StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis
StyleNeRF:一个基于样式的3D感知生成器,用于高分辨率图像合成
顾家涛 † ,刘玲杰 ‡ ,王鹏 ⋄ ,克里斯蒂安·西奥博尔特 ‡
†Facebook AI ‡Max Planck Institute for Informatics ⋄The University of Hong Kong
† Facebook AI ‡ 马克斯·普朗克信息学研究所 ⋄ 香港大学
†jgu@fb.com ‡{lliu,theobalt}@mpi-inf.mpg.de ⋄pwang3@cs.hku.hk
† jgu@fb.com ‡ {lliu,theobalt}@ mpi-inf. mpg. de ⋄ pwang3@cs.hku.hk
corresponding author. 通讯作者
Abstract 摘要
We propose StyleNeRF, a 3D-aware generative model for photo-realistic high-resolution image synthesis with high multi-view consistency, which can be trained on unstructured 2D images. Existing approaches either cannot synthesize high-resolution images with fine details or yield noticeable 3D-inconsistent artifacts. In addition, many of them lack control over style attributes and explicit 3D camera poses. StyleNeRF integrates the neural radiance field (NeRF) into a style-based generator to tackle the aforementioned challenges, i.e., improving rendering efficiency and 3D consistency for high-resolution image generation. We perform volume rendering only to produce a low-resolution feature map and progressively apply upsampling in 2D to address the first issue. To mitigate the inconsistencies caused by 2D upsampling, we propose multiple designs, including a better upsampler and a new regularization loss. With these designs, StyleNeRF can synthesize high-resolution images at interactive rates while preserving 3D consistency at high quality. StyleNeRF also enables control of camera poses and different levels of styles, which can generalize to unseen views. It also supports challenging tasks, including zoom-in and-out, style mixing, inversion, and semantic editing.11Please check our video at: StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis.
请查看我们的视频:http://jiataogu.me/style_nerf/。[2110.08985] StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis
我们提出了StyleNeRF,这是一个3D感知的生成模型,用于具有高多视图一致性的照片级逼真的高分辨率图像合成,可以在非结构化的2D图像上进行训练。现有的方法要么不能合成具有精细细节的高分辨率图像,要么产生明显的3D不一致伪影。此外,它们中的许多缺乏对样式属性和明的3D相机姿势的控制。StyleNeRF将神经辐射场(NeRF)集成到基于样式的生成器中,以解决上述挑战,即,提高渲染效率和3D一致性,以生成高分辨率图像。我们只执行体渲染来生成低分辨率的特征图,并逐步在2D中应用上采样来解决第一个问题。为了减轻2D上采样引起的不一致性,我们提出了多种设计,包括更好的上采样器和新的正则化损失。 通过这些设计,StyleNeRF可以以交互速率合成高分辨率图像,同时保持高质量的3D一致性。StyleNeRF还可以控制相机姿势和不同级别的样式,这可以概括为不可见的视图。它还支持具有挑战性的任务,包括放大和缩小,样式混合,反转和语义编辑。 1
1Introduction 1介绍
Figure 1:Synthesized 10242 images by StyleNeRF, with the corresponding low-resolution feature maps. StyleNeRF can generate photo-realistic high-resolution images from novel views at interactive rates while preserving high 3D consistency. None of existing methods can achieve both features.
图1:StyleNeRF合成的 10242 图像,以及相应的低分辨率特征图。StyleNeRF可以从新颖的视图以交互速率生成照片般逼真的高分辨率图像,同时保持高3D一致性。现有的方法都不能实现这两个特征。
Photo-realistic free-view image synthesis of real-world scenes is a long-standing problem in computer vision and computer graphics. Traditional graphics pipeline requires production-quality 3D models, computationally expensive rendering, and manual work, making it challenging to apply to large-scale image synthesis for a wide range of real-world scenes. In the meantime, Generative Adversarial Networks (GANs, Goodfellow et al., 2014) can be trained on a large number of unstructured images to synthesize high-quality images. However, most GAN models operate in 2D space. Therefore, they lack the 3D understanding of the training images, which results in their inability to synthesize images of the same 3D scene with multi-view consistency. They also lack direct 3D camera control over the generated images.
真实世界场景的真实感自由视角图像合成是计算机视觉和计算机图形学中的一个长期问题。传统的图形管道需要生产质量的3D模型,计算昂贵的渲染和手工工作,这使得它具有挑战性,适用于大规模图像合成的广泛的现实世界的场景。与此同时,生成对抗网络(GANs,Goodfellow等人,2014)可以在大量非结构化图像上训练,以合成高质量的图像。然而,大多数GAN模型在2D空间中运行。因此,他们缺乏对训练图像的3D理解,这导致他们无法合成具有多视图一致性的相同3D场景的图像。它们也缺乏对生成图像的直接3D相机控制。
Natural images are the 2D projection of the 3D world. Hence, recent works on generative models (Schwarz et al., 2020; Chan et al., 2021) enforce 3D structures by incorporating a neural radiance field (NeRF, Mildenhall et al., 2020). However, these methods cannot synthesize high-resolution images with delicate details due to the computationally expensive rendering process of NeRF. Furthermore, the slow rendering process leads to inefficient training and makes these models unsuitable for interactive applications. GIRAFFE (Niemeyer & Geiger, 2021b) combines NeRF with a CNN-based renderer, which has the potential to synthesize high-resolution images. However, this method falls short of 3D-consistent image generation and so far has not shown high-resolution results.
自然图像是3D世界的2D投影。因此,最近关于生成模型的工作(施瓦茨et al.,2020; Chan等人,2021)通过结合神经辐射场(NeRF,Mildenhall等人,2020年)。然而,由于NeRF的计算昂贵的渲染过程,这些方法不能合成具有精细细节的高分辨率图像。此外,缓慢的渲染过程导致低效的训练,使这些模型不适合交互式应用程序。GIRAFFE(Niemeyer &盖革,2021 b)将NeRF与基于CNN的渲染器相结合,具有合成高分辨率图像的潜力。然而,这种方法福尔斯达不到3D一致的图像生成,并且到目前为止还没有显示出高分辨率的结果。
We propose StyleNeRF, a new 3D-aware generative model for high-resolution 3D consistent image synthesis at interactive rates. It also allows control of the 3D camera pose and enables control of specific style attributes. StyleNeRF incorporates 3D scene representations into a style-based generative model. To prevent the expensive direct color image rendering from the original NeRF approach, we only use NeRF to produce a low-resolution feature map and upsample it progressively to high resolution. To improve 3D consistency, we propose several designs, including a desirable upsampler that achieves high consistency while mitigating artifacts in the outputs, a novel regularization term that forces the output to match the rendering result of the original NeRF and fixing the issues of view direction condition and noise injection. StyleNeRF is trained using unstructured real-world images. A progressive training strategy significantly improves the stability of learning real geometry.
