sd3基于rectidied flow的生成模型;sd3引入了T5-XXL作为text encoder提升模型的文本理解能力;sd3基于DiT,参数量为8B。
2.改进的RF
不同类型的生成模型差异在于前向过程和预测目标的差异,不同的前向过程采用不同的参数,导致不同的概率路径,而预测目标可以为预测噪声(DDPM),预测分数(SDE),预测向量场(FM),最终都可以统一为基于预测噪声的优化目标。
3.多模态DiT

3.1 改进的autoencoder
MMDiT和DiT一样,用autoencoder(VAE)将图像编码为latent,然后将latent转成patches,送入transformer处理。sd1.5和sdxl所使用的autoencoder是将一个HxWx3的图像编码为H/8xW/8xd的latent,d=4,高压缩比会产生小物体畸变,sd3通过增加d来提升autoencoder的重建质量。

sd3选择了16通道,增加通道并不是对生成模型(Unet和DiT)的参数带来大的影响,只需要修改网络第一层和最后一层的通道数,但是会增加任务的难度,当通道数从4增加16时,网络要拟合的内容增加了4倍,模型需要相应增加参数,

模型参数越大,通道数越大优势越明显。之前EMU也采用了16通道的autoencoder。DALLE3则是通过训练一个基于扩散模型的latent decoder来解决4通道autoencoder问题,但是不如直接采用16通道的autoencoder直接。
3.2 文本编码器
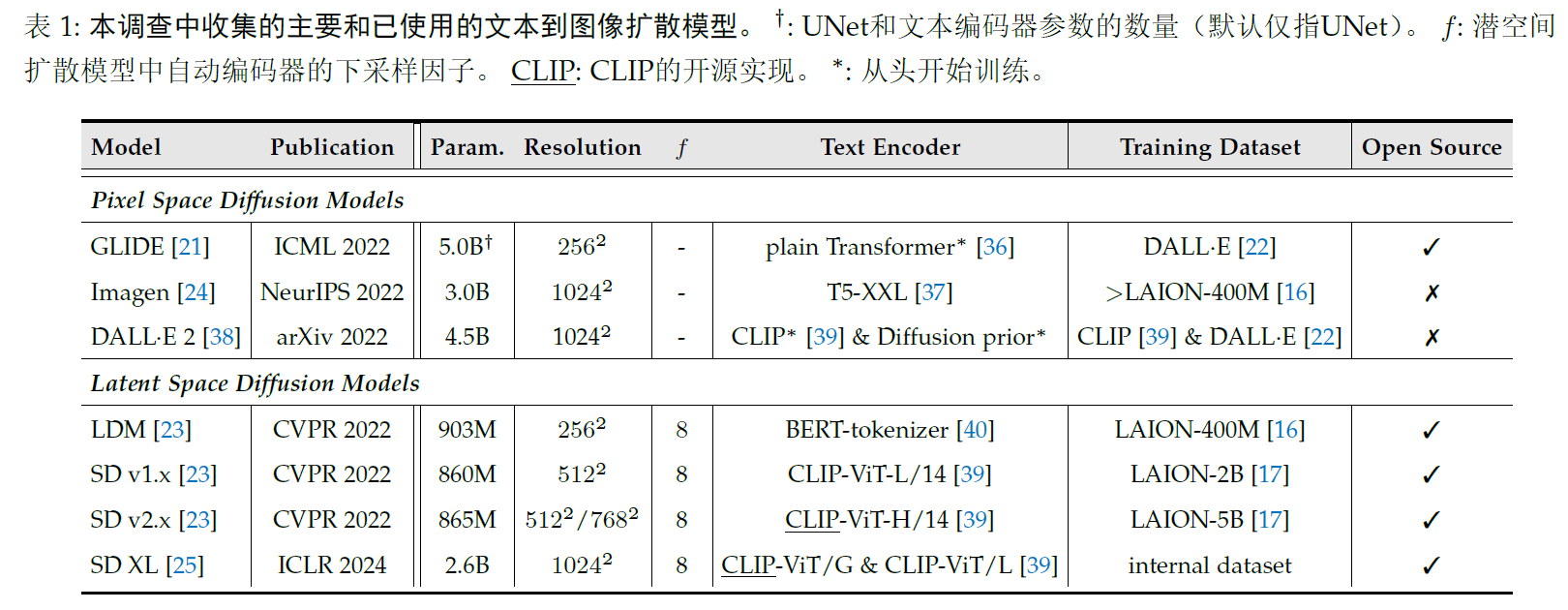
sd3的text encoder有3个,clip-vit/l参数124M,openclip Vit-bigG参数量为695M,T5-xxl encoder的参数量为4.7B,sd1.x的text encoder使用的是clip-vit/l,sd2.x采用的openclip vit-h,sdxl采用的是clip vit-l+openclip Vit-bigG,sd3加上了T5-xxL encoder。Imagen是最早使用T5-xxl encoder,Nvidia的eDiff-l和Meta的EMU采用T5-xxl encoder+clip作为text encoder,dalle3也是T5-xxl encoder。
sd3总共提取两个层面的特征,首先提取两个clip text encoder的pooled embedding,它们是文本的全局语义特征,维度大小是768和1280,两个embedding拼接在一起是2048,再进过一个mlp网络之后和timestep embedding相加。然后是文本细粒度特征,分别提取两个clip模型的倒数第二层特征,拼接在一起可以得到77x2048维的clip text embeddings,同样也从T5xxl encoder中提取最后一层的特征,维度大小是77x4096(限制了77个tokens,能够编码512tokens),对clip的embedding使用zeropadding得到T5 text embeddings同维度特征,最后将padding后的clip text emebddings和T5 embeddings在token维度拼接在一起,得到154x4096维度的text embeddings,text embeddings将通过一个linear层映射到与图像latent的patch embeddings同维度大小,并和patch embeddings拼接在一起送入MMDiT中。DALLE3可以处理长文本,但是由于使用clip text embeddings,sd3仍然只能处理77tokens长度的文本。

