一、介绍
1.1 背景
- 人脸检测(Face Detection)旨在从输入的图像中定位出所有人脸的位置,并以矩形框的形式进行标注。具体而言,给定一幅图像img作为输入,人脸检测算法会输出若干个矩形框的位置信息(x,y,w,h),其中(x,y)表示矩形框左上角的坐标,w和h分别代表矩形框的宽度和高度。这些矩形框将准确地框选出图像中的人脸区域。就像下图这样:

- 从领域范畴来说,人脸检测隶属于目标检测这一大类别。目标检测主要分为两大类:
- 通用目标检测,它旨在检测图像中多个不同类别的目标。例如,ILSVRC2017的VID任务需要检测200类不同的目标,而VOC2012则需要检测20类目标。其核心在于解决一个n(目标)+1(背景)=n+1的分类问题。这类检测方法通常构建的模型较大,因此在速度上稍显迟缓,鲜有顶尖的方法能够达到CPU实时处理的要求。
- 特定类别目标检测,则专注于检测图像中某一类特定的目标,比如人脸检测、行人检测或车辆检测等。其核心在于解决一个1(目标)+1(背景)=2的分类问题。这类检测方法通常设计的模型相对较小,且对速度的要求极高,确保能够满足CPU实时处理的基本需求。
1.2 现状
目前,深度学习在CV算法中占据主导地位,其研究焦点主要集中于通用目标检测。尽管这些方法在人脸检测任务上取得了良好的成效,但为何仍需深入研究这一领域呢?
- Faster-RCNN系列:对于Faster-RCNN系列而言,其显著优势在于出色的性能表现。然而,其缺点也同样明显,即运行速度较慢,即便在GPU环境下也难以实现实时检测,这与人脸检测对速度的高要求相悖。鉴于性能并非主要障碍,提升Faster-RCNN系列方法的运行效率成为了当前研究的重点。
- SSD系列:另一方面,SSD系列方法以其卓越的速度性能脱颖而出,能够在GPU环境下实现实时检测。不过,其对于密集小目标的检测能力相对较弱,而人脸恰好属于此类目标。因此,提高SSD系列在密集小目标检测方面的性能,同时保持其速度优势,成为了当前研究的重要方向。尽管GPU实时算法在应用中仍受到一定限制,但这并不妨碍我们对其潜力的深入挖掘。
此外,人脸检测领域还有特殊的级联CNN系列方法,后续将详细介绍。目前,人脸检测研究在很大程度上依赖于通用目标检测的技术基础,这是当前的事实和现状。然而,要实现速度和性能的双高要求,仍面临着不小的挑战。
1.3 常用数据集
- 人脸检测领域拥有众多的测试数据库,其中FDDB和WIDER FACE是备受瞩目的两个选择。这两个数据库均享有官方的长期维护,确保了数据的质量和时效性。因此,各种算法都会选择在这两个数据库上提交结果进行比较,以此衡量其性能优劣。与此同时,许多早期的人脸检测数据库目前已经趋于饱和,由于缺乏新的挑战和多样性,它们在算法比较方面的意义已经大打折扣。因此,选择FDDB和WIDER FACE这样的现代数据库进行人脸检测算法的测试与比较,更具实际意义和参考价值。
- 第一个是2010年非约束环境人脸检测数据库FDDB FDDB : Main:

FDDB是一个包含2845张图像的人脸检测数据库,共标注了5171个人脸。这些图像中的人脸呈现出各种非约束环境下的挑战,如复杂的面部表情、双下巴、光照变化、穿戴物品、夸张发型以及遮挡等,因此人脸检测的难度相对较大。由于其广泛的应用和认可度,FDDB已成为该领域最常用的数据库之一。
该数据库具有以下几个显著特点:- 首先,图像分辨率相对较小,所有图像的较长边均被缩放到450像素,这意味着所有图像的尺寸均小于450x450。标注的人脸中,最小尺寸达到20x20像素。同时,数据库涵盖了彩色和灰度两类图像,为算法提供了多样化的测试环境。
- 其次,每张图像中的人脸数量相对较少,平均每张图像约有1.8个人脸,绝大多数图像中仅含有一个人脸。这样的设置有助于更准确地评估算法在单个人脸检测方面的性能。