我们提出了StyleNeRF,一个新的3D感知生成模型的高分辨率3D一致的图像合成在交互式速率。它还允许控制3D摄影机姿势,并允许控制特定的样式属性。StyleNeRF将3D场景表示纳入基于样式的生成模型。为了避免原始NeRF方法中昂贵的直接彩色图像渲染,我们只使用NeRF来生成低分辨率的特征图,并将其逐步上采样到高分辨率。为了提高3D一致性,我们提出了几种设计,包括一个理想的上采样器,实现高一致性,同时减轻输出中的伪影,一个新的正则化项,迫使输出匹配原始NeRF的渲染结果,并修复视图方向条件和噪声注入的问题。StyleNeRF使用非结构化的真实世界图像进行训练。渐进式训练策略显著提高了学习真实的几何的稳定性。
We evaluate StyleNeRF on various challenging datasets. StyleNeRF can synthesize photo-realistic 10242 images at interactive rates while achieving high multi-view consistency. None of the existing methods can achieve both characteristics. Additionally, StyleNeRF enables direct control on styles, and 3D camera poses even for the poses starkly different from training and supports applications including style mixing, interpolation, inversion, and semantic editing.
我们在各种具有挑战性的数据集上评估StyleNeRF。StyleNeRF可以以交互速率合成照片级逼真的 10242 图像,同时实现高多视图一致性。现有的方法都不能同时实现这两个特性。此外,StyleNeRF可以直接控制样式和3D相机姿势,即使姿势与训练完全不同,并支持包括样式混合,插值,反转和语义编辑在内的应用程序。
2Related Work 2相关工作
Neural Implicit Fields 神经内隐场
Representing 3D scenes as neural implicit fields has increasingly gained much attention. Michalkiewicz et al. (2019); Mescheder et al. (2019); Park et al. (2019); Peng et al. (2020) predict neural implicit fields with 3D supervision. Some of them (Sitzmann et al., 2019; Niemeyer et al., 2019) assume that the ray color only lies on the geometry surface and propose differentiable renderers to learn a neural implicit surface representation. NeRF and its variants (Mildenhall et al., 2020; Liu et al., 2020; Zhang et al., 2020) utilize a volume rendering technique to render neural implicit volume representations for novel view synthesis. In this work, we propose a generative variant of NeRF (Mildenhall et al., 2020). Unlike the discussed methods, which require posed multi-view images, our approach only needs unstructured single-view images for training.
将3D场景表示为神经隐式场越来越受到人们的关注。Michalkiewicz et al.(2019); Mescheder et al.(2019); Park et al.(2019); Peng et al.(2020)用3D监督预测神经内隐场。其中一些(Sitzmann等人,2019; Niemeyer等人,2019)假设光线颜色仅位于几何表面上,并提出可微分渲染器来学习神经隐式表面表示。NeRF及其变体(Mildenhall等人,2020; Liu等人,2020; Zhang等人,2020)利用体绘制技术来绘制用于新颖视图合成的神经隐式体表示。在这项工作中,我们提出了NeRF的生成变体(Mildenhall等人,2020年)。与所讨论的方法不同,这些方法需要多视图图像,我们的方法只需要非结构化的单视图图像进行训练。
Image Synthesis with GANs
使用GANs进行图像合成
Starting from Goodfellow et al. (2014), GANs have demonstrated high-quality results (Durugkar et al., 2017; Mordido et al., 2018; Doan et al., 2019; Zhang et al., 2019; Brock et al., 2018; Karras et al., 2018). StyleGANs (Karras et al., 2019; 2020b) achieve SOTA quality and support different levels of style control. Karras et al. (2021) solve the “texture sticking” problem of 2D GANs in generating animations with 2D transformations. Some methods (Härkönen et al., 2020; Tewari et al., 2020a; Shen et al., 2020; Abdal et al., 2020; Tewari et al., 2020b; Leimkühler & Drettakis, 2021; Shoshan et al., 2021) leverage disentangled properties in the latent space to enable explicit controls, most of which focus on faces. While these methods can synthesize face poses parameterized by two angles, extending them to general objects and controlling 3D cameras is not easy. Chen et al. (2021a) proposed to generate segmentation maps from implicit fields to enable 3D control. However, it requires 3D meshes for pre-training. In contrast, our work can synthesize images for general objects, enabling explicit 3D camera control.
从Goodfellow等人(2014)开始,GAN已经证明了高质量的结果(Durugkar等人,2017; Mordido等人,2018;多安等人,2019年; Zhang等人,2019; Brock等人,2018; Karras等人,2018年)。StyleGANs(Karras等人,2019年; 2020年b)实现SOTA质量并支持不同级别的风格控制。Karras等人(2021)解决了2D GAN在生成2D变换动画时的“纹理粘连”问题。一些方法(Härkönen等人,2020; Tewari等人,2020 a; Shen等人,2020; Abdal等人,2020; Tewari等人,2020 b; Leimkühler & Drettakis,2021; Shoshan等人,2021)利用潜在空间中的解纠缠属性来实现显式控制,其中大部分集中在面部。虽然这些方法可以合成由两个角度参数化的人脸姿态,但将它们扩展到一般对象并控制3D相机并不容易。Chen等人(2021 a)提出从隐式字段生成分割图以实现3D控制。 但是,它需要3D网格进行预训练。相比之下,我们的工作可以合成一般物体的图像,从而实现显式的3D相机控制。
3D-Aware GANs 3D感知GAN
Recently, neural scene representations have been integrated into 2D generative models to enable direct camera control. Voxel-based GANs (Henzler et al., 2019; Nguyen-Phuoc et al., 2019; 2020) lack fine details in the results due to the voxel resolution restriction. Radiance fields-based methods (Schwarz et al., 2020; Chan et al., 2021) have higher quality and better 3D consistency but have difficulties training for high-resolution images (5122 and beyond) due to the expensive rendering process of radiance fields. GIRAFFE (Niemeyer & Geiger, 2021b) improved the training and rendering efficiency by combining NeRF with a ConvNet-based renderer. However, it produced severe view-inconsistent artifacts due to its particular network designs (e.g. 3×3 Conv, upsampler). In contrast, our method can effectively preserve view consistency in image synthesis.
