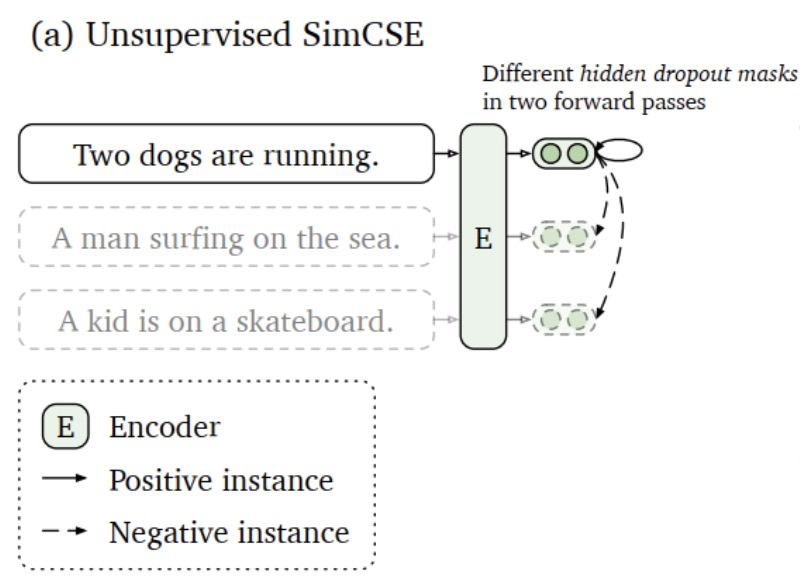
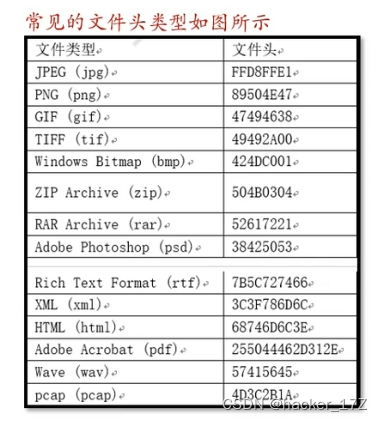
原文链接:https://arxiv.org/abs/1908.10084
提出契机:
提升相似文本的检索速度
在自然语言处理领域,BERT(Bidirectional Encoder Representations from Transformers)和RoBERTa(A Robustly Optimized BERT Pretraining Approach)已经取得了显著的成就,特别是在语义文本相似性(Semantic Textual Similarity, STS)任务上,它们展现出了卓越的性能。然而,这些模型的一个显著局限性在于,它们需要同时处理两个句子作为输入,这导致了计算成本的显著增加。例如,在处理包含10,000个句子的数据集时,为了找到最相似的文本对,BERT模型需要进行高达50,000,000次的推理运算。
这种计算密集型的架构使得BERT及其变体在执行语义相似性搜索和无监督任务(如文本聚类)时变得不那么适用。鉴于这些挑战,研究者们提出了一种改进的模型,名为Sentence-BERT,旨在解决原始BERT架构在处理此类任务时的不足。
Sentence-BERT的设计考虑到了计算效率和模型的适用性,使其能够更好地适应于语义相似性搜索和无监督学习任务。通过这种方法,研究者们希望能够在保持BERT和RoBERTa模型先进性能的同时,显著降低处理大规模数据集所需的计算资源,从而推动自然语言处理技术的发展和应用。
模型
训练
、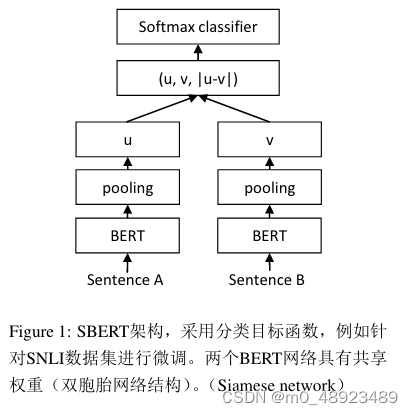
模型的具体结构如上图所示,为了选择更有效的句子嵌入,该文提出了三种池化策略:
- CLS:选择[CLS]位置的向量作为句子嵌入
- MEAN(平均池化):将所有token的向量求平均值作为句子嵌入
- MAX(最大池化):针对所有token的同一维度选择最大值,最终获得句子嵌入
提出了三种目标函数。具体采用哪种目标函数取决于训练数据的格式。
分类目标函数(如图1所示):
两个编码器输出的句子嵌入 u u u和 v v v,以及 ∣ u − v ∣ |u - v| ∣u−v∣在最后一个维度进行向量拼接,之后通过一个全连接神经网络 W t W_t Wt,得到最终的分类结果:
o = s o f t m a x ( W t ( u , v , ∣ u − v ∣ ) ) o = softmax(W_t(u, v, |u - v|)) o=softmax(Wt(u,v,∣u−v∣))
其中$k$是最终的标签数量
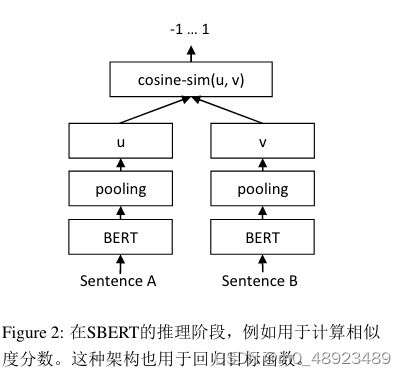
回归目标函数(如图2所示):
