
第四章 HBase分布式数据库
1、HBase概述
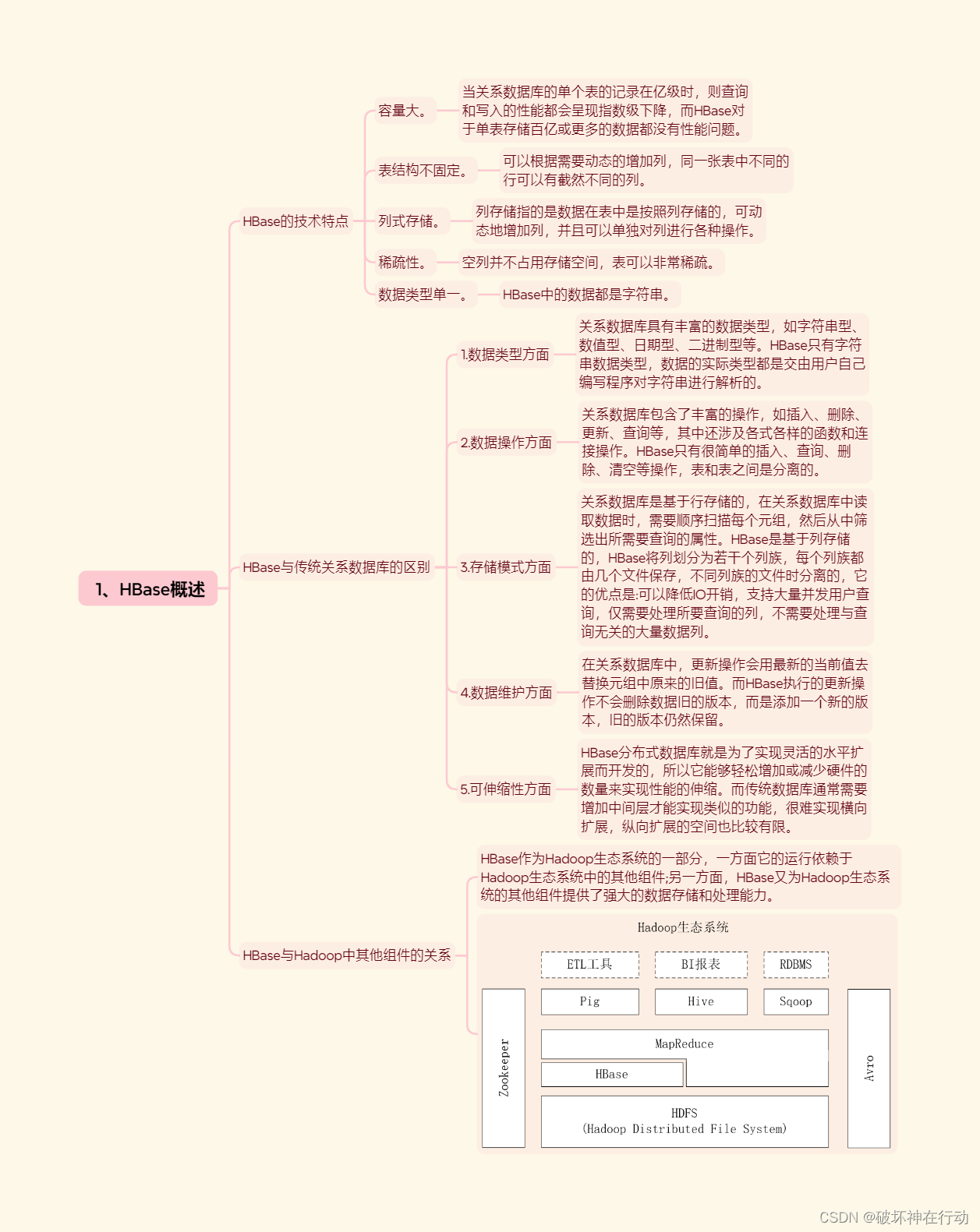
HBase的技术特点
容量大。
当关系数据库的单个表的记录在亿级时,则查询和写入的性能都会呈现指数级下降,而HBase对于单表存储百亿或更多的数据都没有性能问题。
表结构不固定。
可以根据需要动态的增加列,同一张表中不同的行可以有截然不同的列。
列式存储。
列存储指的是数据在表中是按照列存储的,可动态地增加列,并且可以单独对列进行各种操作。
稀疏性。
空列并不占用存储空间,表可以非常稀疏。
数据类型单一。
HBase中的数据都是字符串。
HBase与传统关系数据库的区别
1.数据类型方面
关系数据库具有丰富的数据类型,如字符串型、数值型、日期型、二进制型等。HBase只有字符串数据类型,数据的实际类型都是交由用户自己编写程序对字符串进行解析的。
2.数据操作方面
关系数据库包含了丰富的操作,如插入、删除、更新、查询等,其中还涉及各式各样的函数和连接操作。HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的。
3.存储模式方面
关系数据库是基于行存储的,在关系数据库中读取数据时,需要顺序扫描每个元组,然后从中筛选出所需要查询的属性。HBase是基于列存储的,HBase将列划分为若干个列族,每个列族都由几个文件保存,不同列族的文件时分离的,它的优点是:可以降低IO开销,支持大量并发用户查询,仅需要处理所要查询的列,不需要处理与查询无关的大量数据列。
4.数据维护方面
在关系数据库中,更新操作会用最新的当前值去替换元组中原来的旧值。而HBase执行的更新操作不会删除数据旧的版本,而是添加一个新的版本,旧的版本仍然保留。