最近,神经场景表示已被集成到2D生成模型中,以实现直接的相机控制。基于体素的GAN(Henzler等人,2019年; Nguyen-Bauoc等人,2019; 2020)由于体素分辨率限制,结果中缺乏精细细节。基于辐射场的方法(施瓦茨等人,2020; Chan等人,2021)具有更高的质量和更好的3D一致性,但由于辐射场的昂贵渲染过程,难以训练高分辨率图像( 5122 和更高)。GIRAFFE(Niemeyer &盖革,2021 b)通过将NeRF与基于ConvNet的渲染器相结合,提高了训练和渲染效率。然而,由于其特殊的网络设计(例如 3×3 Conv,上采样器),它产生了严重的视图不一致的伪影。相比之下,我们的方法可以有效地保持视图的一致性,在图像合成。
3Method 3方法
3.1Image synthesis as neural implicit field rendering
3.1神经隐场绘制的图像合成
Style-based Generative Neural Radiance Field
基于样式的生成式神经辐射场
We start by modeling a 3D scene as neural radiance field (NeRF, Mildenhall et al., 2020). It is typically parameterized as multilayer perceptrons (MLPs), which takes the position 𝒙∈ℝ3 and viewing direction 𝒅∈𝕊2 as input, and predicts the density �(𝒙)∈ℝ+ and view-dependent color 𝒄(𝒙,𝒅)∈ℝ3. To model high-frequency details, follwing NeRF (Mildenhall et al., 2020), we map each dimension of 𝒙 and 𝒅 with Fourier features :
我们通过将3D场景建模为神经辐射场(NeRF,Mildenhall等人,2020年)。它通常被参数化为多层感知器(MLP),其将位置 𝒙∈ℝ3 和观看方向 𝒅∈𝕊2 作为输入,并预测密度 �(𝒙)∈ℝ+ 和视图相关颜色 𝒄(𝒙,𝒅)∈ℝ3 。为了对高频细节进行建模,遵循NeRF(Mildenhall等人,2020),我们用傅立叶特征映射 𝒙 和 𝒅 的每个维度:
| ��(�)=[sin(20�),cos(20�),…,sin(2�−1�),cos(2�−1�)] | (1) |
We formalize StyleNeRF representations by conditioning NeRF with style vectors 𝒘 as follows:
我们通过用样式向量 𝒘 调节NeRF来形式化StyleNeRF表示,如下所示:
| �𝒘�(𝒙)=�𝒘�∘�𝒘�−1∘…∘�𝒘1∘�(𝒙),where𝒘=�(𝒛),𝒛∈𝒵 | (2) |
Similar as StyleGAN2 (Karras et al., 2020b), � is a mapping network that maps noise vectors from the spherical Gaussian space 𝒵 to the style space 𝒲; �𝒘�(.) is the �th layer MLP whose weight matrix is modulated by the input style vector 𝒘. �𝒘�(𝒙) is the �-th layer feature of that point. We then use the extracted features to predict the density and color, respectively:
类似于StyleGAN 2(Karras等人, � 是将噪声向量从球面高斯空间 𝒵 映射到风格空间 𝒲 的映射网络; �𝒘�(.) 是其权重矩阵由输入风格向量 𝒘 调制的 �th 层MLP。 �𝒘�(𝒙) 是该点的第 � 层特征。然后,我们使用提取的特征分别预测密度和颜色:
| �𝒘(𝒙)=ℎ�∘�𝒘��(𝒙),𝒄𝒘(𝒙,𝒅)=ℎ�∘[�𝒘��(𝒙),�(𝒅)], | (3) |
where ℎ� and ℎ� can be a linear projection or 2-layer MLPs. Different from the original NeRF, we assume ��>�� for Equation 3 as the visual appearance generally needs more capacity to model than the geometry. The first min(��,��) layers are shared in the network.
其中 ℎ� 和 ℎ� 可以是线性投影或2层MLP。与原始NeRF不同,我们假设公式3为 ��>�� ,因为视觉外观通常需要比几何形状更多的建模能力。前 min(��,��) 层在网络中共享。
Volume Rendering 体绘制
Image synthesis is modeled as volume rendering from a given camera pose 𝒑∈𝒫. For simplicity, we assume a camera is located on the unit sphere pointing to the origin with a fixed field of view (FOV). We sample the camera’s pitch & yaw from a uniform or Gaussian distribution depending on the dataset. To render an image �∈ℝ�×�×3, we shoot a camera ray 𝒓(�)=𝒐+�𝒅 (𝒐 is the camera origin) for each pixel, and then calculate the color using the volume rendering equation:
图像合成被建模为来自给定相机姿势 𝒑∈𝒫 的体积渲染。为了简单起见,我们假设相机位于指向原点的单位球体上,具有固定的视场(FOV)。我们根据数据集从均匀或高斯分布中对相机的俯仰和偏航进行采样。为了渲染图像 �∈ℝ�×�×3 ,我们为每个像素拍摄相机光线 𝒓(�)=𝒐+�𝒅 ( 𝒐 是相机原点),然后使用体积渲染公式计算颜色:
| �𝒘NeRF(𝒓)=∫0∞�𝒘(�)𝒄𝒘(𝒓(�),𝒅)𝑑�,where�𝒘(�)=exp(−∫0��𝒘(𝒓(�))𝑑�)⋅�𝒘(𝒓(�)) | (4) |
In practice, the above equation is discretized by accumulating sampled points along the ray. Following NeRF (Mildenhall et al., 2020), stratified and hierarchical sampling are applied for more accurate discrete approximation to the continuous implicit function.
实际上,通过沿射线沿着累积采样点来离散上述方程。在NeRF(Mildenhall等人,2020),分层和分层抽样应用于更准确的离散逼近连续隐式函数。
Challenges 挑战
Compared to 2D generative models (e.g., StyleGANs (Karras et al., 2019; 2020b)), the images generated by NeRF-based models have 3D consistency, which is guaranteed by modeling the image synthesis as a physics process, and the neural 3D scene representation is invariant across different viewpoints. However, the drawbacks are apparent: these models cost much more computation to render an image at the exact resolution. For example, 2D GANs are 100∼1000 times more efficient to generate a 10242 image than NeRF-based models. Furthermore, NeRF consumes much more memory to cache the intermediate results for gradient back-propagation during training, making it difficult to train on high-resolution images. Both of these restrict the scope of applying NeRF-based models in high-quality image synthesis, especially at the training stage when calculating the objective function over the whole image is crucial.
与2D生成模型(例如,StyleGANs(Karras等人,二〇一九年; 2020 b)),由基于NeRF的模型生成的图像具有3D一致性,这通过将图像合成建模为物理过程来保证,并且神经3D场景表示在不同视点之间是不变的。然而,缺点是显而易见的:这些模型花费更多的计算来以精确的分辨率渲染图像。例如,2D GAN生成 10242 图像的效率是基于NeRF模型的 100∼1000 倍。此外,NeRF在训练期间消耗更多的内存来缓存梯度反向传播的中间结果,这使得难以在高分辨率图像上进行训练。这两者都限制了基于NeRF的模型在高质量图像合成中的应用范围,特别是在训练阶段,计算整个图像的目标函数至关重要。
3.2Approximation for high-resolution image generation
3.2用于高分辨率图像生成的近似
In this section, we propose how to improve the efficiency of StyleNeRF by taking inspiration from 2D GANs. We observe that the image generation of 2D GANs (e.g., StyleGANs) is fast due to two main reasons: (1) each pixel only takes single forward pass through the network; (2) image features are generated progressively from coarse to fine, and the feature maps with higher resolutions typically have a smaller number of channels to save memory.
