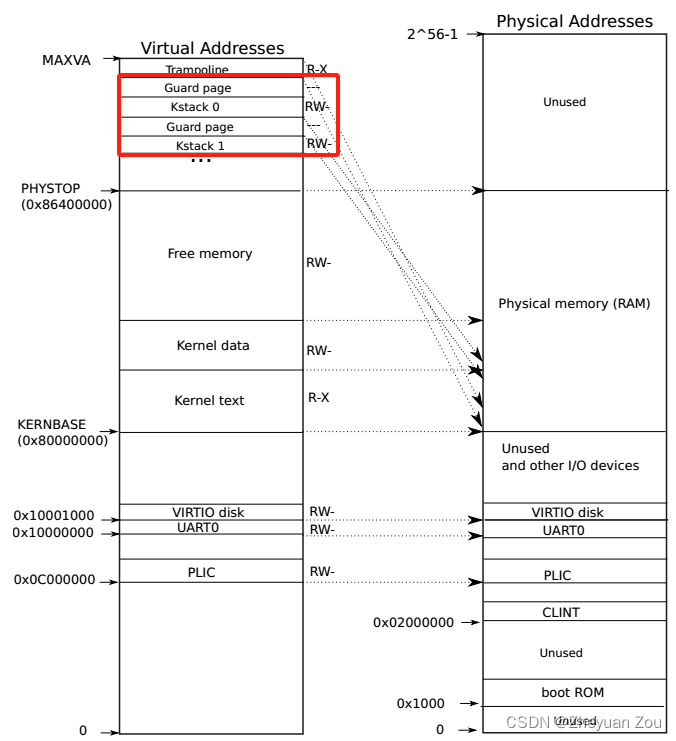
// Allocate a page for the process's kernel stack.
// Map it high in memory, followed by an invalid
// guard page.
// 每个进程的内核栈,
// xv6的进程的内核栈是有固定的物理地址的。
// 能够通过内核代码提供的一个宏函数算出来
char *pa = kalloc();
if(pa == 0)
panic("kalloc");
uint64 va = KSTACK((int) (p - proc));
kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
p->kstack = va;
}
// 这个函数在vm.c中,用来设置寄存器stap值
// stap -> kernelpage
// 并且允许分页
kvminithart();
}
cpuid()
这个函数用来获取当前cpu的编号,这个函数通过调用一个内联汇编函数来从寄存器 tp 中获取对应的值。因为每个cpu都有自己的一套寄存器,所以不同的cpu调用这个函数获取到的值是不一样的。
int
cpuid()
{
int id = r_tp();
return id;
}
struct cpu* mycpu(void)
获取对cpu进行抽象后的一个结构体,struct cpu。
struct cpu*
mycpu(void) {
int id = cpuid();
struct cpu *c = &cpus[id];
return c;
}
struct proc* myproc(void)
获取当前的进程的结构体
struct proc*
myproc(void) {
push_off();
struct cpu *c = mycpu();
struct proc *p = c->proc;
pop_off();
return p;
}
pop_off()是定义在spinlock.c中函数,与之对应的是push_off(),两者都是通过调用内联的汇编函数来打开或者禁止设备中断(device interrupts),因为xv6在自旋锁创建的临界区之间是不允许中断的,因为这有可能会产生死锁;在小书中说到,xv6坚持的是从简的原则,所以直接一棒子打死了;而睡眠锁(sleep lock)则允许进程或线程在睡眠的时候获取锁(具体细节我忘了,到时候再看看)。
int allocpid()
获取一个进程id
int
allocpid() {
int pid;
acquire(&pid_lock);
pid = nextpid;
nextpid = nextpid + 1;
release(&pid_lock);
return pid;
}
下面这个函数很重要,我们在页表实验的时候也会涉及到
static struct proc* allocproc(void)
简述一下作用:从进程表中找到一个处于UNUSED状态的进程,并重用该进程。
static struct proc*
allocproc(void)
{
struct proc *p;
// 遍历进程表,并试图找到一个UNUSED进程
for(p = proc; p < &proc[NPROC]; p++) {
// 获取进程锁,互斥访问
acquire(&p->lock);
if(p->state == UNUSED) {
// 如果找到了UNUSED进程
goto found;
} else {
// 释放进程锁
release(&p->lock);
}
}
return 0;
found:
// 分配一个进程id
p->pid = allocpid();
// 获取一个trapframe page
// 这个page在我们进行trap的时候发挥着关键的作用
// Allocate a trapframe page.
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
release(&p->lock);
return 0;
}
// An empty user page table.
