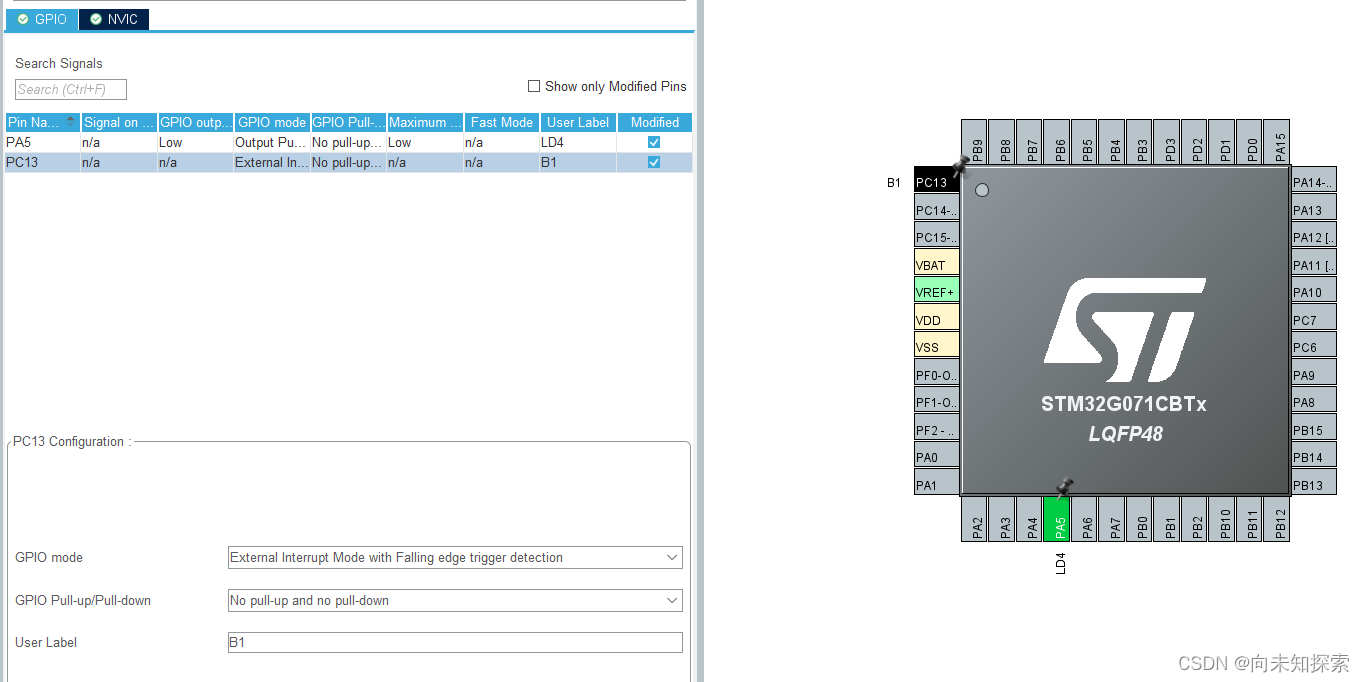
python基础笔记
参考
字符串拼接,特殊字符打印
字符串拼接可以用+号。print打印最后默认会换行。\为转义符,比如"表示双引号,\n换行
可以自动换行用三个引号
print('''see you
see you spaceboy
someday
somewhere''')
运算
乘方符号两个*,向下取整的除法用两个/
print(2**3)
#输出8
#导入math库
import math
#math.函数名()
math.sin(1)
print(3 / 2)#1.5
print(3 // 2)#1
注释
单行用#号,多行用三引号
输入
#input括号里是输入提示,会被打印出来,input返回的是字符串
use_num = input("input cowboy")
print(use_num)
条件语句
注意:条件之后要加上冒号,只会执行一个分支
#在条件之后记得加上冒号
if use_num >= 10:
print("more than 10")
#嵌套的if语句块要继续缩进
if use_num > 15:
print("more than 15")
#python的 elseif
elif use_num >= 23:
print("23")
else:
print("less")
print("than")
print("不缩进的 不再if-else范围里")
#可以使用数学形式的不等式
'''
elif 27 >= use_num >= 23:
print("27~23")
'''
逻辑运算
与and,或or,非not
列表
注意:python的列表可以存不同类型的数据
#列表 =一个方括号
user_list = []
#添加元素 可以不同类型
user_list.append(123)
user_list.append("123")
user_list.append(127.0)
user_list.append(12)
user_list.append(125)
print(user_list)
#获取长度
print(len(user_list))
#移出指定元素,有多个重复值情况下,一条语句只删除一次
user_list.remove("123")
user_list.remove(127.0)
print(user_list)
print(len(user_list))
#排序函数sorted,升序
print(sorted(user_list))
print(user_list)
#可以用索引访问元素
print(user_list[0])
字典(键值对)
#花括号引起来,键值之间冒号连接
contacts = {
"boy": "spike",
"girl": "faye"
}
print(contacts["boy"])
contacts["woman"] = "julia"
print(contacts)
female = "woman"
if female in contacts:
print(contacts[female])
print(len(contacts))
for循环
contacts = {
"boy": "spike",
"girl": "faye"
}
contacts["woman"] = "julia"
# keys,values,items表示范围键,值,键值对
for person, name in contacts.items():
print(person + ' ' + name + '\n')
for person in contacts.values():
print(person + '\n')
sum = 0
# 结束值不在循环范围里,这里是1-100,第三个参数表示步长
for i in range(1, 101, 2):
sum += i
print(sum)
while
python的for适合知道次数的遍历,如遍历列表,而while适合条件成立时的循环
user_in = input("end with q")
while user_in != 'q':
user_in = input("end with q")
format方法
字符串里插入变量的对应的键,对应地方就被变量内容替换
faye = "valentine"
julia = "julia"
spike = "jet"
#将变量对应关键字,就不用遵循顺序
message_content = '''see you
see you {ed},{spike},{ein}
someday
somewhere'''.format(ed=faye, spike=julia, ein=spike)
print(message_content)
# 花括号内可以用数字,对应后面参数出现的顺序
message_content = '''see you
see you {2},{1},{0}
someday
somewhere'''.format(faye, julia, spike)
print(message_content)
#前面加上一个f,花括号里写变量名也可以达到一样效果
message_content = f'''see you
see you {faye},{spike},{julia}
someday
somewhere'''
print(message_content)
函数