在本节中,我们将提出如何通过从2D GAN中获得灵感来提高StyleNeRF的效率。我们观察到2D GAN的图像生成(例如,StyleGANs)之所以快速,主要有两个原因:(1)每个像素只需要通过网络进行一次前向传递;(2)图像特征是从粗到细逐步生成的,分辨率较高的特征图通常具有较少的通道数以节省保存内存。
In StyleNeRF, the first point can be partially achieved by early aggregating the features into the 2D space before the final colors are computed. In this way, each pixel is assigned with a feature vector, Furthermore, it only needs to pass through a network once rather than calling the network multiple times for all sampled points on the ray as NeRF does. We approximate Equation 4 as:
在StyleNeRF中,第一个点可以通过在计算最终颜色之前将特征提前聚合到2D空间中来部分实现。通过这种方式,每个像素都被分配了一个特征向量,而且,它只需要通过一次网络,而不是像NeRF那样为射线上的所有采样点多次调用网络。我们将等式4近似为:
| �𝒘Approx(𝒓)=∫0∞�𝒘(�)⋅ℎ�∘[�𝒘��(𝒓(�)),�(𝒅)]𝑑�≈ℎ�∘[�𝒘��,��(𝒜(𝒓)),�(𝒅)], | (5) |
where �𝒘�,��(𝒜(𝒓))=�𝒘�∘�𝒘�−1∘…∘�𝒘��+1∘𝒜(𝒓) and 𝒜(𝒓)=∫0∞�𝒘(�)⋅�𝒘��(𝒓(�))𝑑�. The definitions of 𝒜(.) and �𝒘�,��(.) can be extended to the operations on a set of rays, each ray processed independently. Next, instead of using volume rendering to render a high-resolution feature map directly, we can employ NeRF to generate a downsampled feature map at a low resolution and then employ upsampling in 2D space to progressively increase into the required high resolution. We take two adjacent resolutions as an example. Suppose ��∈ℝ�/2×�/2 and ��∈ℝ�×� are the corresponding rays of the pixels in the low- and high-resolution images, respectively. To approximate the high-resolution feature map, we can up-sample in the low-resolution feature space:
�𝒘�,��(𝒜(𝒓))=�𝒘�∘�𝒘�−1∘…∘�𝒘��+1∘𝒜(𝒓) 和 𝒜(𝒓)=∫0∞�𝒘(�)⋅�𝒘��(𝒓(�))𝑑� 。 𝒜(.) 和 �𝒘�,��(.) 的定义可以扩展到对一组光线的操作,每条光线都被独立处理。接下来,我们可以使用NeRF来生成低分辨率的下采样特征图,然后在2D空间中使用上采样来逐渐增加到所需的高分辨率,而不是使用体渲染来直接渲染高分辨率特征图。我们以两个相邻的决议为例。假设 ��∈ℝ�/2×�/2 和 ��∈ℝ�×� 分别是低分辨率图像和高分辨率图像中的像素的对应射线。为了近似高分辨率特征图,我们可以在低分辨率特征空间中进行上采样:
| �𝒘�,��(𝒜(��))≈Upsample(�𝒘�,��(𝒜(��))) | (6) |
Recursively inserting Upsample operators enables efficient high-resolution image synthesis as the computationally expensive volume rendering only needs to generate a low-resolution feature map. The efficiency is further improved when using fewer channels for higher resolution.
递归插入上采样运算符可以实现高效的高分辨率图像合成,因为计算量大的体积渲染只需要生成低分辨率特征图。当使用更少的通道获得更高的分辨率时,效率进一步提高。
While early aggregation and upsampling operations can accelerate the rendering process for high-resolution image synthesis, they would come with scarification to the inherent consistency of NeRF. There are two reasons why they introduce inconsistency. First, the resulting model contains nonlinear transformations to capture spurious correlations in 2D observation, mainly when substantial ambiguity exists. For example, our training data are unstructured single-view images without sufficient multi-view supervision. Second, such a pixel-space operation like up-sampling would compromise 3D consistency. Therefore, naïve model designs would lead to severe multi-view inconsistent outputs (e.g., when moving the camera to render images, hairs are constantly changing). In the following, we propose several designs and choices to alleviate the inconsistency in the outputs.
虽然早期的聚合和上采样操作可以加速高分辨率图像合成的渲染过程,但它们会破坏NeRF的内在一致性。有两个原因导致了不一致。首先,所得到的模型包含非线性变换,以捕捉虚假的相关性在2D观察,主要是当大量的模糊性存在。例如,我们的训练数据是非结构化的单视图图像,没有足够的多视图监督。其次,像上采样这样的像素空间操作会损害3D一致性。因此,幼稚的模型设计会导致严重的多视图不一致输出(例如,当移动照相机以渲染图像时,毛发不断变化)。在下文中,我们提出了几种设计和选择,以减轻输出中的不一致性。
3.3Preserving 3D consistency
3.3保持3D一致性

Figure 2:Internal representations and the outputs from StyleNeRF trained with different upsampling operators. With LIIF, patterns stick to the same pixel coordinates when the viewpoint changes; With bilinear interpolation, bubble-shape artifacts can be seen on the feature maps and images. Our proposed upsampler faithfully preserves 3D consistency while getting rid of bubble-shape artifacts.
图2:内部表示和使用不同上采样算子训练的StyleNeRF的输出。使用LIIF,当视点改变时,模式会坚持相同的像素坐标;使用双线性插值,可以在特征图和图像上看到气泡形状的伪影。我们提出的上采样器忠实地保留了3D的一致性,同时摆脱了气泡形状的文物。
Upsampler design 上采样器设计
Up-sampling in 2D space causes multi-view inconsistency in general; however, the specific design choice of the upsampler determines how much such inconsistency is introduced. As our model is directly derived from NeRF, MLP (1×1 Conv) is the basic building block. With MLPs, however, pixel-wise learnable upsamplers such as pixelshuffle (Shi et al., 2016) or LIIF (Chen et al., 2021b) produce “chessboard” or “texture sticking” artifacts due to its tendency of relying on the image coordinates implicitly. In the meanwhile, Karras et al. (2019; 2020b; 2021) proposed to use non-learnable upsamplers that interpolate the feature map with pre-defined low-pass filters (e.g. bilinear interpolation). While these upsamplers can produce smoother outputs, we observed non-removable “bubble” artifacts in both the feature maps and output images. We conjecture it is due to the lack of local variations when combining MLPs with fixed low-pass filters. We achieve the balance between consistency and image quality by combining these two approaches (see Figure 2). For any input feature map �∈ℝ�×�×�:
2D空间中的上采样通常会导致多视图不一致;然而,上采样器的特定设计选择决定了引入多少这种不一致。由于我们的模型直接来自NeRF,因此MLP( 1×1 Conv)是基本的构建块。然而,使用MLP,可以使用逐像素可学习的上采样器,诸如pixelshuffle(Shi等人,2016)或LIIF(Chen等人,2021 b)由于其隐含地依赖于图像坐标的倾向而产生“棋盘”或“纹理粘连”伪影。与此同时,Karras等人(2019; 2020 b; 2021)提出使用不可学习的上采样器,用预定义的低通滤波器(例如双线性插值)对特征图进行插值。虽然这些上采样器可以产生更平滑的输出,但我们在特征图和输出图像中观察到不可移除的“气泡”伪影。我们推测这是由于缺乏当地的变化时,结合MLP与固定的低通滤波器。 通过结合这两种方法,我们实现了一致性和图像质量之间的平衡(见图2)。 对于任何输入特征图 �∈ℝ�×�×� :
| Upsample(�)=Conv2d(Pixelshuffle(Repeat(�,4)+��(�),2),�), | (7) |
where ��:ℝ�→ℝ4� is a learnable 2-layer MLP, and � is a fixed blur kernel (Zhang, 2019).
