一、问题描述:
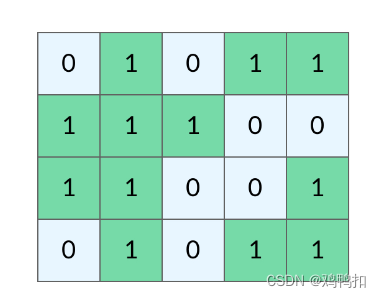
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 :
输入:grid = [
[“1”,“1”,“1”,“1”,“0”],
[“1”,“1”,“0”,“1”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“0”,“0”,“0”]
]
输出:1
二、深度优先搜索(DFS)来计算岛屿数量:
- 深度优先就是沿着一条路径尽可能深地探索,直到到达一个叶子节点(即没有未访问过的邻居节点了),然后回溯到上一个节点,继续探索其他分支,直到所有的节点都被访问过为止!!!
- 具体步骤如下:
①遍历二维网格中的每个点。
②对于每个点,如果该点的值为 ‘1’,表示这是一个岛屿的一部分,将岛屿数量加1,并使用深度优先搜索(DFS)函数将与该点相连的所有 ‘1’ 修改为 ‘0’,表示这些点已经被访问过,属于同一个岛屿。
③深度优先搜索函数 dfs:该函数用于将与当前岛屿相连的所有 ‘1’ 修改为 ‘0’,表示已经访问过。
首先进行边界条件判断,包括是否越界和当前点是否为海洋(值为 ‘0’)。
如果当前点满足条件,则将其标记为已访问过(值修改为 ‘0’)。
然后递归调用 dfs 函数,分别对当前点的上、下、左、右四个方向进行搜索,直到所有与当前岛屿相连的 ‘1’ 都被标记为 ‘0’。
④继续遍历剩余的未访问过的点,重复上述步骤,直到所有点都被访问过为止。 - 代码示例:
class Solution {
// 主函数,用于计算岛屿数量
public int numIslands(char[][] grid) {
int result = 0; // 初始化岛屿数量为0
// 遍历二维网格中的每个点
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(grid[i][j] == '1') { // 如果该点为 '1',表示发现了一个岛屿的一部分
result++; // 增加岛屿数量
dfs(grid, i, j); // 对该岛屿进行深度优先搜索
}
}
}
return result; // 返回岛屿数量
}
// 深度优先搜索函数,用于将与当前岛屿相连的所有 '1' 修改为 '0'
public void dfs(char[][] grid, int i, int j) {
// 边界条件判断以及当前点是否为岛屿的一部分判断
if(i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == '0') return;
grid[i][j] = '0'; // 将当前点标记为已访问过
// 对当前点的上、下、左、右四个方向进行深度优先搜索
dfs(grid, i - 1, j);
dfs(grid, i + 1, j);
dfs(grid, i, j - 1);
dfs(grid, i, j + 1);
}
}
- 时间复杂度分析:遍历整个二维网格的时间复杂度为 O(m * n)。
对于每个 ‘1’ 点,进行深度优先搜索的时间复杂度为 O(m * n),因为最坏情况下可能需要遍历整个网格。 因此,总的时间复杂度为 O(m * n * m * n),即 O(m^2 * n^2)。
三、广度优先搜索(BFS)来计算岛屿的数量:
- 广度优先是按层遍历的方式,从起始节点开始,逐层向外扩散搜索。具体来说,广度优先搜索会先访问起始节点的所有邻居节点,然后再依次访问这些邻居节点的邻居节点,依次类推,直到搜索到目标节点或者所有节点都被访问过为止。
- 具体步骤如下:
①首先,定义了一个二维数组 visited 用于记录每个位置是否被访问过。
②然后,遍历整个二维网格 grid,对于每个未被访问过的陆地点 ‘1’,将其作为一个岛屿的起始点。
③在 bfs 方法中,使用队列 q 进行广度优先搜索,从起始点开始向外扩展,每次扩展到的点如果是未被访问过的陆地点 ‘1’,则将其标记为已访问,并将其加入队列中继续扩展。
④搜索过程中,通过四个方向上的移动数组 move 进行上下左右移动,判断新位置是否在网格范围内,以及是否为未被访问过的陆地点 ‘1’。 - 代码示例:
class Solution {
boolean[][] visited;
int[][] move = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
public int numIslands(char[][] grid) {
visited = new boolean[grid.length][grid[0].length];
int result = 0;
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(grid[i][j] == '1' && visited[i][j] == false) { //找到一个中心点
result++;
bfs(grid, i, j); //向外搜索,并把访问过的位置记录下来
}
}
}
return result;
}
public void bfs(char[][] grid, int x, int y) {
Deque<int[]> q = new ArrayDeque<>();
q.offer(new int[]{x, y});
visited[x][y] = true;
while(!q.isEmpty()) {
int[] cur = q.poll();
for(int i = 0; i < 4; i++){
int curx = cur[0] + move[i][0];
int cury = cur[1] + move[i][1];
if(curx < 0 || curx == grid.length || cury < 0 || cury == grid[0].length ) continue;
if(grid[curx][cury] == '1' && visited[curx][cury] == false){
//System.out.println(curx + " " + cury);
visited[curx][cury] = true;
q.offer(new int[]{curx, cury});
}
}
}
}
}
- 时间复杂度分析:在最坏情况下,需要遍历整个二维网格中的每个点,时间复杂度为 O(m * n),其中 m 为网格的行数,n 为网格的列数。
在每次广度优先搜索过程中,最多会访问到每个点一次,因此搜索过程的时间复杂度也为 O(m * n)。
综合起来,总的时间复杂度为 O(m * n)。
四、BFS和DFS的总结:
广度优先搜索(BFS)和深度优先搜索(DFS)是两种常用的图搜索算法,用于解决许多与图相关的问题,包括路径搜索、连通性检测等。
(1)广度优先搜索(BFS):
广度优先搜索从起始顶点开始,逐层遍历图中的节点。具体来说,它先访问起始顶点的所有邻居节点,然后依次访问这些邻居节点的邻居节点,以此类推,直到所有可达节点都被访问到。
在搜索过程中,通常使用队列(Queue)来保存待访问的节点,确保按照层级顺序进行遍历。
在广度优先搜索中,每一层的节点都会在同一时间被访问,因此可以确保在搜索过程中按照从起始节点到目标节点的最短路径顺序进行搜索。这也是为什么广度优先搜索常用于解决最短路径问题,例如在无权图中找到两个节点之间的最短路径!!!
(2)深度优先搜索(DFS):
深度优先搜索从起始顶点开始,沿着一条路径一直深入直到不能再继续为止,然后回溯到上一个节点,继续探索下一个未被访问的路径。它会沿着一条路径尽可能深地探索,直到到达终点或者不能再继续为止。
在搜索过程中,通常使用栈(Stack)来保存待访问的节点,确保优先访问最近被发现的节点。
DFS适用于解决寻找路径、拓扑排序、连通性检测等问题,因为它能够快速地深入搜索整个图!!!
(3)二者比较:
①BFS通常需要使用额外的空间来保存待访问的节点,因为它需要按照层级顺序遍历图。而DFS通常只需要保存当前路径上的节点,空间复杂度较低。
②BFS保证找到的路径是最短路径,而DFS找到的路径可能不是最短路径,但它能够快速地遍历整个图。
③在空间允许的情况下,优先选择BFS,特别是在需要找到最短路径的情况下。而DFS则更适合在空间有限的情况下,或者需要遍历整个图的情况下使用。