文章目录
爬虫的本质:模拟对应的App,浏览器访问对应的地址获取到数据
1、下载图片示例1:使用 .urlretrieve() 函数
urlretrieve() 方法直接将远程数据下载到本地。下面我们再来看看 urllib 模块提供的 urlretrieve() 函数。
Help on function urlretrieve in module urllib:
urlretrieve(url, filename=None, reporthook=None, data=None)
import requests
from lxml import etree
from urllib import request
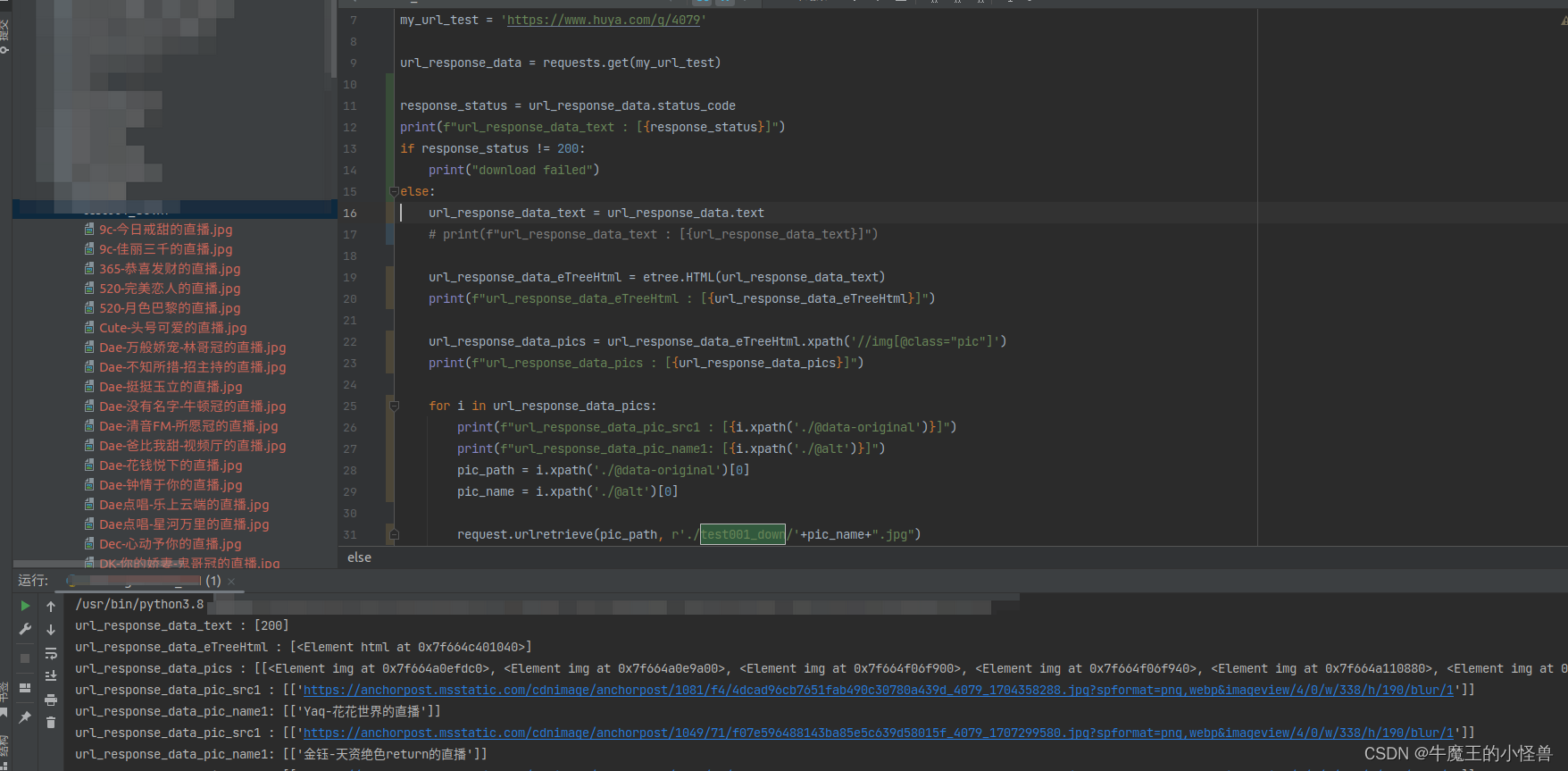
my_url_test = 'https://www.huya.com/g/4079'
url_response_data = requests.get(my_url_test)
response_status = url_response_data.status_code
print(f"url_response_data_text : [{response_status}]")
if response_status != 200: # 应答码为200,表示:查询成功
print("download failed")
else:
# 通过.text 可以获取到当前网页 返回的一手数据
url_response_data_text = url_response_data.text
# print(f"url_response_data_text : [{url_response_data_text}]")
# 通过 .HTML 可以对原始数据进行清洗(解析)
url_response_data_eTreeHtml = etree.HTML(url_response_data_text)
print(f"url_response_data_eTreeHtml : [{url_response_data_eTreeHtml}]")
# 通过 .xpath() 函数,可以从一手数据中筛选所有以 img class=‘pic‘开头的图片代码块
url_response_data_pics = url_response_data_eTreeHtml.xpath('//img[@class="pic"]')
print(f"url_response_data_pics : [{url_response_data_pics}]")
for i in url_response_data_pics:
print(f"url_response_data_pic_src1 : [{i.xpath('./@data-original')}]")
print(f"url_response_data_pic_name1: [{i.xpath('./@alt')}]")