其中 ��:ℝ�→ℝ4� 是一个可学习的2层MLP, � 是一个固定的模糊内核(Zhang,2019)。
NeRF path regularization
NeRF路径正则化
We propose a new regularization term to enforce 3D consistency, which regularizes the model output to match the original path (Equation 4). In this way, the final outputs can be closer to the NeRF results, which have multi-view consistency. This is implemented by sub-sampling pixels on the output and comparing them against those generated by NeRF:
我们提出了一个新的正则化项来加强3D一致性,它正则化模型输出以匹配原始路径(等式4)。这样,最终输出可以更接近NeRF结果,具有多视图一致性。这是通过对输出上的像素进行子采样并将其与NeRF生成的像素进行比较来实现的:
| ℒNeRF-path=1|�|∑(�,�)∈�(�𝒘Approx(�in)[�,�]−�𝒘NeRF(�out[�,�]))2, | (8) |
where � is the set of randomly sampled pixels; �in and �out are the corresponding rays of the pixels in the low-resolution image generated via NeRF and high-resolution output of StyleNeRF.
其中 � 是随机采样像素的集合; �in 和 �out 是经由NeRF和StyleNeRF的高分辨率输出生成的低分辨率图像中的像素的对应射线。
Remove view direction condition
删除视图方向条件
Predicting colors with view direction condition was suggested by the original NeRF for modeling view-dependent effects and was by default applied in most follow-up works (Chan et al., 2021; Niemeyer & Geiger, 2021b). However, this design would give the model additional freedom to capture spurious correlations and dataset bias, especially if only a single-view target is provided. We, therefore, remove the view direction in color prediction, which improves the synthesis consistency (See Figure 8).
最初的NeRF建议用视图方向条件预测颜色,用于对视图相关效果进行建模,并且默认应用于大多数后续工作中(Chan等人,2021; Niemeyer &盖革,2021 b)。然而,这种设计将给予模型额外的自由度来捕获虚假的相关性和数据集偏差,特别是在仅提供单视图目标的情况下。因此,我们在颜色预测中删除了视图方向,这提高了合成一致性(见图8)。
Fix 2D noise injection
修复2D噪声注入
Existing studies (Karras et al., 2019; 2020b; Feng et al., 2020) have showed that injecting per-pixel noise can increase the model’s capability of modeling stochastic variation (e.g. hairs, stubble). Nevertheless, such 2D noise only exists in the image plane, which will not change in a 3D consistent way when the camera moves. To preserve 3D consistency, our default solution is to trade the model’s capability of capturing variation by removing the noise injection as Karras et al. (2021) does. Optionally, we also propose a novel geometry-aware noise injection based on the estimated surface from StyleNeRF. See Section A.3 for more details.
现有研究(Karras等人,2019; 2020 b; Feng等人,2020年)已经表明,注入每像素噪声可以提高模型对随机变化(例如头发,胡茬)建模的能力。然而,这种2D噪声仅存在于图像平面中,当相机移动时,其不会以3D一致的方式改变。为了保持3D一致性,我们的默认解决方案是通过去除噪声注入来交换模型捕获变化的能力,就像Karras等人(2021)所做的那样。可选地,我们还提出了一种新的几何感知噪声注入的基础上估计的表面从StyleNeRF。更多详情请参见第A.3节。
3.4StyleNeRF Architecture
3.4 StyleNeRF架构
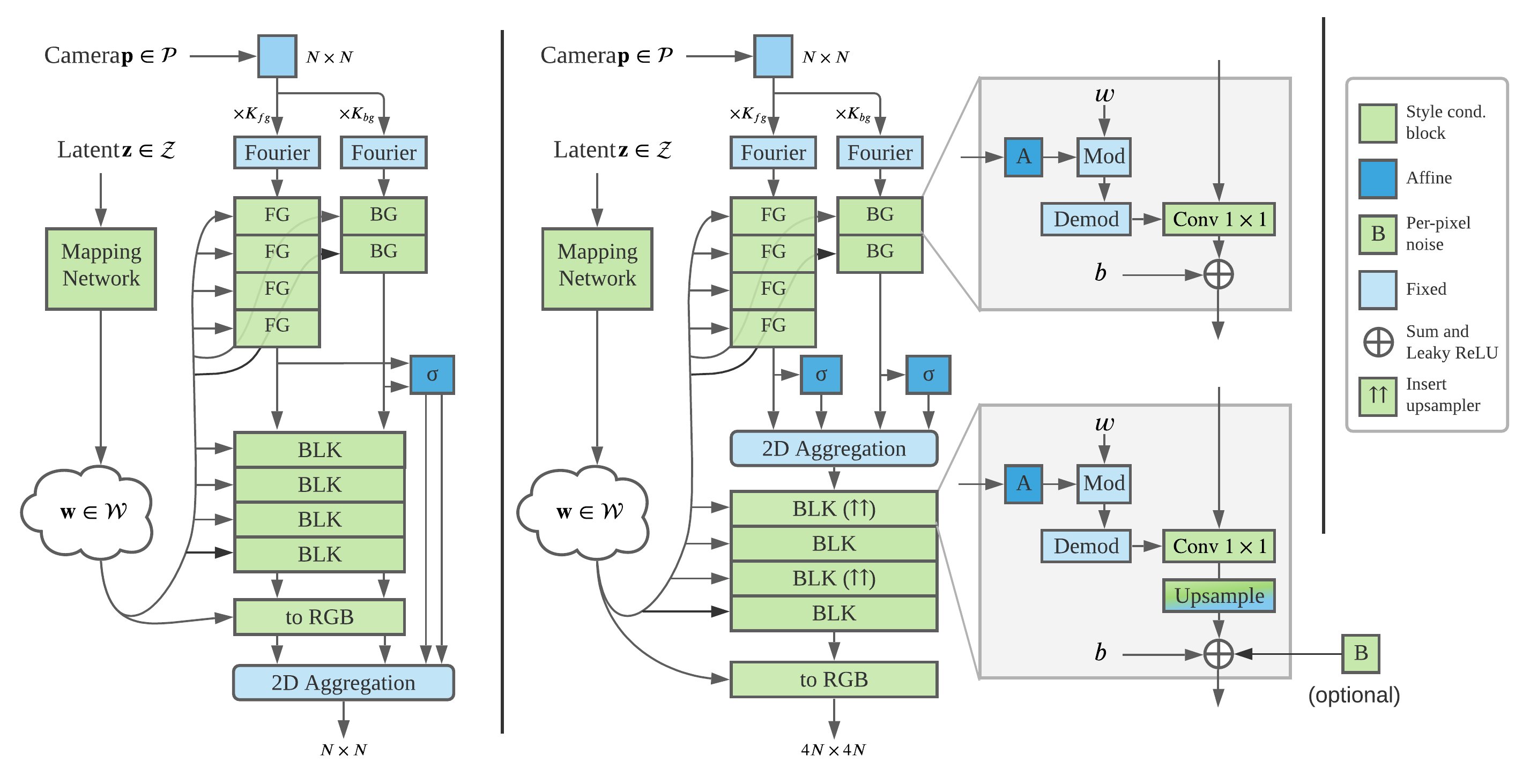
Figure 3:Example architecture. (Left) Original NeRF path; (right) Main path of StyleNeRF.
