分布式锁的实现
- 开发
- 44
-
一、背景
- 在分布式系统中,一个应用部署在多台机器中,在某些场景下,为了保证数据的一致性,要求在同一时刻,同一任务只在一个节点上运行,即保证某个行为在同一时刻只能被一个线程执行。
- 在单机单进程多线程环境下,通过锁很容易做到,比如
mutex、spinlock、信号量 等。
- 在多机多进程环境下,就需要使用
分布式锁 来解决了。
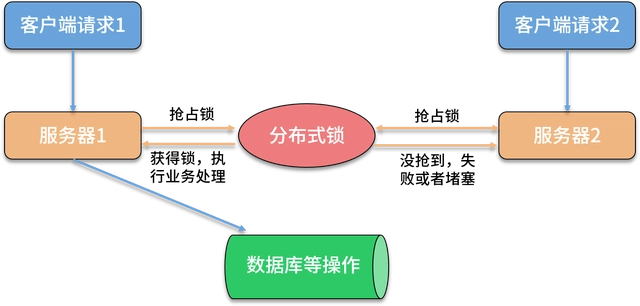
- 分布式场景:我们的应用由多个节点构成,这些节点可能分布在不同的机器中,也有可能分布在不同的网络环境中,通常这些进程之间通过
socket 进行通信。
二、分布式锁
- 是什么类型的锁 ?
- 解决了什么问题 ?
- 锁 = 资源 + 行为:
- 资源:
- 要记录进程的全局唯一 ID。
- 放在
数据库、zookeeper 或 etcd 中,可以让所有的执行体访问。
- 行为:加锁、解锁。(以网络通信的方式)
- 加锁:把当前进程的唯一标识打到当前数据库的某一个字段中,作为一个标记,说明当前进程持有锁。
- 解锁:谁加的锁,谁释放锁,也就是加锁对象和解锁对象必须是同一个对象,除了因为网络异常而造成的锁超时情况。
- 解锁的方式:持锁方去清除标记,比如置为 0,这样其他的进程才能去加锁。
三、分布式锁特性
- 互斥性。
- 锁打上标记:加锁。
- 锁取消标记:解锁。
- 标记:执行体的唯一标识,可以通过雪花算法生成。
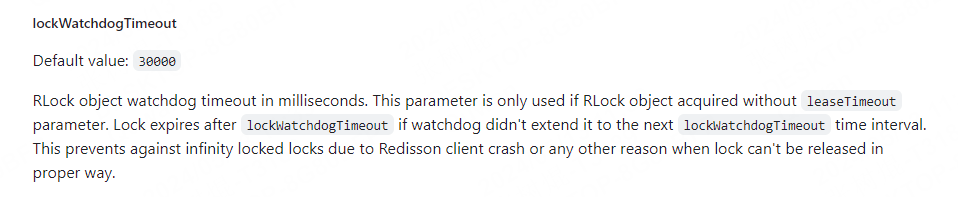
- 锁超时。
- 在分布式场景中,允许一个进程退出,并希望其他的进程能够继续工作。
- 当持有锁的进程想要解锁的时候,由于某些原因,比如进程宕机、网络异常,导致无法清除数据库中的标记,也就是持锁的进程没有能力去释放锁了,那么我们应该提供一种机制,让数据库自动地去释放锁 → 时间一到,数据库自动地释放锁。
- 可用性。
- 容错性。
- 一致性来解决(半数以上)。
高可用 = 可用性 + 容错性。
四、分布式锁类型
- 重入锁和非重入锁。
- 重入锁:
- 允许同一个线程多次获取同一把锁,而不会导致死锁。当一个线程持有锁时,它可以再次获取相同的锁而不被阻塞。
std::recursive_mutex。
- 非重入锁:
- 不允许同一个线程在持有锁的情况下再次获取相同的锁,会导致死锁。
std::mutex。
- 公平锁和非公平锁。
- 公平锁:排队,对应互斥锁。
- 非公平锁:轮询,对应自旋锁。
五、实现分布式锁
- 基于中间件来实现 → 所有的节点都能访问到。
- 资源存储在中间件中。
- 加锁、解锁行为基于中间件的特性来实现。
MySQL 实现分布式锁
原文地址:https://blog.csdn.net/weixin_44585214/article/details/137716072
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1779604055006515200.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!


























![[Kubernetes[K8S]集群:master主节点初始化]:通过Calico和Coredns网络插件方式安装](https://img-blog.csdnimg.cn/direct/b63cead751c246ae89fb3c6c379de941.png)