// 获取一个空的用户页表
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
// 设置一个新的上下文
memset(&p->context, 0, sizeof(p->context));
// 一般需要产生新进程都是由于fork系统调用
// 所以设置返回地址返回到调用fork的上下文
p->context.ra = (uint64)forkret;
// 将sp寄存器指向栈底,因为栈是从
// 高地址向低地址生长的
p->context.sp = p->kstack + PGSIZE;
return p;
}
static void freeproc(struct proc *p)
回收一个进程
流程大概是:清空trapframe page 的映射,因为这个一个共享的页,如果释放了,内核会崩掉。设置进程的状态为UNUSED,将进程的其他的标志也清空。
static void
freeproc(struct proc *p)
{
if(p->trapframe)
kfree((void*)p->trapframe);
p->trapframe = 0;
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED;
}
pagetable_t proc_pagetable(struct proc *p)
获取一个进程页表。
pagetable_t
proc_pagetable(struct proc *p)
{
pagetable_t pagetable;
// 获取一个空页表
pagetable = uvmcreate();
if(pagetable == 0)
return 0;
// 创建tramframe 和 trampoline 的映射
if(mappages(pagetable, TRAMPOLINE, PGSIZE,
(uint64)trampoline, PTE_R | PTE_X) < 0){
uvmfree(pagetable, 0);
return 0;
}
// map the trapframe just below TRAMPOLINE, for trampoline.S.
if(mappages(pagetable, TRAPFRAME, PGSIZE,
(uint64)(p->trapframe), PTE_R | PTE_W) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
return pagetable;
}
void proc_freepagetable(pagetable_t pagetbale, uint64 sz)
清空一个页表的映射资源
void
proc_freepagetable(pagetable_t pagetable, uint64 sz)
{
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmfree(pagetable, sz);
}
下面这个有点抽象,是一段机器码,我看不懂。所以把注释附上去了,哈哈
// a user program that calls exec("/init")
// od -t xC initcode
uchar initcode[] = {
0x17, 0x05, 0x00, 0x00, 0x13, 0x05, 0x45, 0x02,
0x97, 0x05, 0x00, 0x00, 0x93, 0x85, 0x35, 0x02,
0x93, 0x08, 0x70, 0x00, 0x73, 0x00, 0x00, 0x00,
0x93, 0x08, 0x20, 0x00, 0x73, 0x00, 0x00, 0x00,
0xef, 0xf0, 0x9f, 0xff, 0x2f, 0x69, 0x6e, 0x69,
0x74, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00
};
void userinit(void)
这个函数跟本篇的第一个函数procinit一样,也是在内核的main函数中调用的,它初始化内核的第一个用户进程,这个进程作为这个操作系统进程树(process tree)的根节点(root)。
这个进程的主要的作用是:管理孤儿进程。什么是孤儿进程呢?我们直接看看gpt的回答
操作系统处理孤儿进程的方式如下:
- 识别孤儿进程: 当一个进程(父进程)非正常终止(如崩溃、被杀死或正常退出但未正确清理子进程)时,其任何仍在运行的子进程将变为孤儿进程。操作系统通过监测进程间关系来识别这种情况:当一个进程终止时,系统检查其是否有尚未终止的子进程。
- 收养孤儿进程: 一旦检测到孤儿进程,操作系统会立即采取行动,通常由一个特殊进程——
init进程(进程ID为1,是所有进程的始祖)来“收养”这些孤儿进程。init进程接管孤儿进程,成为它们新的父进程。这意味着孤儿进程的父进程PID(PPID)会被更新为1。 - 资源回收: 对于孤儿进程而言,虽然它们失去了原始父进程,但由于被
init进程及时收养,它们不会像僵尸进程那样长时间停留在系统中。init进程是一个设计上能够正确管理子进程生命周期的进程,它会定期调用wait()或waitpid()系统调用来等待其子进程(包括收养的孤儿进程)结束,并收集它们的退出状态信息。这样,孤儿进程在终止后能够立即释放其在内核中占用的资源(如进程控制块、打开的文件描述符等),不会造成资源泄漏。 - 确保孤儿进程继续运行或正常终止: 收养过程不影响孤儿进程自身的运行状态。孤儿进程将继续执行直到其自然结束,或者接收到终止信号。由于已经成为
init进程的子进程,孤儿进程现在遵循init进程的信号处理规则,确保即使原父进程未能正确处理子进程的退出,孤儿进程也能得到妥善处理。
总结来说,操作系统通过快速识别孤儿进程、将其交给init进程收养、确保资源及时回收以及维持孤儿进程的正常运行或终止流程,有效地管理孤儿进程,避免了因父进程异常导致的子进程管理问题和系统资源浪费。这样,孤儿进程虽然失去了原始父进程,但其生命周期得到了完整且有效的管理,不会对系统稳定性和资源利用率造成负面影响。
void
userinit(void)
{
struct proc *p;
p = allocproc();
initproc = p;
// allocate one user page and copy init's instructions
// and data into it.
uvminit(p->pagetable, initcode, sizeof(initcode));
p->sz = PGSIZE;
// prepare for the very first "return" from kernel to user.
p->trapframe->epc = 0; // user program counter
p->trapframe->sp = PGSIZE; // user stack pointer
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
p->state = RUNNABLE;
release(&p->lock);
}
函数的实现也是比较简单,但是确实比较有学问在里面。
今天就先到这了,晚安玛卡巴卡。