图3:示例架构。(左)原始NeRF路径;(右)StyleNeRF的主要路径。
In this section, we describe the network architecture and the learning procedure of StyleNeRF.
在本节中,我们将描述StyleNeRF的网络架构和学习过程。
Mapping Network 映射网络
Following StyleGAN2, latent codes are sampled from standard Gaussian and processed by a mapping network. Finally, the output vectors are broadcast to the synthesis networks.
在StyleGAN 2之后,潜在代码从标准高斯中采样并由映射网络处理。最后,将输出向量广播到合成网络。
Synthesis Network 合成网络
Considering that our training images generally have unbounded background, we choose NeRF++ (Zhang et al., 2020), a variant of NeRF, as the StyleNeRF backbone. NeRF++ consists of a foreground NeRF in a unit sphere and a background NeRF represented with inverted sphere parameterization. As shown in Figure 3, two MLPs are used to predict the density where the background network has fewer parameters than the foreground one. Then a shared MLP is employed for color prediction. Each style-conditioned block consists of an affine transformation layer and a 1×1 convolution layer (Conv). The Conv weights are modulated with the affine-transformed styles, and then demodulated for computation. leaky_ReLU is used as non-linear activation. The number of blocks depends on the input and target image resolutions.
考虑到我们的训练图像通常具有无界背景,我们选择NeRF++(Zhang et al.,2020),NeRF的一个变体,作为StyleNeRF的主干。NeRF++由单位球中的前景NeRF和用倒置球参数化表示的背景NeRF组成。如图3所示,使用两个MLP来预测密度,其中背景网络的参数比前景网络少。然后,一个共享的MLP用于颜色预测。每个风格调节块由仿射变换层和 1×1 卷积层(Conv)组成。Conv权重用仿射变换的样式调制,然后解调用于计算。leaky_ReLU用作非线性激活。块的数量取决于输入和目标图像分辨率。
Discriminator & Objectives
鉴别器和目标
We use the same discriminator as StyleGAN2. Following previous works (Chan et al., 2021; Niemeyer & Geiger, 2021b), StyleNeRF adopts a non-saturating GAN objective with R1 regularization (Mescheder et al., 2018). A new NeRF path regularization is employed to enforce 3D consistency. The final loss function is defined as follows (� is the discriminator and � is the generator including the mapping and synthesis networks):
我们使用与StyleGAN 2相同的插件。根据先前的工作(Chan等人,2021; Niemeyer &盖革,2021 b),StyleNeRF采用具有R1正则化的非饱和GAN目标(Mescheder等人,2018年)。一个新的NeRF路径正则化,以加强3D一致性。最终的损失函数定义如下( � 是卷积, � 是包括映射和合成网络的生成器):
| ℒ(�,�)=𝔼𝒛∼𝒵,𝒑∼𝒫[�(�(�(𝒛,𝒑))]+𝔼�∼�data[�(−�(�)+�∥∇�(�)∥2)]+�⋅ℒNeRF-path | (9) |
where �(�)=−log(1+exp(−�)), and �data is the data distribution. We set �=0.2 and �=0.5.
其中 �(�)=−log(1+exp(−�)) 和 �data 是数据分布。我们设置了 �=0.2 和 �=0.5 。
Progressive Training 递进培养
We train StyleNeRF progressively from low to high resolution, which makes the training more stable and efficient. We observed in the experiments that were directly training for the highest resolution easily makes the model fail to capture the object geometry. We suspect it is because both Equations 5 and 6 are just approximations to the original NeRF. Therefore, inspired by Karras et al. (2017), we propose a new three-stage progressive training strategy: For the first �1 images, we train StyleNeRF without approximation at low-resolution; then, during �1∼�2 images, both the generator and discriminator linearly increase the output resolutions until reaching the target resolution; At last, we fix the architecture and continue training the model at the highest resolution until �3 images. Please refer to the Section A.4 for more details.
我们从低分辨率到高分辨率逐步训练StyleNeRF,这使得训练更加稳定和高效。我们在实验中观察到,直接针对最高分辨率进行训练很容易使模型无法捕捉到物体的几何形状。我们怀疑这是因为方程5和6都只是对原始NeRF的近似。因此,受Karras等人(2017)的启发,我们提出了一种新的三阶段渐进式训练策略:对于前 �1 图像,我们在低分辨率下训练StyleNeRF而不进行近似;然后,在 �1∼�2 图像期间,生成器和非线性地增加输出分辨率,直到达到目标分辨率;最后,我们修复了架构,并继续以最高分辨率训练模型,直到 �3 图像。有关更多详情,请参阅第A.4节。

Figure 4:Qualitative comparisons at 2562. StyleNeRF achieves the best quality and 3D consistency.
图4: 2562 的定性比较。StyleNeRF实现了最佳的质量和3D一致性。
4Experiments 4实验
4.1Experimental Settings 4.1实验设置
Datasets 数据集
We evaluate StyleNeRF on four high-resolution unstructured real datasets: FFHQ (Karras et al., 2019), MetFaces (Karras et al., 2020a), AFHQ (Choi et al., 2020) and CompCars (Yang et al., 2015). The dataset details are described in Appendix B.
我们在四个高分辨率非结构化真实的数据集上评估StyleNeRF:FFHQ(Karras et al.,2019)、MetFaces(Karras等人,2020 a)、AFHQ(Choi等人,2020)和CompCars(Yang等人,2015年)。数据集详情见附录B。
Baselines 基线
We compare our approach with a voxel-based method, HoloGAN (Nguyen-Phuoc et al., 2019), and three radiance field-based methods: GRAF (Schwarz et al., 2020), �-GAN (Chan et al., 2021) and GIRAFFE (Niemeyer & Geiger, 2021b). As most of the baselines are restricted to low resolutions, we made the comparison at 2562 pixels for fairness. We also report the results of the state-of-the-art 2D GAN (Karras et al., 2020b) for reference. See more details in Appendix C.
我们将我们的方法与基于体素的方法HoloGAN(Nguyen-Gandoc等人,2019)和三种基于辐射场的方法:GRAF(施瓦茨et al.,2020), � -GAN(Chan等人,2021)和GIRAFFE(Niemeyer &盖革,2021 b)。由于大多数基线仅限于低分辨率,因此为了公平起见,我们在 2562 像素处进行了比较。我们还报告了最先进的2D GAN的结果(Karras等人,2020 b)以供参考。详见附录C。
Configurations 配置
All datasets except MetFaces are trained progressively. However, the MetFaces dataset is too small to train stably, so we finetune from the pretrained model for FFHQ at the highest resolution. By default, we train 64 images per batch, and set �1=500�,�2=5000� and �3=25000� images, respectively. The input resolution is fixed 322 for all experiments.
除了MetFaces之外的所有数据集都是渐进式训练的。然而,MetFaces数据集太小,无法稳定训练,因此我们以最高分辨率从FFHQ的预训练模型进行微调。默认情况下,我们每批训练 64 图像,并分别设置 �1=500�,�2=5000� 和 �3=25000� 图像。对于所有实验,输入分辨率是固定的 322 。

Figure 5:Uncurated set of images at 5122 produced by StyleNeRF from three datasets. Each example is rendered from a randomly sampled camera.