5.可伸缩性方面
HBase分布式数据库就是为了实现灵活的水平扩展而开发的,所以它能够轻松增加或减少硬件的数量来实现性能的伸缩。而传统数据库通常需要增加中间层才能实现类似的功能,很难实现横向扩展,纵向扩展的空间也比较有限。
HBase与Hadoop中其他组件的关系
HBase作为Hadoop生态系统的一部分,一方面它的运行依赖于Hadoop生态系统中的其他组件;另一方面,HBase又为Hadoop生态系统的其他组件提供了强大的数据存储和处理能力。
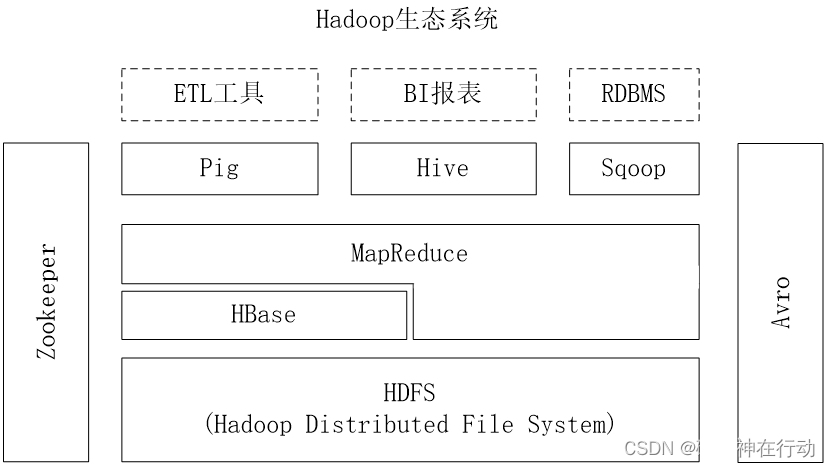
2、HBase系统架构和数据访问流程
系统架构
HBase采用MasterlSlave架构,由HMaster服务器、HRegionServer服务器和ZooKeeper协同服务器构成。在底层,HBase将数据存储于HDFS中。HBase系统架构如图所示。
1.客户端
客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的HRegion位置信息,用来加快后续数据访问过程。
2.Zookeeper服务器
Zookeeper服务器用来为HBase集群提供稳定可靠的协同服务,Zookeeper存储了-ROOT-表的地址和HMaster的地址,客户端通过-ROOT-表可找到自己所需的数据。
3.HMaster服务器
每台HRegionServer都会和HMaster服务器通信。
HMaster服务器的主要任务就是告诉每个HRegionServer它主要维护哪些HRegion。
HMaster用于
协调多个HRegionServer,
侦测各个HRegionServer的状态,
