目录
一. 5种基础数据结构
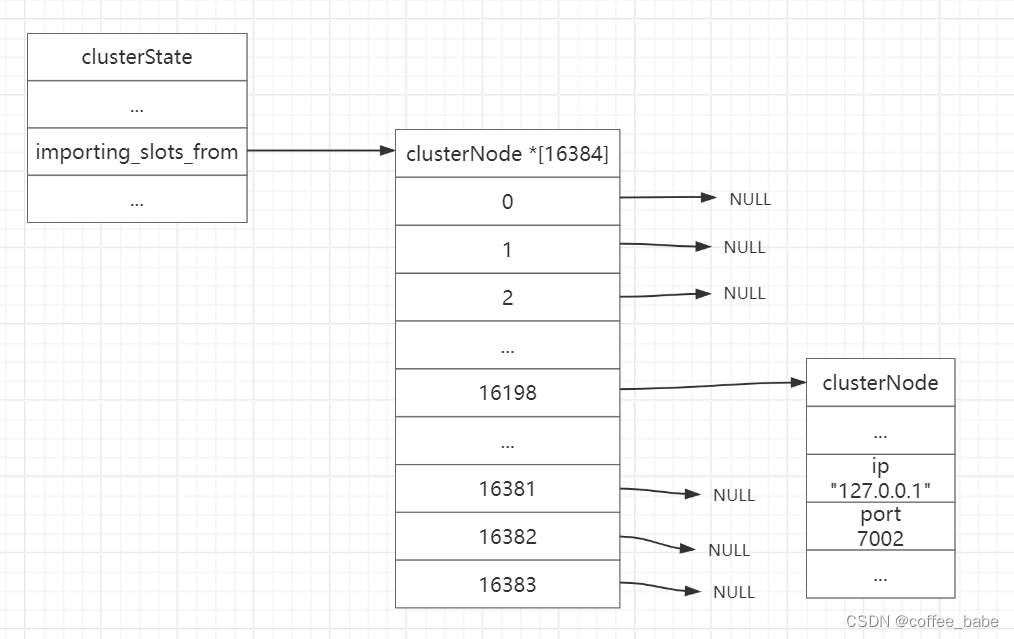
Redis 是一种高效的内存数据库,它提供了五种不同的数据结构,分别是字符串(String)、列表(List)、哈希(Hash)、集合(Set)和有序集合(Zset)。
1. 字符串(String)
Redis 的 String 数据结构用于存储字符串类型的数据。
其底层原理是基于简单动态字符串(Simple Dynamic String,SDS)的。
SDS 的优点包括:
- 空间预分配:当需要修改字符串时,Redis 会预先分配足够的空间,减少不必要的内存重分配次数。
- 惰性释放:当字符串缩短时,不会立即释放多余的内存,而是等待后续有需要时再进行释放。
- 二进制安全:可以存储任意类型的二进制数据。
例如,当向 Redis 中添加一个字符串 “hello” 时,Redis 会根据 SDS 原理进行存储和管理。
这种数据结构和底层原理的设计使得 Redis 在处理字符串类型的数据时具有高效性和灵活性。
2. 列表(List)
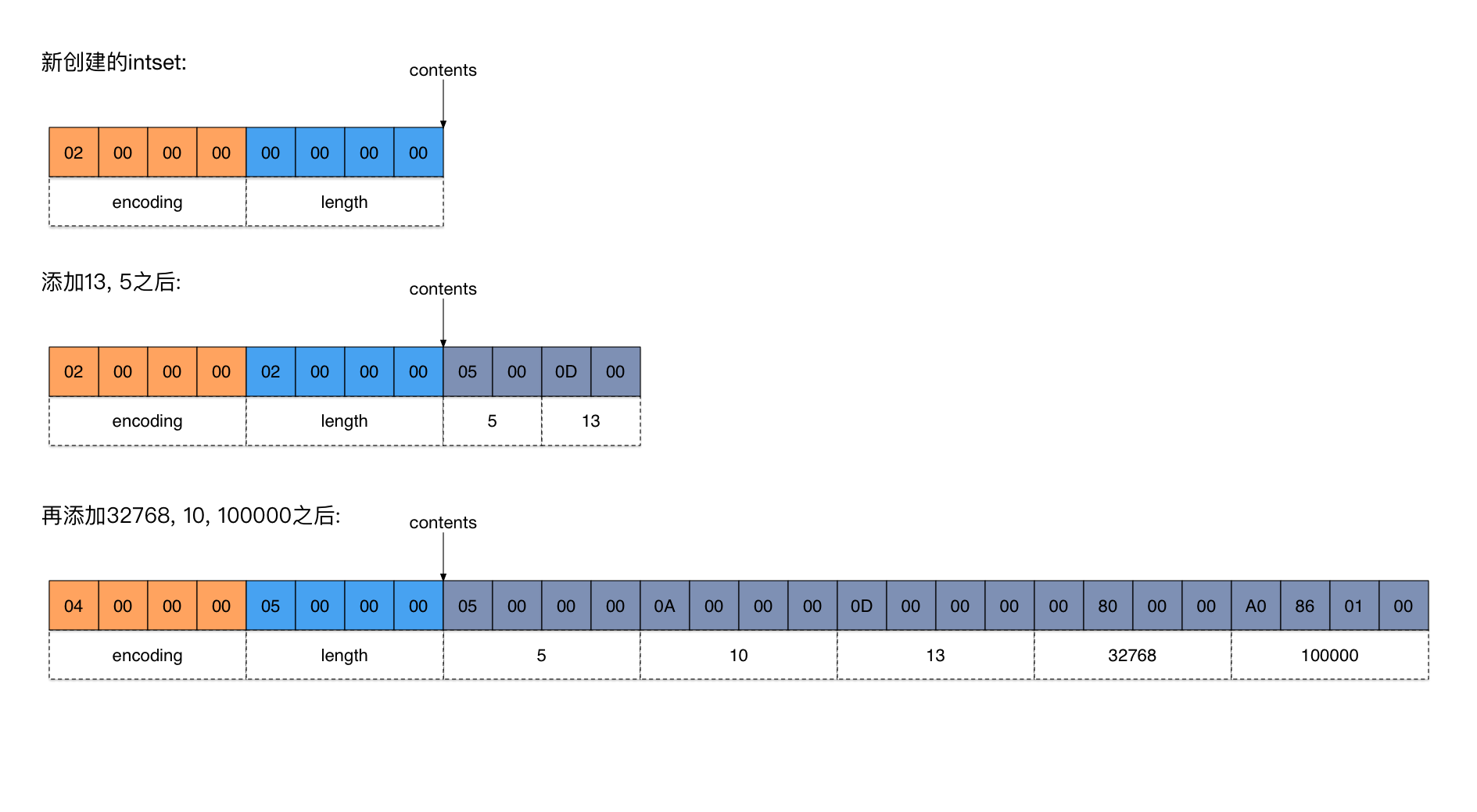
Redis 的 List 是一种线性的有序结构,可以按照元素被推入列表中的顺序来存储元素,能满足先进先出的需求,这些元素既可以是文字数据,又可以是二进制数据。其底层有 linkedList、zipList 和 quickList 这三种存储方式。
linkedList(双向链表):与 Java 中的 LinkedList 类似,Redis 中的 linkedList 是一个双向链表,由一个个节点组成。每个节点使用 adlist.h/listNode 结构来表示,其中包含 prev 和 next 指针,以及指向节点值的 value 指针。通过 prev 和 next 指针,程序可以高效地获取某个节点的前置节点和后继节点。同时,list 结构提供了 head 和 tail 指针,以及一些实现多态的特定函数,使得程序可以高效地获取链表的头节点和尾节点。zipList(压缩列表):是一种内存紧凑的数据结构,占用一块连续的内存空间,提升内存使用率。当一个列表只有少量数据,并且每个列表项要么是小整数值,要么是长度比较短的字符串时,Redis 会使用 zipList 来做 List 的底层实现。quickList(快速列表):由多个 ziplist 和一个双向循环链表组成。每个 ziplist 表示一个小的连续内存块,可以存储若干个元素。而双向循环链表用于连接多个 ziplist,形成一个大的、连续的内存空间。