图5:由StyleNeRF从三个数据集生成的 5122 处的未经策划的图像集。每个示例都是从随机采样的相机渲染的。
4.2Results
Qualitative comparison 定性比较
We evaluate our approach and the baselines on three datasets: FFHQ, AFHQ, and CompCars. Target images are resized to 2562. We render each object in a sequence and sample four viewpoints shown counterclockwise in Figure 4. While all baselines can generate images under direct camera control, HoloGAN, GARF, and �-GAN fail to learn geometry correctly and thus produce severe artifacts. GIRAFFE synthesizes images in better quality; however, it produces 3D inconsistent artifacts: the shape and appearance in the output change constantly when the camera moves. We believe it is due to the wrong choice of 3×3 Conv layers. Compared to the baselines, StyleNeRF achieves the best visual quality with high 3D consistency across views. Please see more results in the supplemental video.
我们在三个数据集上评估了我们的方法和基线:FFHQ,AFHQ和CompCars。目标图像的大小调整为 2562 。我们按顺序渲染每个对象,并对图4中逆时针方向显示的四个视点进行采样。虽然所有基线都可以在相机直接控制下生成图像,但HoloGAN,GARF和 � -GAN无法正确学习几何形状,从而产生严重的伪影。GIRAFFE合成的图像质量更好;但是,它会产生3D不一致的伪影:当相机移动时,输出中的形状和外观会不断变化。我们认为这是由于错误选择了 3×3 Conv层。与基线相比,StyleNeRF实现了最佳的视觉质量,在视图之间具有高度的3D一致性。请在补充视频中查看更多结果。
Quantitative comparison 定量比较
We measure the visual quality of image generation by the Frechet Inception Distance (FID, Heusel et al., 2017) and Kernal Inception Distance (KID, Bińkowski et al., 2018) in Table 1. Across all three datasets, StyleNeRF consistently outperforms the baselines by significant gains in terms of FID and KID and largely reduces the performance gap between the 3D-aware GANs and the SOTA 2D GAN (i.e., StyleGAN2). Note that while 2D GANs can achieve high quality for each image, they cannot synthesize images of the same scene with 3D consistency.
我们通过Frechet初始距离(FID,Heusel等人,2017)和Kernal Inception Distance(KID,Bioglobkowski等人,2018年,在表1中。在所有三个数据集中,StyleNeRF在FID和KID方面的表现始终优于基线,并大大减少了3D感知GAN和SOTA 2D GAN之间的性能差距(即,StyleGAN2)。请注意,虽然2D GAN可以为每个图像实现高质量,但它们无法合成具有3D一致性的同一场景的图像。
Table 1: Quantitative comparisons at 2562. We calculate FID, KID×103, and the average rendering time (batch size =1). The 2D GAN (StyleGAN2 (Karras et al., 2020b)) results are for reference.
表1:0#处的定量比较。我们计算FID、KID ×103 和平均渲染时间(批量大小 =1 )。2D GAN(StyleGAN 2(Karras等人,2020 b))结果供参考。
| FFHQ 2562 FFHQ编号0# | AFHQ 2562 AFHQ编号0# | CompCars 2562 CompCar 2562 | Rendering time (ms / image) 渲染时间(ms /图像) |
||||||||
| Models 模型 | FID | KID | FID | KID | FID | KID | 64 | 128 | 256 | 512 | 1024 |
| 2D GAN | 4 | 1.1 | 9 | 2.3 | 3 | 1.6 | - | - | 46 | 51 | 53 |
| HoloGAN | 75 | 68.0 | 78 | 59.4 | 48 | 39.6 | 213 | 215 | 222 | - | - |
| GRAF 格拉夫 | 71 | 57.2 | 121 | 83.8 | 101 | 86.7 | 61 | 246 | 990 | 3852 | 15475 |
| �-GAN | 85 | 90.0 | 47 | 29.3 | 295 | 328.9 | 58 | 198 | 766 | 3063 | 12310 |
| GIRAFFE 长颈鹿 | 35 | 23.7 | 31 | 13.9 | 32 | 23.8 | 8 | - | 9 | - | - |
| Ours 我们 | 8 | 3.7 | 14 | 3.5 | 8 | 4.3 | - | - | 65 | 74 | 98 |
Table 1 also shows the speed comparison over different image resolutions on FFHQ. StyleNeRF enables rendering at interactive rates and achieves significant speed-up over voxel and pure NeRF-based methods, and is comparable to GIRAFFE and StyleGAN2.
表1还显示了FFHQ上不同图像分辨率的速度比较。StyleNeRF能够以交互式速率进行渲染,并实现了比体素和纯NeRF方法更快的速度,与GIRAFFE和StyleGAN2相当。
High-resolution synthesis
高分辨率合成
Unlike the baseline models, our method can generate high-resolution images (5122 and beyond). Figure 5 shows an uncurated set of images rendered by StyleNeRF. We also show more results of StyleNeRF and report the quantitative results of the SOTA 2D GAN (StyleGAN2 (Karras et al., 2020b)) for reference in the Appendix D.
与基线模型不同,我们的方法可以生成高分辨率图像( 5122 及以上)。图5显示了一组由StyleNeRF渲染的未经策划的图像。我们还显示了更多的StyleNeRF结果,并报告了SOTA 2D GAN的定量结果(StyleGAN 2(Karras等人,2020 b)),以供附录D参考。

Figure 6:Images synthesized from camera poses which starkly differ from training camera poses.
图6:从相机姿势合成的图像,与训练相机姿势截然不同。
4.3Controllable Image Synthesis
4.3可控图像合成
Explicit camera control 显式摄像机控制
Our method can synthesize novel views with direct camera control and generalize to extreme camera poses, which starkly differs from the training camera pose distribution. Figure 6 shows our results with extreme camera poses, such as zoom-in and -out, and steep view angles. The rendered images maintain good consistency given different camera poses.
我们的方法可以合成新的意见,直接相机控制和推广到极端的相机姿态,这与训练相机姿态分布截然不同。图6显示了我们的结果与极端的相机姿态,如放大和缩小,和陡峭的视角。在给定不同的摄影机姿势的情况下,渲染的图像保持良好的一致性。
Style mixing and interpolation
风格混合和插值
Figure 7 shows the results of style mixing and interpolation. As shown in style mixing experiments, copying styles before 2D aggregation affects geometry aspects (shape of noses, glasses, etc.), while copying those after 2D aggregation brings changes in appearance (colors of skins, eyes, hairs, etc.), which indicates clear disentangled styles of geometry and appearance. In the style interpolation results, the smooth interpolation between two different styles without visual artifacts further demonstrates that the style space is semantically learned.
图7显示了样式混合和插值的结果。如样式混合实验所示,在2D聚合之前复制样式会影响几何形状(鼻子、眼镜等的形状),而复制2D聚合后的那些会带来外观上的变化(皮肤、眼睛、头发等的颜色),这表明了几何形状和外观的清晰的非纠缠风格。在样式插值结果中,两种不同样式之间的平滑插值没有视觉伪影,进一步证明了样式空间是语义学习的。

Figure 7:Style mixing (Top): images were generated by copying the specified styles from source B to source A. All images are rendered from the same camera pose. Style interpolation (Middle): we linearly interpolate two sets of style vectors (leftmost and rightmost images) while rotating the camera. Style inversion and editing (Below): the target image is selected from the DFDC dataset (Dolhansky et al., 2019). To edit with CLIP scores, we input “a person with green hair” as the target text.