3.3 MM-DiT
和DiT一样处理图像latent空间,先对图像的latent转成patches,patch size为2x2,和DIT的默认配置是一样的,patch embedding再加上positional embedding送入到transformer中,对于clip pooled embedding可以直接和timestep embedding加在一起,并像DiT所设计的adaLN-ZERO一样将特征插入到transformer中。

对于序列text embeddings,通常是增加cross attention层,其中text embeddings作为attention的keys和value,比如sd的unet和pixart-alpha,但是sd3是直接将text embeddings和patch embeddings拼接在一起,不需要额外引入cross attention,由于text和image属于两个模态,采用两套独立的参数来处理,即所有的transformer层的学习参数是不共享的,但是共用一个self-attention来实现特征的交互,这等价于采用两个transformer模型来处理文本和图像,但是在attention层连接,是一个多模态模型。

MM-DiT和之前文生图模型的一个区别是文本特征不再只是作为一个条件,而是和图像特征同等对待处理,基于CC12M数据集将MM-DiT和其它架构做了对比,对比包括DiT(DiT指的是不引入cross attention,直接将text tokens和patches拼接,但是只有一套参数),CrossDiT(额外引入cross attention),UViT(UNet和transformer混合架构),还有3套参数的MM-DiT(clip text tokens,T5-XXL text tokens和patches各一套参数)。

MM-DiT的模型参数主要是模型的深度d,即transformer block的数量,此时对应的模型中间特征维度大小是64xd,这意味着当模型的深度d增大到rxd,模型的参数量会增大到r的三方,比如深度为24的MM-DiT参数量为2B,最大的MM-DIT深度为38,其参数量为2Bx(38/24)^3=8B。
3.4 QK-Normalization
为了提升混合精度训练的稳定性,MM-DiT的self-attention层还采用了QK-Normalization,当模型变大,而且在高分辨率图像上训练时,attention层的attention-logits(Q和K的矩阵乘)会变的不稳定,导致训练出现NAN,sd3采用RMSNorm(简化版layernorm)对attention的Q和K进行归一化。
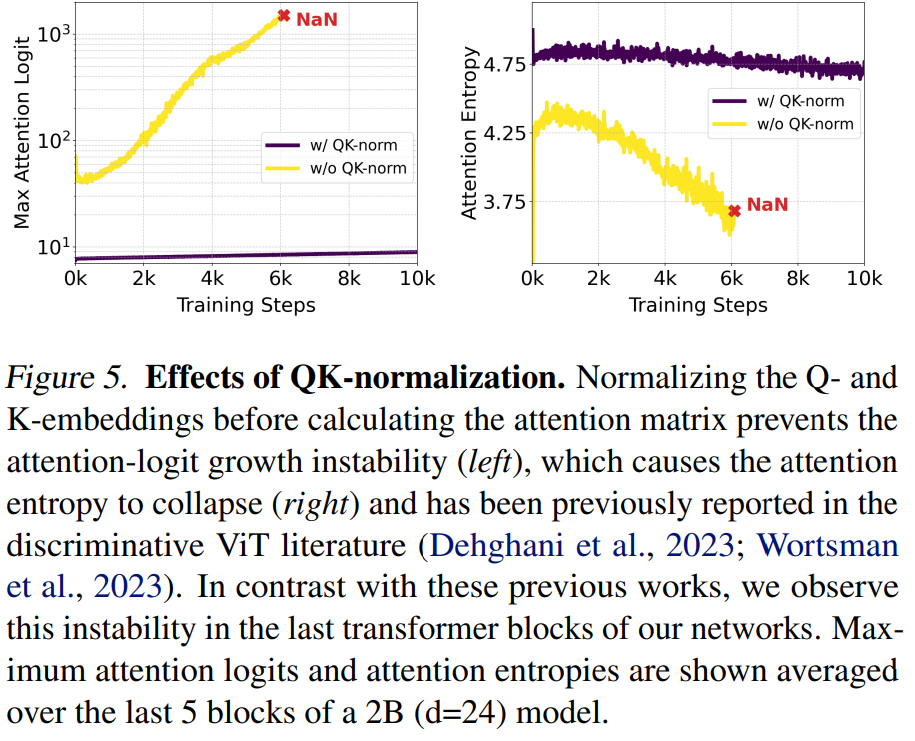
3.5 变尺度位置编码
MM-DiT的位置编码和VIT一样采用2d的frequency embeddings(2个1d frequency embeddings进行concat)。sd3先在256x256尺寸下训练,但最终会在1024x1024为中心的多尺度上微调,这就需要MM-DiT的位置编码需要支持变尺度,sd3采用的是插值和扩展。