3. 哈希(Hash)
Hash 是 Redis 中一种键值对集合,类似于编程语言中的 map 对象。一个 hash 类型的键最多可以存储 2^32 -1 个字段。Hash 类型的底层实现有三种:ziplist、listpack 和 hashtable。
4. 集合(Set)
Redis Set 数据结构是一个无序的、自动去重的集合数据类型。Set 底层用两种数据结构存储,一个是 hashtable,一个是 inset。
hashtable 的 key 为 set 中元素的值,而 value 为 null。inset 为可以理解为数组,使用inset 数据结构需要满足下述两个条件:
- 元素个数不少于默认值512;
- set-max-inset-entries的值为512。
5. 有序集合(Zset)
Redis 的 Zset(有序集合)是一种特殊的数据结构,它类似于集合(Set),但每个元素都关联了一个分数,用于进行有序排序。
Zset 的底层原理基于跳表(Skip List)实现。
以下是 Zset 的一些特点和原理:
- 元素有序:元素按照分数进行有序排列。
- 分数:每个元素都有一个分数,用于确定排序顺序。
- 快速插入和删除:通过跳表实现高效的插入和删除操作。
- 范围查询:支持按照分数范围查询元素。
例如,假设有一个 Zset 用于存储学生的成绩,成绩作为分数:
ZADD scores 85 "Alice"
ZADD scores 92 "Bob"
ZADD scores 78 "Charlie"
可以通过以下方式进行查询:
- 按照分数排序获取所有学生:ZRANGE scores 0 -1。
- 获取分数在 80 到 90 之间的学生:ZRANGEBYSCORE scores 80 90。
Zset 在实现排行榜、实时搜索等场景中非常有用。它提供了高效的插入、删除和查询操作,同时能够保证元素的有序性。
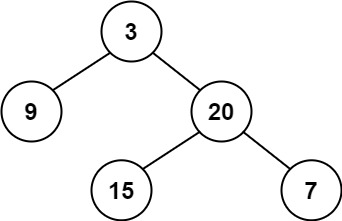
跳表