注意:同样函数名后有一个冒号,函数体每行要缩进
def my_print(sex, name, age):
print("sex:" + sex + "name:" + name + "age:" + str(age))
return sex + name
res = my_print('女', '宇多田光', 30)
print(res)
import引入库
#直接接库名,调用时要用名字.函数名/变量名
import math
math.sin(1)
#from import,只引入需要的部分,访问时不需要加库名
from statistics import median, mean
# 中位数
print(median(stu_score))
类的创建
class Cat:
# 构造函数前后两个下划线,第一个参数是对象本身
def __init__(self, name, age, color):
self.name = name
self.age = age
self.color = color
def miao(self):
print(f'我的名字叫{self.name}')
luoxiaohei = Cat('罗小黑', 200, "black")
# print(f'早安喵{luoxiaohei.name}晚安喵{luoxiaohei.color}')
luoxiaohei.miao()
继承
注意:子类的构造函数 不会 默认调用父类的构造函数,要用super()显示调用父类的构造函数。
class Animal:
def __init__(self, name, age):
self.name = name
self.age = age
class Cat(Animal):
# 前后两个下划线,第一个参数是对象本身
def __init__(self, name, age, color):
# super后有一个()
super().__init__(name, age)
self.color = color
def miao(self):
print(f'我的名字叫{self.name}')
luoxiaohei = Cat('罗小黑', 13, "black")
print(luoxiaohei.age)
异常
try:
#可能产生错误的语句
cat_age = int(input("please input:\n"))
except ValueError:#ValueError类型:值错误
print("input illegal\n")
else:
print('没有错误时执行')
finally:
print("finally 无论错误与否都执行")
高级函数,函数名作为参数
def my_adder(x, y):
return x + y
class Cat(Animal):
# 前后两个下划线,第一个参数是对象本身
def __init__(self, name, age, color):
# super后有一个()
super().__init__(name, age)
self.color = color
#my_adder作为函数参数传入
def cat_adder(self, x, y, my_adder):
return my_adder(x, y)
luoxiaohei = Cat('罗小黑', 13, "black")
print(luoxiaohei.cat_adder(1, 2, my_adder))
匿名函数
用lambda引导,冒号后只能有一个语句,不用写return
# 匿名函数冒号后只能有一个语句
print(luoxiaohei.cat_adder(1, 2, lambda x, y: x + y))
文件操作以写为例
文件操作前,需要先open打开文件,操作完毕后再close关闭文件
#写入模式w,会清空原有的内容,a追加模式,r+支持读写,追加模式
f=open('./douban_comment.txt','a',encoding='utf-8')
response=requests.get("https://movie.douban.com/",headers=headers)
content=response.text
soup=BeautifulSoup(content,"html.parser")
articles=soup.find_all('p')
for paragragh in articles:
#print(f'{paragragh.text}\n')
#写入文件
f.write(f'{paragragh.text}\n')
#需要关闭文件
f.close()
'''
#不用手动关闭文件的方式
with open('./inTheMoodForLove_comment.txt','w',encoding='utf-8') as f:
response=requests.get("https://movie.douban.com/review/1570258/",headers=headers)
content=response.text
soup=BeautifulSoup(content,"html.parser")
articles=soup.find('div',attrs={'class':'review-content clearfix'})
#print(articles.text)
f.write(f'{articles.text.strip()}\n')
'''