- 此外,FDDB数据集完全公开,已发表的方法通常都有相应的论文支持,并且大部分还提供了开源代码,具有较高的可靠性。这使得研究者可以方便地复现和比较各种方法。然而,对于未发表的方法,由于缺乏论文和代码,无法确认其训练集是否完全隔离,因此在比较时应持谨慎态度。
- 在测试方式上,FDDB提供了两种主要的评估方法:其他隔离数据集无限制训练再在FDDB上测试和FDDB十折交叉验证。鉴于FDDB图像数量相对较少,近年来提交的论文结果大多采用无限制训练再在FDDB上测试的方式。如果要与已发表的方法进行比较,建议遵循相同的测试方式。
- 最后,在评估指标上,FDDB提供了离散分数(discROC)和连续分数(contROC)两种。其中,discROC主要关注IoU(交并比)是否大于0.5,而contROC则希望IoU越大越好。然而,由于大多数方法都采用无限制训练加FDDB测试的方式,这可能导致检测器继承训练数据集的标注风格,从而影响contROC的评估。因此,在实际应用中,discROC通常被视为更重要的评估指标,而contROC则可作为参考。
- FDDB可以看做是资格赛,选手的正式水平请看下面的WIDER FACE。第二个是目前2016年提出的,目前难度最大的WIDER FACE WIDER FACE: A Face Detection Benchmark

WIDER FACE数据库总计包含32203张图像,其中标注了393703个人脸,堪称目前最具挑战性的数据库,其难点涵盖了尺度变化、姿态多样、遮挡情况、表情差异、化妆效果以及光照变化等多个方面。以下是该数据库的主要特点:- 首先,WIDER FACE的图像分辨率普遍较高,所有图像的宽度都被缩放到1024像素,且最小标注人脸的尺寸达到7x7像素,所有图像均为彩色。
- 其次,该数据库中每张图像的人脸数据相对较多,平均每张图像包含12.2个人脸,尤其密集的小尺寸人脸数量众多。
- 此外,WIDER FACE数据库分为训练集、验证集和测试集,分别占据40%、10%和50%的比例。特别值得一提的是,测试集的标注结果并未公开,需要提交结果给官方进行比较,这种方式确保了公平公正性,同时测试集规模庞大,使得结果的可靠性极高。
- 根据EdgeBox的检测率情况,WIDER FACE数据库还划分为Easy、Medium和Hard三个难度等级。
作为目前最常用的训练集以及最大的公开训练集,WIDER FACE的人工标注风格友好,非常适合用于训练。总体而言,WIDER FACE的难度确实非常高,其结果也极为可靠。尽管有些顶会论文没有使用WIDER FACE,但即便是在使用WIDER FACE进行训练的论文中,我们也可以看到经典方法如VJ、DPM、ACF和Faceness在这个数据库上的性能水平,从而深刻体会到其挑战性。
1.4 评价指标
人脸检测领域常用的评价指标主要包括准确率、精确率(查准率)、召回率(查全率)、F1值、IoU(交并比)、误识率(FAR)和拒识率(FRR)等。以下是每个指标对应的公式:
- 准确率 (Accuracy)
准确率是正确预测的样本数占总样本数的比例。
公式:Accuracy = (TP + TN) / (TP + FP + TN + FN)
其中:
- TP (True Positive):真正例,预测为人脸且实际为人脸。
- TN (True Negative):真反例,预测为非人脸且实际为非人脸。
- FP (False Positive):假正例,预测为人脸但实际为非人脸(误检)。
- FN (False Negative):假反例,预测为非人脸但实际为人脸(漏检)。
- 精确率 (Precision)