首先计算两个句子嵌入 u u u和 v v v的余弦相似度,之后传入均方误差损失函数计算损失。
三元组目标函数
给定一个锚定句子 a a a,一个正句子 p p p和一个负句子 n n n(如果是双编码器,那么正句子和负句子来自同一个编码器,锚定句子来自另一个编码器)。三元组损失函数的目标是确保 a a a和 p p p之间的距离小于 a a a和 n n n之间的距离。具体的数学公式如下:
m a x ( ∣ ∣ s a − s p ∣ ∣ − ∣ ∣ s a − s n ∣ ∣ + ϵ , 0 ) max(||s_a - s_p|| - ||s_a - s_n|| + \epsilon, 0) max(∣∣sa−sp∣∣−∣∣sa−sn∣∣+ϵ,0)
其中 s a s_a sa、 s n s_n sn、 s p s_p sp分别为句子a/n/p的向量表示, ∣ ∣ ⋅ ∣ ∣ || \cdot || ∣∣⋅∣∣表示两个向量的距离度量(文本使用欧式距离)。确保表 s p s_p sp比 s n s_n sn至少接近 s a s_a sa ϵ \epsilon ϵ个单位。 ϵ \epsilon ϵ默认值为1。
推理
推理阶段,如图2所示,连个句子分别输入两个句子编码器,得到输出向量后,选择同训练方式相同的一种pooling方式处理编码器输出的向量,得到最终的居句子嵌入 u u u和 v v v。
训练细节
采用SNLI和Multi-Genre NLI进行训练。SNLI为一个包含570000对标注为矛盾、蕴含和中性的句子对集合。MultiNLI包含430000对句子。训练采用图一的训练方式,结合一个3分类的sofrmax分类器目标函数对Sentence-BERT进行微调。默认池化方式为平均池化。
语义相似性评估(STS)
无监督STS

采用NLI数据集结合图1的方式进行训练,通过余弦相似度结合斯皮尔曼相关系数,在STS(STS12-16、STSB、SICK)数据集上进行评估,具体结果见表一所示。
采用直接使用BERT的输出性能较差。BERT嵌入的平均相关性仅为54.81,而仅使用CLS token的输出平均相关性为29.19,两者都低于计算平均GloVe嵌入。
使用描述的Siamese网络结构及微调方法显著提升了文本相似度估计的相关性,其表现明显优于InferSent和未经特殊调整的Universal Sentence Encoder。然而,在SICK-R数据集上,SBERT(Sentence BERT)的表现略微不及Universal Sentence Encoder。Universal Sentence Encoder的优势在于其在包含新闻报道、问答网页以及讨论论坛等多种类型数据集上进行了训练,这使得它在处理SICK-R这类特定任务时更具适应性。相反,SBERT的基础模型仅在维基百科文本和自然语言推理(NLI)数据集上进行了预训练阶段的学习。