pic_path = i.xpath('./@data-original')[0]
pic_name = i.xpath('./@alt')[0]
# 下载到本地
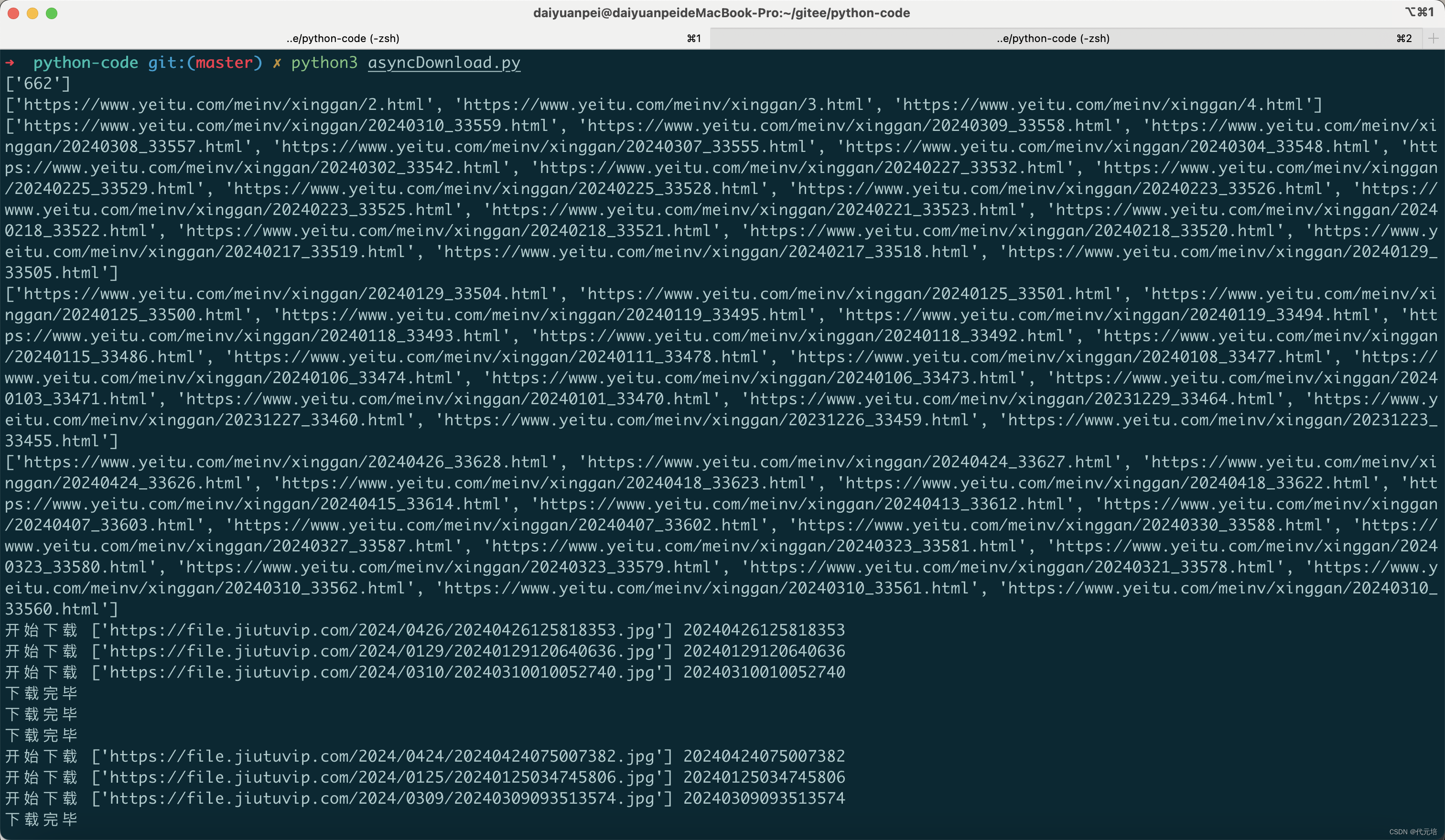
request.urlretrieve(pic_path, r'./test001_down/'+pic_name+".jpg")
运行结果:
2、下载图片示例2 - 使用 open/write 函数
from lxml import etree
import requests
import os
if __name__=="__main__":
url='https://pic.netbian.com/4kyouxi/'
headers={
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'
}
response=requests.get(url=url,headers=headers)
response.encoding='gbk'#图片名称乱码时的处理方式
page_text=response.text
tree=etree.HTML(page_text)
li_list=tree.xpath('//div[@class="slist"]/ul/li')
if not os.path.exists('./4K游戏'):
os.mkdir('./4K游戏')
for li in li_list:
img_src='http://pic.netbian.com'+li.xpath('./a/img/@src')[0]
img_name=li.xpath('./a/img/@alt')[0]+'.jpg'
img_data=requests.get(url=img_src,headers=headers).content
img_path='4K游戏/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,"下载成功")
在 Python 中使用文件的关键函数是 open() 函数。
open() 函数有两个参数:文件名和模式。
有四种打开文件的不同方法(模式):
- “r” - 读取 - 默认值。打开文件进行读取,如果文件不存在则报错。
- “a” - 追加 - 打开供追加的文件,如果不存在则创建该文件。
- “w” - 写入 - 打开文件进行写入,如果文件不存在则创建该文件。
- “x” - 创建 - 创建指定的文件,如果文件存在则返回错误。
此外,您可以指定文件是应该作为二进制还是文本模式进行处理。
- “t” - 文本 - 默认值。文本模式。
- “b” - 二进制 - 二进制模式(例如图像)。
 虽然 open 函数也能实现文件的下载保存,但不建议使用IO操作,容易出现问题, for循环执行效率要快于with open的效率。