3.6 timestep schedule 的shift
对高分辨率的图像,如果采用和低分辨率一样的noise scheduler,会出现对图像的破坏不够,对noise scheduler进行偏移。
3.7 模型scaling
不同规模的MM-DiT进行实验,分别是15,18,21,30,38.最大参数量为8B。

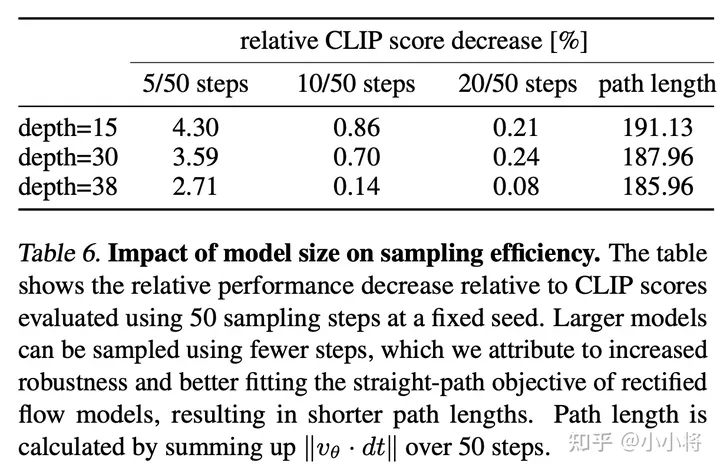
评价指标:validation loss/CompBench/GenEval,以及人类偏好,模型越大,质量越好。更大的模型不仅性能更好,而且生成时可以采用较小的采样步数。
4.实验细节
4.1 预训练数据处理
没有预训练数据集的带下和来源,但是预训练数据会进行一些筛选;
1.色情内容过滤,NSFW;2.图像美学,评分移除预测分数较低的图像;3.重复内容
4.2 图像caption
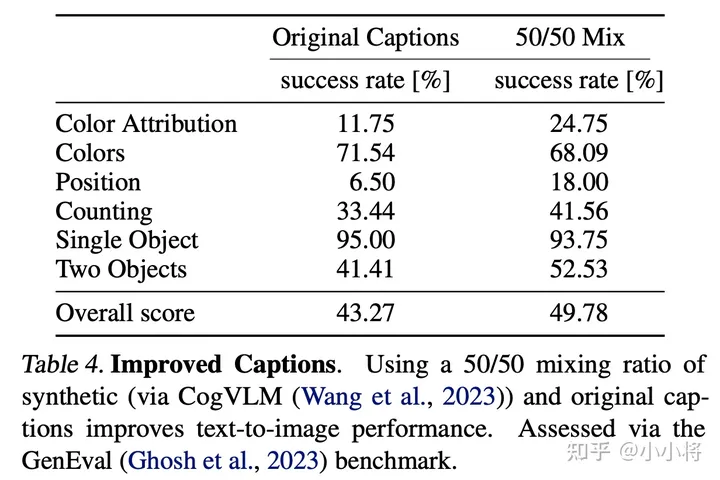
CogVLM,训练过程中,使用50%的原始caption和50%的合成caption,使用合成caption能够提升模型性能。
4.3 classifier-free guidance
训练过程需要对文本进行一定的drop来实现classifier-free guidance,这里三个text encoder各以46.4%的比例单独drop,text完全drop的比例为(46.6%)^3=10%。
三个text encoder独立drop的一个好处是推理时可以灵活使用text encoder,可以去掉比较吃显存的T5,只保留两个clip text encoder,实际不会影响视觉质量,但会导致文本遵循度。
4.4 DPO
DPO相较于RLHF的优势在于不需要单独训练一个reward模型,而且直接基于成对的比较数据训练。sd3没有finetune整个网络,而是基于rank=128的lora,进过dpo后,图像生成质量有一定的提升。
5.性能评测
5.1 定量评测

5.2 人工测评