负责分配HRegion给HRegionServer,
平衡HRegionServer之间的负载。
4.HRegionServer
维护HMaster分配给它的HRegion,
处理用户对这些Hegion的I/O请求,
还负责切分在运行过程中变得过大的HRegion。
内部管理了一系列HRegion对象
每个HRegion对应了表(Table)中的一个Region。
HBase表根据Row Key的范围被水平拆分成若干个HRegion。每个HRegion都包含了这个HRegion的start key和end key之间的所有行((row) 。
数据访问流程
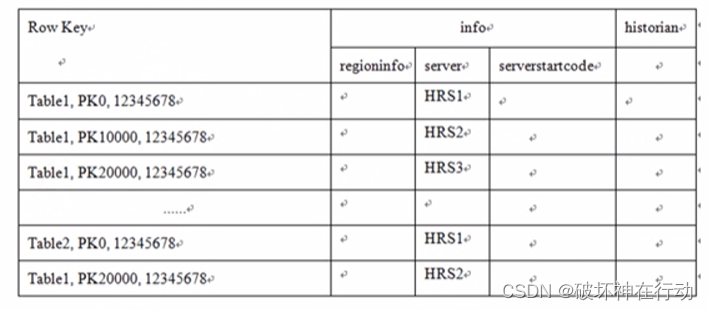
-ROOT-表
-ROOT-表是一张存储.META,表的表,记录了.META,表的HRegion信息。
.META.表
假设要从Table2里面查询一条Row Key是RK10000的数据,那么应该遵循以下步骤:
①从.META.表里面查询哪个HRegion包含这条数据。 ②获取管理这个HRegion的HRegionServer地址。 ③连接这个HRegionServer,查到这条数据。
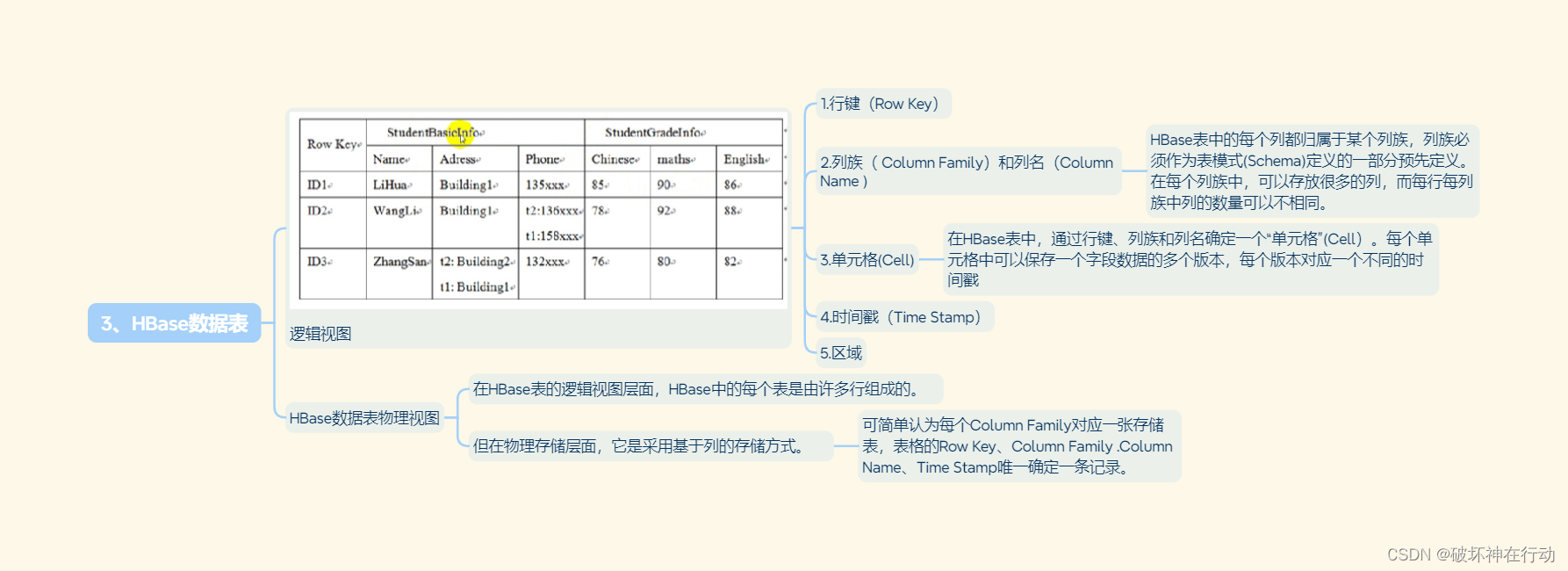
3、HBase数据表
逻辑视图
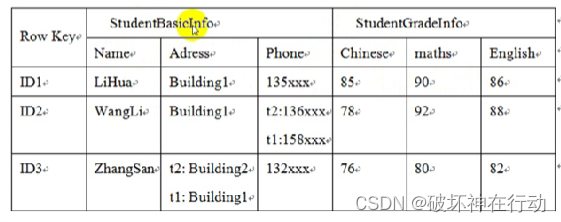
1.行键(Row Key)
2.列族( Column Family)和列名(Column Name )
HBase表中的每个列都归属于某个列族,列族必须作为表模式(Schema)定义的一部分预先定义。在每个列族中,可以存放很多的列,而每行每列族中列的数量可以不相同。