虽然 open 函数也能实现文件的下载保存,但不建议使用IO操作,容易出现问题, for循环执行效率要快于with open的效率。
3、下载图片示例3
3.1 使用 open/write 下载
from lxml import etree
import requests
from urllib import request
url = 'http://www.haoduanzi.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
}
url_content = requests.get(url, headers=headers).text
tree = etree.HTML(url_content)
div_list = tree.xpath('//div[@id="main"]/div')[2:-1]
i = 0
for div in div_list:
img_url = div.xpath('./div/img/@src')[0]
img_content = requests.get(url=img_url, headers=headers).content
request.urlretrieve(url=img_url, filename='img' + str(i) + '.jpg')
i += 1
3.2 使用 urlretrieve下载
from lxml import etree
import requests
from uuid import uuid4
import time
from urllib import request
url = 'http://www.haoduanzi.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
}
url_content = requests.get(url, headers=headers).text
tree = etree.HTML(url_content)
div_list = tree.xpath('//div[@id="main"]/div')[2:-1]
filename = uuid4()
# i = 0
for div in div_list:
img_url = div.xpath('./div/img/@src')[0]
img_content = requests.get(url=img_url, headers=headers).content
# request.urlretrieve(url=img_url, filename='img' + str(i) + '.jpg')
# i += 1
time.sleep(2)
with open(r'C:\jupyter\day02\%s.jpg' % filename, 'wb') as f:
f.write(img_content)