精确率是预测为人脸的样本中真正为人脸的比例。
公式:Precision = TP / (TP + FP) - 召回率 (Recall)
召回率是实际为人脸的样本中被正确预测为人脸的比例。
公式:Recall = TP / (TP + FN) - F1值 (F1 Score)
F1值是精确率和召回率的调和平均值。
公式:F1 Score = 2 * (Precision * Recall) / (Precision + Recall) - IoU (交并比)
IoU是预测的人脸框与真实人脸框之间的交集与并集之比。
公式:IoU = (预测框与真实框的交集面积) / (预测框与真实框的并集面积) - 误识率 (FAR, False Accept Rate)
误识率是将非人脸误判为人脸的比例。
公式:FAR = FP / (FP + TN) - 拒识率 (FRR, False Reject Rate)
拒识率是将真正的人脸误判为非人脸的比例。
公式:FRR = FN / (TP + FN)
需要注意的是,误识率和拒识率通常用于生物特征识别系统(如人脸识别)的性能评估,而在一般的人脸检测任务中可能不常用。
此外,ROC曲线和AUC值也是常用的人脸检测评价指标。ROC曲线是真正例率(TPR,即召回率)和假正例率(FPR,即误识率)之间的关系曲线。AUC值是ROC曲线下的面积,用于量化评估算法的整体性能。
这些指标可以单独使用,也可以组合使用,以全面评估人脸检测算法的性能。不同的应用场景和实际需求可能需要关注不同的指标,因此在实际应用中需要根据具体情况选择合适的评价指标。
1.5 专业术语
- Loc和conf:在人脸检测中,“loc”通常指的是边框定位(Bounding box localization),它涉及确定人脸在图像中的精确位置,即预测框(l)的位置。而“conf”通常指的是置信度(Confidence),它衡量了模型对于某个预测为人脸的区域的确定程度。
- loc:在坐标预测环节中,需格外留意的是,预测(loc)的目标并非直接定位检测对象的绝对位置,而是相对于先验框(即PriorBox)的相对位置。这包括中心点的相对偏移量以及宽高比的缩放比例。直接预测检验框的绝对位置是不切实际的。鉴于我们使用的是卷积神经网络,所有操作均基于卷积进行,而卷积神经网络的前提是空间不变性。这意味着我们使用相同的卷积核按步长遍历整幅图像,以显著降低计算复杂度。然而,正因为使用的是相同的卷积核,对于相同的特征,它会产生一致的结果。假设在图像的左上角和右下角有两辆外观相同的车辆,同一个卷积核将无法区分它们的位置,产生相同的结果。这也是为何我们需要引入先验框的原因之一,另一个原因则是我们事先并不清楚图像中存在多少个物体。
- conf:这部分涉及的是confidence预测,即对每个PriorBox的类别进行预测,与常规分类网络类似。以下是各层变换的详细说明:
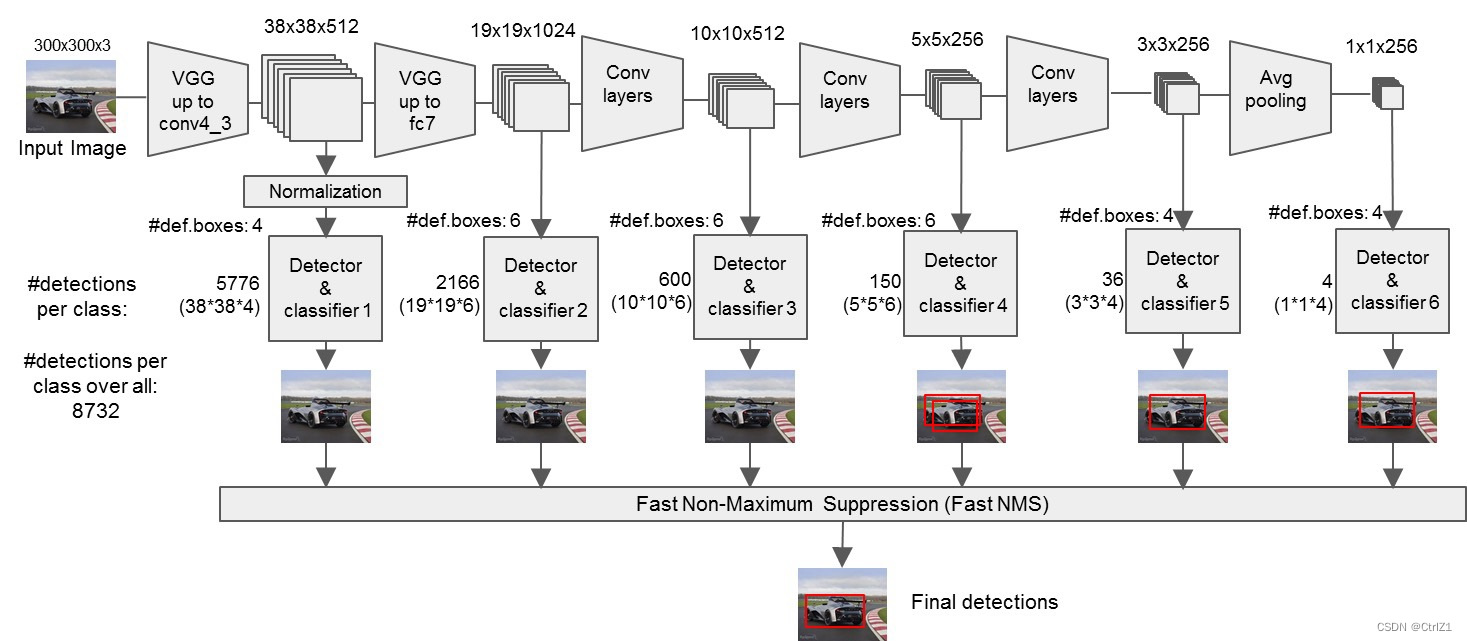
首先,conv4_3层输出尺寸为(38,38,512),conv4_3(38,38,512) -> L2 norm -> (38,38,421),由于该层靠近网络前端,其数值相对较大,因此采用L2归一化来减小数值范围。接着,该层经过变换得到(38,38,421)的输出,其中4代表每个格子内的先验框数量,即本层共有38384个先验框。关于先验框的详细解释将在后续PriorBox部分介绍。而21则代表类别总数,包括20个具体类别和1个背景类。
随后,fc7层输出尺寸为(19,19,1024),经过变换后得到(19,19,621)的输出。这里6表示每个格子内的先验框数量,因此本层共有19196个先验框。