图7:样式混合(上图):通过将指定的样式从源B复制到源A来生成图像。所有图像都从相同的摄影机姿势渲染。样式插值(中间):我们在旋转相机的同时线性插值两组样式向量(最左边和最右边的图像)。样式反转和编辑(下图):从DFDC数据集中选择目标图像(Dolhansky等人,2019年)。要使用CLIP分数进行编辑,我们输入“一个长着绿色头发的人”作为目标文本。

Figure 8:Failure results of ablation studies and limitations.
图8:消融研究的失败结果和局限性。
Style inversion and editing
风格反转和编辑
We can also take a learned StyleNeRF model for inverse rendering tasks. To achieve this, we first pre-train a camera pose predictor in a self-supervised manner. Given a target image, we use this predictor to estimate the camera pose and optimize the styles via back-propagation to find the best styles that match the target image. After obtaining the styles, we can further perform semantic editing. For instance, we can optimize the styles according to text snippet using a CLIP loss (Radford et al., 2021; Patashnik et al., 2021). An example is shown in Figure 7.
我们还可以采用一个学习过的StyleNeRF模型来进行逆向渲染任务。为了实现这一点,我们首先以自我监督的方式预训练相机姿态预测器。给定一个目标图像,我们使用这个预测器来估计相机姿态,并通过反向传播优化样式,以找到与目标图像匹配的最佳样式。在获得样式之后,我们可以进一步进行语义编辑。例如,我们可以使用CLIP损失根据文本片段优化样式(拉德福等人,2021; Patashnik等人,2021年)。示例如图7所示。
4.4Ablation Studies 4.4消融研究
Figure 8 (a) shows a typical result without progressive training. Despite not directly affecting the quality of each single image, the model fails to learn the correct shape, e.g. the face should be in convex shape but is predicted as concave surfaces. This leads to severe 3D inconsistent artifacts when the camera moves (see the red circles in Figure 8 (a))
图8(a)显示了没有渐进式训练的典型结果。尽管没有直接影响每个图像的质量,但模型无法学习正确的形状,例如,面部应该是凸面形状,但被预测为凹面。这导致相机移动时出现严重的3D不一致伪影(参见图8(a)中的红色圆圈)
As shown in Figure 8 (b), without NeRF-path regularization, the model sometimes gets stuck learning geometry in 3D and produces a “flat shape” output.
如图8(B)所示,如果没有NeRF路径正则化,模型有时会在3D中学习几何形状并产生“平面形状”输出。
Figure 8 (c) demonstrates an example of the result with view direction as a condition. The modeling of view-dependent effects introduces an ambiguity between 3D shape and radiance and thus leads to a degenerate solution without multi-view consistency (see the red circles in Figure 8 (c)).
图8(c)展示了以观看方向作为条件的结果的示例。视图相关效应的建模引入了3D形状和辐射之间的模糊性,从而导致没有多视图一致性的退化解决方案(参见图8(c)中的红色圆圈)。
4.5Limitations and Future work
4.5局限性和今后的工作
While StyleNeRF can efficiently synthesize photo-realistic high-resolution images in high multi-view consistency with explicit camera control, it sacrifices some properties that pure NeRF-based methods have. An example is shown in Figure 8 (d), where we extract the underlying geometry with marching cube from the learned density. Although StyleNeRF is able to recover a coarse geometry, it captures less details compared to the pure NeRF-based models such as �-GAN (Chan et al. (2021)). Additionally, StyleNeRF only empirically preserves multi-view consistency, but it does not guarantee strict 3D consistency. Further exploration and theoretical analysis are needed.
虽然StyleNeRF可以通过显式相机控制高效地合成具有照片般真实感的高分辨率图像,但它牺牲了纯NeRF方法的一些属性。图8(d)中显示了一个示例,其中我们从学习的密度中提取了具有行进立方体的底层几何。虽然StyleNeRF能够恢复粗略的几何形状,但与纯NeRF模型(如 � -GAN)相比,它捕获的细节较少(Chan等人(2021))。此外,StyleNeRF仅凭经验保持多视图一致性,但不能保证严格的3D一致性。需要进一步的探索和理论分析。
5Conclusion 5结论
We proposed a 3D-aware generative model, StyleNeRF, for efficient high-resolution image generation with high 3D consistency, which allows control over explicit 3D camera poses and style attributes. Our experiments have demonstrated that StyleNeRF can synthesize photo-realistic 10242 images at interactive rates and outperforms previous 3D-aware generative methods.
我们提出了一个3D感知的生成模型,StyleNeRF,用于高效的高分辨率图像生成与高3D一致性,它允许控制显式的3D相机姿势和风格属性。我们的实验表明,StyleNeRF可以以交互速率合成照片级逼真的 10242 图像,并且优于以前的3D感知生成方法。
Ethics Statement 道德声明
Our work focuses on technical development, i.e., synthesizing high-quality images with user control. Our approach can be used for movie post-production, gaming, helping artists reduce workload, generating synthetic data to develop machine learning techniques, etc. Note that our approach is not biased towards any specific gender, race, region, or social class. It works equally well irrespective of the difference in subjects.
我们的工作重点是技术开发,即,通过用户控制合成高质量图像。我们的方法可用于电影后期制作,游戏,帮助艺术家减少工作量,生成合成数据以开发机器学习技术等。它同样适用于不同的主题。
However, the ability of generative models, including our approach, to synthesize images at a quality that some might find difficult to differentiate from source images raises essential concerns about different forms of disinformation, such as generating fake images or videos. Therefore, we believe the image synthesized using our approach must present itself as synthetic. We also believe it is essential to develop appropriate privacy-preserving techniques and large-scale authenticity assessment, such as fingerprinting, forensics, and other verification techniques to identify synthesized images. Such safeguarding measures would reduce the potential for misuse.
然而,包括我们的方法在内的生成模型能够以某些人可能难以区分的质量合成图像,这引起了人们对不同形式的虚假信息的基本担忧,例如生成虚假图像或视频。因此,我们认为使用我们的方法合成的图像必须呈现为合成的。我们还认为,开发适当的隐私保护技术和大规模的真实性评估至关重要,例如指纹识别,取证和其他验证技术,以识别合成图像。这种保障措施将减少滥用的可能性。
We also hope that the high-quality images produced by our approach could foster the development of the forgery mentioned above detection and verification systems. Finally, we believe that a robust public conversation is essential to creating a set of appropriate regulations and laws that would alleviate the risks of misusing these techniques while promoting their positive effects on technology development.
我们还希望,我们的方法产生的高质量图像可以促进上述伪造检测和验证系统的发展。最后,我们认为,强有力的公众对话对于制定一套适当的法规和法律至关重要,这些法规和法律将减轻滥用这些技术的风险,同时促进其对技术发展的积极影响。