3.单元格(Cell)
在HBase表中,通过行键、列族和列名确定一个“单元格”(Cell)。每个单元格中可以保存一个字段数据的多个版本,每个版本对应一个不同的时间戳
4.时间戳(Time Stamp)
5.区域
HBase数据表物理视图
在HBase表的逻辑视图层面,HBase中的每个表是由许多行组成的。
但在物理存储层面,它是采用基于列的存储方式。
可简单认为每个Column Family对应一张存储表,表格的Row Key、Column Family .Column Name、Time Stamp唯一确定一条记录。
4、HBase安装
5、HBase配置
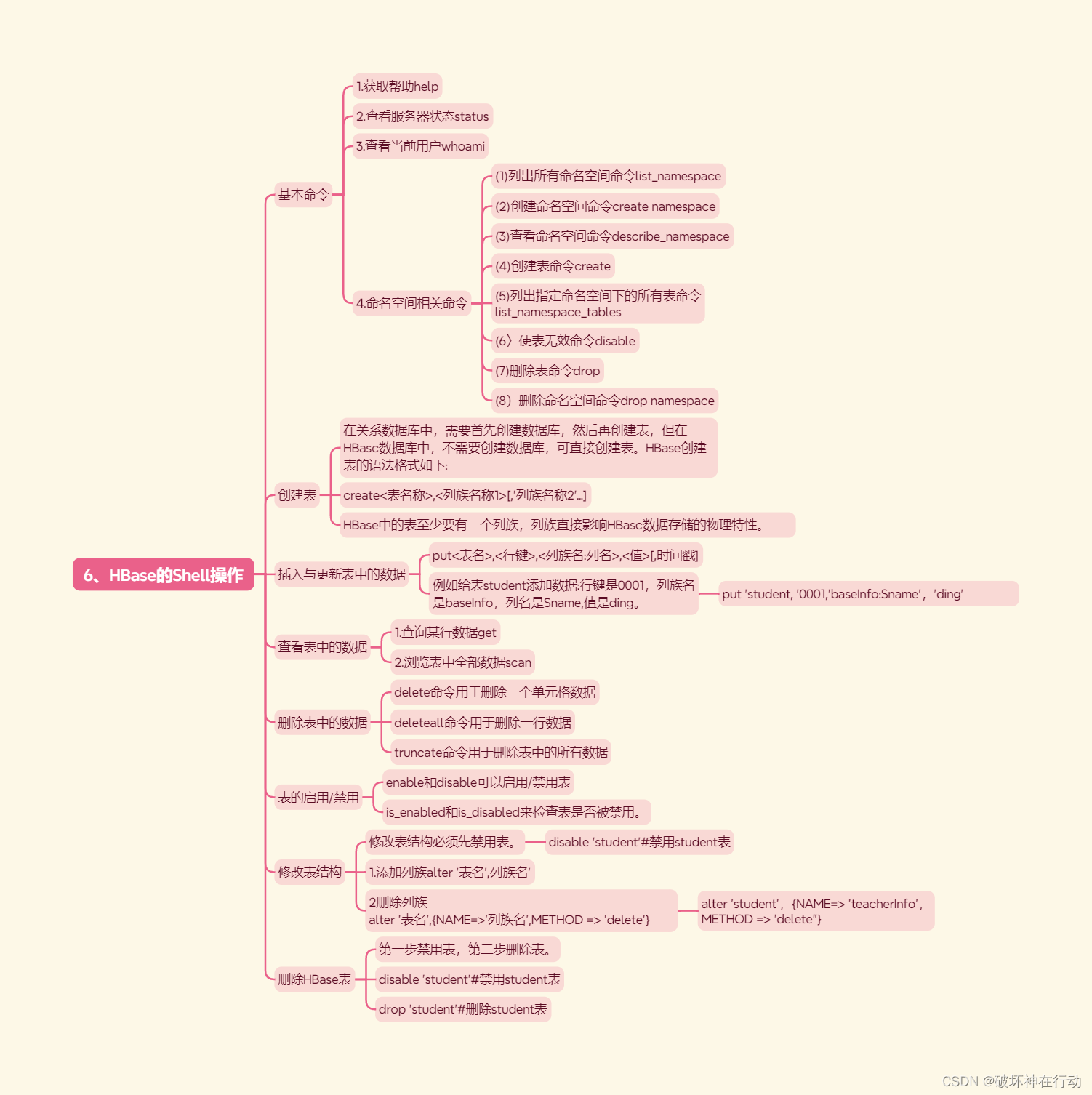
6、HBase的Shell操作
基本命令
1.获取帮助help
2.查看服务器状态status
3.查看当前用户whoami
4.命名空间相关命令
(1)列出所有命名空间命令list_namespace
(2)创建命名空间命令create namespace
(3)查看命名空间命令describe_namespace
(4)创建表命令create
(5)列出指定命名空间下的所有表命令 list_namespace_tables
(6〉使表无效命令disable
(7)删除表命令drop
(8)删除命名空间命令drop namespace
创建表
在关系数据库中,需要首先创建数据库,然后再创建表,但在HBasc数据库中,不需要创建数据库,可直接创建表。HBase创建表的语法格式如下:
create<表名称>,<列族名称1>[,'列族名称2'...]
HBase中的表至少要有一个列族,列族直接影响HBasc数据存储的物理特性。
插入与更新表中的数据
put<表名>,<行键>,<列族名:列名>,<值>[,时间戳]
例如给表student添加数据:行键是0001,列族名是baseInfo,列名是Sname,值是ding。
put 'student, '0001,'baseInfo:Sname','ding'
查看表中的数据
1.查询某行数据get
2.浏览表中全部数据scan
删除表中的数据
delete命令用于删除一个单元格数据
deleteall命令用于删除一行数据
truncate命令用于删除表中的所有数据
表的启用/禁用
enable和disable可以启用/禁用表
is_enabled和is_disabled来检查表是否被禁用。
修改表结构
修改表结构必须先禁用表。
disable 'student'#禁用student表
1.添加列族alter '表名',列族名'
2删除列族 alter '表名',{NAME=>'列族名',METHOD => 'delete'}
alter 'student',{NAME=> 'teacherInfo',METHOD => 'delete"}
删除HBase表
第一步禁用表,第二步删除表。
disable 'student’#禁用student表
drop 'student'#删除student表
7、HBase的Java API操作























![[leetcode]remove-duplicates-from-sorted-list-ii](https://img-blog.csdnimg.cn/img_convert/c29640200ef431cbe9cea81b066d6b77.jpeg)