Spark面试整理-Spark集成Kafka
- 开发
- 30
-
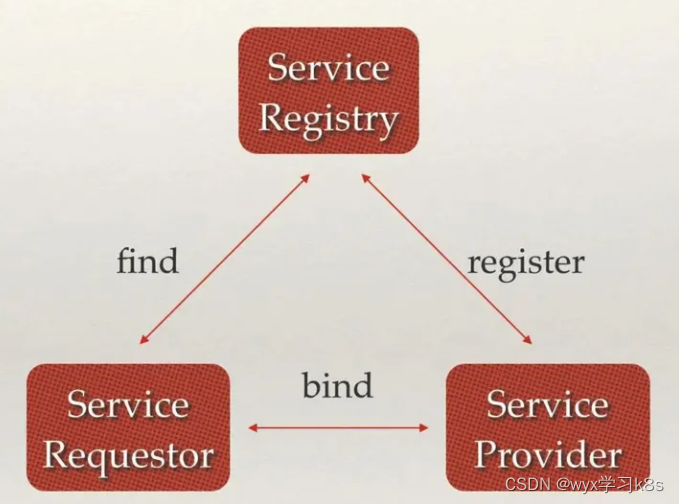
Apache Spark和Apache Kafka的集成使得实时数据流处理成为可能。Kafka是一个分布式流处理平台,主要用于构建实时数据管道和流应用。而Spark是一个大规模数据处理工具,可以对大量数据进行批处理和实时处理。
Spark集成Kafka主要通过Spark Streaming或者Structured Streaming实现,可以从Kafka中读取数据,处理后再写回Kafka或者其他存储系统。
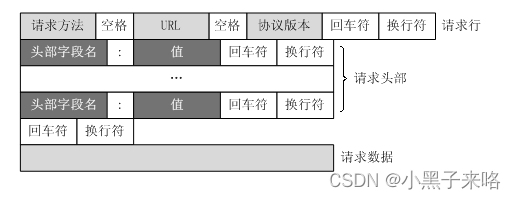
以下是一个使用Spark Structured Streaming从Kafka读取数据的基本示例:
import org.apache.spark.sql
原文地址:https://blog.csdn.net/ISWZY/article/details/137876472
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1781965617272852480.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!