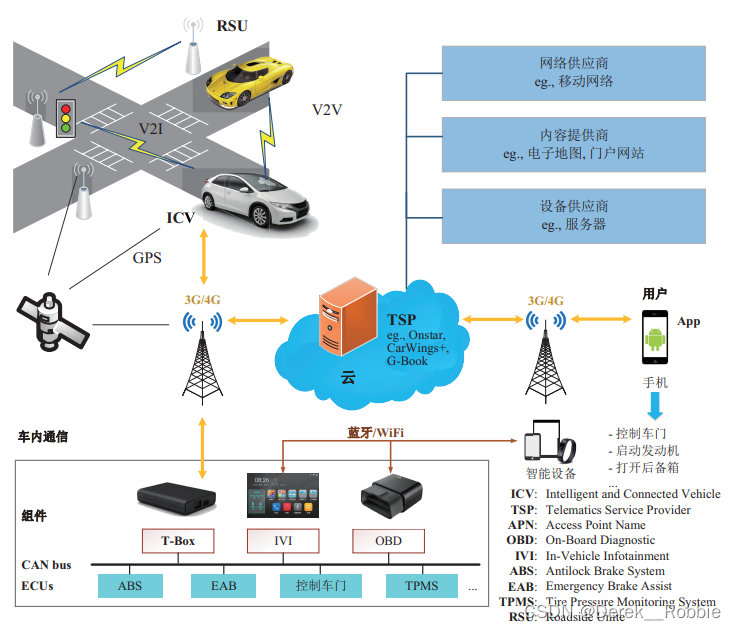
一、问题重述
甲骨文是我国目前已知的最早成熟的文字系统,它是一种刻在龟甲或兽骨上的古老文字。甲骨文具有极其重要的研究价值,不仅对中国文明的起源具有重要意义,也对世界文明的研究有着深远影响。在我国政府的大力推动下,甲骨文研究已经进入一个全新的发展阶段。人工智能和大数据技术被应用于甲骨文全息性研究及数字化工程建设,成为甲骨文信息处理领域的研究热点。
甲骨文拓片图像分割是甲骨文数字化工程的基础问题,其目的是利用数字图像处理和计算机视觉技术,在甲骨文原始拓片图像的复杂背景中提取出特征分明且互不交叠的独立文字区域。它是甲骨文字修复、字形复原与建模、文字识别、拓片缀合等处理的技术基础[2]。然而,甲骨拓片图像分割往往受到点状噪声、人工纹理和固有纹理三类干扰元素的严重影响[3]。且甲骨文图像来源广泛,包括拓片、拍照、扫描、临摹等,不同的图像来源,其干扰元素的影响是不同的。由于缺乏对甲骨文字及其干扰元素的形态先验特征的特殊考量,通用的代表性图像分割方法目前尚不能对甲骨文原始拓片图像中的文字目标和点状噪声、人工纹理、固有纹理进行有效判别,其误分割率较高,在处理甲骨拓片图像时均有一定局限性。如何从干扰众多的复杂背景中准确地分割出独立文字区域,仍然是一个亟待解决的具有挑战性的问题。
图1为一张甲骨文原始拓片的图像分割示例,左图为一整张甲骨文原始拓片,右图即为利用图像分割算法[4]实现的拓片图像上甲骨文的单字分割。甲骨文的同一个字会有很多异体字,这无疑增加了 甲骨文识别的难度,图2展示了甲骨文中“人”字的不同异体字。


问题一
问题1:对于附件1(Pre test 文件夹)给定的三张甲骨文原始拓片图片进行图像预处理,提取图像特征,建立甲骨文图像预处理模型,实现对甲骨文图像千扰元素的初步判别和处理。
解决思路
针对问题一,我们对附件一的甲骨文图像数据进行数据预处理
包括但不限于:
尺寸调整:将图像调整为模型要求的输入尺寸,通常是正方形或者某个固定的长宽比。
归一化:将图像的像素值缩放到固定范围内,例如0,1或−1,1,以便于模型的训练。
数据增强:通过随机旋转、裁剪、翻转、变换亮度和对比度等方式来增加训练数据的多样性,从而提高模型的泛化能力。
图像增强:对图像进行增强操作,如调整亮度、对比度、锐度、颜色等,以增强图像的特征。
解题代码(python)
import cv2
import numpy as np
import torch
import matplotlib.pyplot as plt
# 读取图像
image_path1 = r'data\1_Pre_test\h02060.jpg'
image_path2 = r'data\1_Pre_test\w01637.jpg'
image_path3 = r'data\1_Pre_test\w01870.jpg'
image1 = cv2.imread(image_path1)
image2 = cv2.imread(image_path2)
image3 = cv2.imread(image_path3)
# 定义目标尺寸
target_size = (416, 416) # YOLOv5 推荐的尺寸
# 调整大小
resized_image1 = cv2.resize(image1, target_size)
resized_image2 = cv2.resize(image2, target_size)
resized_image3 = cv2.resize(image3, target_size)
# 将图像归一化为 [0, 1]
normalized_image = []
normalized_image.append(resized_image1.astype(np.float32) / 255.0)
normalized_image.append(resized_image2.astype(np.float32) / 255.0)
normalized_image.append(resized_image3.astype(np.float32) / 255.0)
# 如果需要旋转,可以在这里进行旋转操作
# 将图像转换为 PyTorch 的 Tensor 格式,并添加批次维度
tensor_image = torch.tensor(normalized_image[0]).permute(2, 0, 1).unsqueeze(0)
# 现在 tensor_image 就是你所需的输入数据,准备用于 YOLOv5 模型
plt.imshow(normalized_image[1])
plt.axis('off')
plt.show()
问题二
解题思路
针对问题二,基于yolov5模型,利用附件2中的数据对模型进行微调,使其具备单字检测分割的能力。我们将部分分割结果可视化,验证模型分割能力。
解题代码
待更新问题三
解题思路
针对问题三,利用第二问得到的检测分割模型,在附件三测试集上对测试数据进行检测分割,并保存结果到附件Test_results.xlsx
解题代码
待更新问题四
解题思路
针对问题四,附件四给出部分甲骨文图像及其对应的简体中文,我们建立inception_v3分类模型,通过训练数据对模型进行微调。将得到的在甲骨文文字识别任务上微调后的inception_v3模型对测试集数据进行文字识别。将识别结果保存,写入论文。
解题代码
待更新资料获取
提供2024MathorCupBC题的思路分析与代码,欢迎进群讨论:953799264
B题目思路代码获取:http://app.niucodata.com/mianbaoduo/recommend.php?id=59179
B题目成品论文获取:http://app.niucodata.com/mianbaoduo/recommend.php?id=59182