接着,conv6_2层输出尺寸为(10,10,512),经过变换后得到(10,10,621)的输出。
然后是conv7_2层,其输出尺寸为(5,5,256),变换后得到(5,5,621)的输出。
继续到conv8_2层,其输出尺寸为(3,3,256),变换后得到(3,3,421)的输出。
最后,conv9_2层输出尺寸为(1,1,256),变换后得到(1,1,421)的输出。
通过这些变换,网络能够针对每个先验框预测其所属类别,并输出相应的confidence值。
- PriorBox:
PriorBox,又称为先验框,是在物体检测中的一个重要概念。其本质是在原图上的一系列矩形框,即特征图上的一个点根据下采样率可以得到在原图上的坐标。这些矩形框具有固定的大小和宽高比,特定尺度下只生成一组这样的框。
在物体检测过程中,首先需要生成一系列的PriorBox。例如,在SSD(Single Shot MultiBox Detector)中,PriorBox的生成利用了多层特征图。浅层特征图的感受野较小,用来检测小物体,因此设立了较小的PriorBox;而深层特征图的感受野较大,用来检测大物体,因此设立了较大的PriorBox。每个特征图上的点都会对应生成多个不同长宽比的PriorBox。
然后,通过某些网络结构(如卷积神经网络)对这些PriorBox进行分类、回归等操作。这样可以预测出每个PriorBox的类别以及位置偏移量,从而得到最终的检测结果。
PriorBox的生成方法可以根据具体的应用场景和算法需求进行调整。例如,通过调整缩放系数和宽高比系数,可以生成不同大小和形状的PriorBox,以适应不同尺度和形状的物体检测任务。
总的来说,PriorBox在物体检测中起到了至关重要的作用,它提供了一种有效的方式来初始化检测框,从而提高检测精度和效率。
举个例子:
SSD的主要步骤如下:
- 首先,输入一幅尺寸为300x300的图片,该图片被传递给预先训练好的分类网络,这个网络基于改进的VGG16架构,用于提取不同大小的特征映射。
- 随后,从Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2这些特定的网络层中抽取特征映射(即feature map)。接着,在这些feature map的每一个位置上,构造出6个不同尺度的默认边界框(Default boxes)。之后,对这些Default boxes进行检测和分类,初步筛选出符合条件的候选框。
prior box 是干嘛的呢?其实非常类似于Faster R-CNN中的Anchors,就是候选框,这种候选框的选取不需要像R-CNN那样通过复杂处理产生。在ssd中,priorbox层只需要bottom层feature map的大小,就可以给出候选框。假设输入的feature map大小是W×H,生成的prior box中心就有W×H个,均匀分布在整张图上。在每个中心上,可以生成多个不同长宽比的prior box,如[1/3, 1/2, 1, 2, 3],每个点就可以生成length_of_aspect_ratio个框,所以在一个feature map上可以生成的prior box总数是W×H×length_of_aspect_ratio。所以简单来说feature map上每个点的中点为中心(offset=0.5),生成一些列同心的prior box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置) - 最后,将来自不同feature map的Default boxes进行合并,并通过非极大值抑制(NMS)算法去除一部分重叠或错误的边界框,从而得到最终的Default boxes集合,即为我们所需的检测结果。