跳表全称为跳跃列表,它允许快速查询,插入和删除一个有序连续元素的数据链表。跳跃列表的平均查找和插入时间复杂度都是 O(logn)。快速查询是通过维护一个多层次的链表,且每一层链表中的元素是前一层链表元素的子集。所以它的查询速度媲美平衡二叉树,而且它的数据结构比平衡二叉树简单,结构示意图如下:
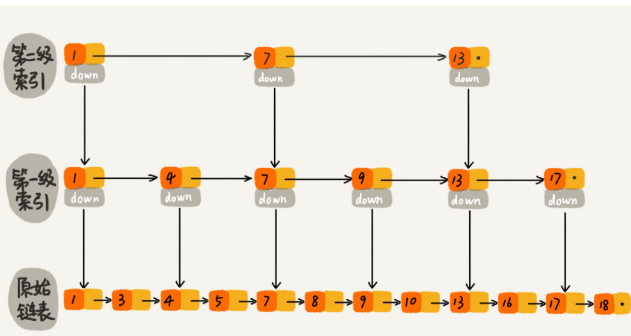
对于单链表来说,即使数据是已经排好序的,想要查询其中的一个数据,只能从头开始遍历链表,这样效率很低,时间复杂度很高,是 O(n)。跳表在 Redis 的 zset,leveldb 都有应用,是替代平衡树的方案,其思想的复杂度较低,容易理解和接触。
二. 3种特殊数据结构
1. 位图(bitmap)
- 特征:使用位数组来表示一系列布尔值,每个布尔值对应位数组中的一个位。
- 底层原理:位图通过位运算来高效地存储和查询大量布尔值。每个位可以独立地设置为0或1,代表对应元素的某种状态(例如,是否访问过)。
- 使用场景:适合用于统计和分析大规模数据,例如用户的活跃情况、网站的访问情况、商品的销售情况等。
2. 基数统计(HyperLogLog)
- 特征:一种用于基数统计的算法,只需要使用很少的内存就能估计集合中不同元素的数量。
- 底层原理:基于概率计数原理,通过对每个元素进行哈希,并记录哈希值的最高位非零位的位置,从而估计集合的大小。随着元素的增加,算法会逐渐收敛到真实基数的近似值。
- 使用场景:适合用于统计网站的 UV、独立 IP 数、用户访问量等场景。
3. 地理位置(Geo)
- 特征:使用有序集合(Sorted Set)来实现地理空间索引,有序集合中的每个成员都与一个经度和纬度相关联,成员按照分数(在地理空间中即距离)排序。
- 底层原理:Redis 使用 GeoHash 算法对地理位置进行编码,并将编码后的值作为有序集合的成员,距离作为分数。当执行地理空间相关的操作时(如查询附近地点),Redis 会根据GeoHash 值和给定的半径范围来检索符合条件的成员。
- 使用场景:适合存储和查询具有地理位置信息的数据,如用户位置、附近的商家、地理围栏等。


























![P1090 [NOIP2004 提高组] 合并果子](https://img-blog.csdnimg.cn/direct/44a421bcd05846bb85ff6d6a8c9353ea.png)