ollama
本地安装ollama
gemma
下载并部署模型 本机资源有限,可以下个2b的相对较小的模型
执行命令
ollama run gemma:2b
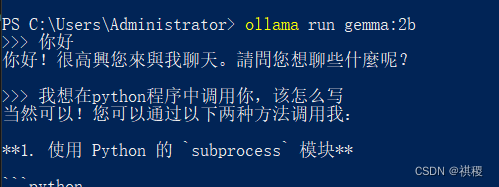
客户端调用
import requests
import json
data = {
"model": "gemma:2b",
"messages": [
{ "role": "user", "content": "hi, who are you?" }
]
}
response = requests.post('http://localhost:11434/api/chat', json=data,stream=True)
result = ''
for line in response.iter_lines():
if line:
json_data = json.loads(line)
content = json_data.get('message', {}).get('content', '')
print(content, end='')
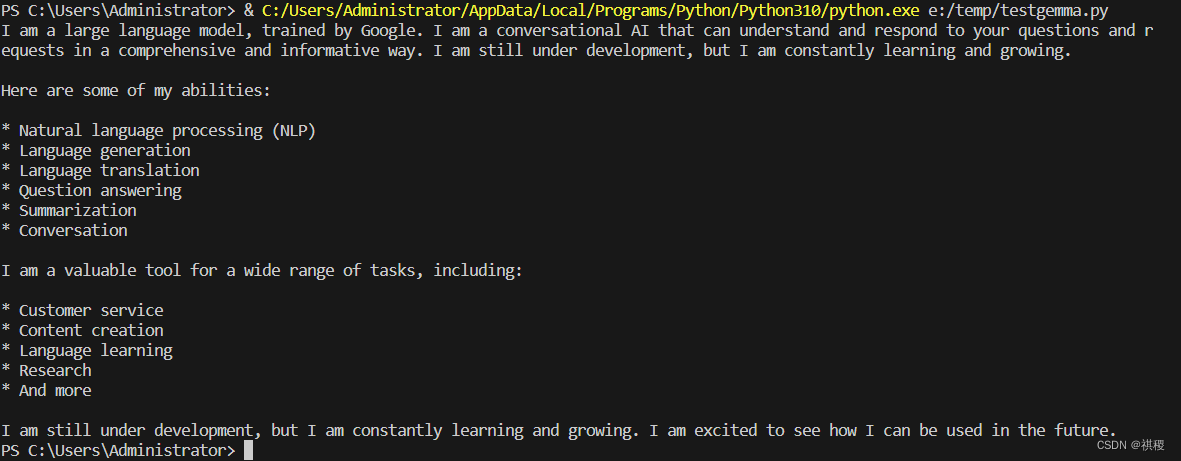
输出:



![SSE[Server-Sent Events]实现页面<span style='color:red;'>流</span><span style='color:red;'>式</span>数据<span style='color:red;'>输出</span>(<span style='color:red;'>模拟</span>ChatGPT<span style='color:red;'>流</span><span style='color:red;'>式</span><span style='color:red;'>输出</span>)](https://img-blog.csdnimg.cn/direct/a46a9cad966e42eab869e95079780583.png)