尽管RoBERTa在多种监督学习任务中均显示出性能提升,但在生成句子嵌入这一特定应用中,相较于基于RoBERTa的改进版本SRoBERTa,SBERT与SRoBERTa之间所观察到的差异并不显著。这意味着尽管RoBERTa架构在许多任务上有所突破,但在生成固定长度的句子向量表示以衡量句子相似性等方面,SBERT与基于RoBERTa优化的SRoBERTa两者间的表现相近,没有表现出明显的优劣差距。
有监督STS
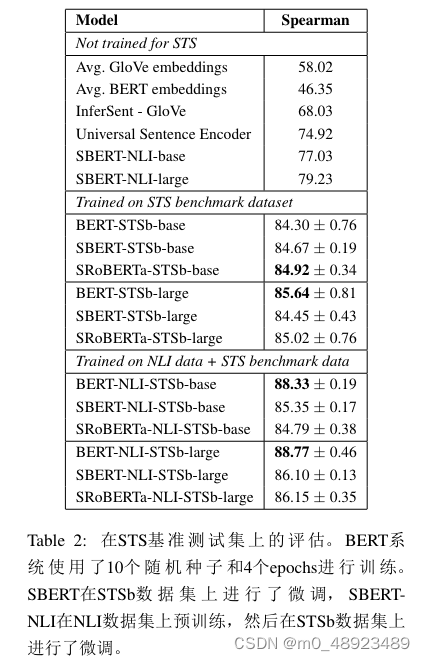
数据:NLI数据和STSb。
训练方式:
- 直接采用回归目标函数结合STSB数据集对模型进行训练。
- 首先采用分类目标函数结合NLI对模型进行训练,之后采用回归目标函数结合STSB数据集对模型进行训练。
观察到后一种策略导致了1-2点的小幅提升。这种两步法对BERT交叉编码器的影响尤其显著,性能提高了3-4点。我们没有发现BERT和RoBERTa之间有显著的差异。
Argument Facet Similarity
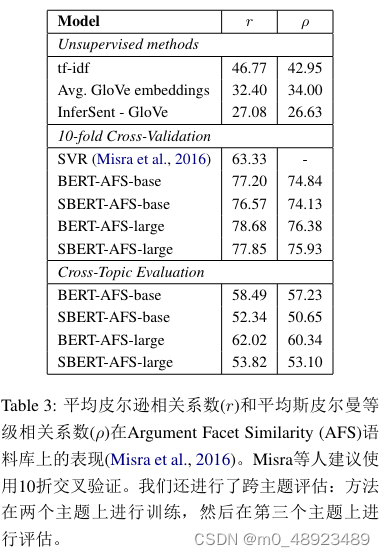
我们在Argument Facet Similarity (AFS)语料库上评估SBERT,该语料库由Misra et al. (2016)标注,包含6,000条来自社交媒体对话的关于争议话题(gun control、gay marriage和death penalty)的句子论据对。标注范围从0(“不同话题”)到5(“完全等价”)。AFS语料库中的相似性概念与SemEval的STS数据集有较大差异。STS数据通常描述性,而AFS数据是对话中的论据摘录。要被认为是相似的,论据不仅需要提出相似的主张,还需要提供相似的推理。此外,AFS中的句子之间的词汇差距更大。因此,简单的无监督方法以及最先进的STS系统在该数据集上的性能较差(Reimers et al., 2019)。
我们针对此数据集评估SBERT在两种情况下:1)如Misra等人所提议的,我们使用10折交叉验证进行评估。这种评估方法的缺点是不清楚方法在不同话题上的泛化能力。因此,2)我们在跨话题设置下评估SBERT。选择两个话题进行训练,然后在未包含的话题上进行评估,对所有三个话题重复此过程并取平均结果。
SBERT使用回归目标函数进行微调,使用余弦相似度计算句子嵌入的相似度。我们还提供了皮尔逊相关系数r,以便与Misra等人进行比较。但我们已经证明(Reimers et al., 2016),皮尔逊相关系数存在一些严重问题,不适用于比较STS系统。结果见表3。
无监督方法如tf-idf、平均GloVe嵌入或InferSent在该数据集上的表现较差,得分较低。在10折交叉验证的训练下,SBERT的表现接近BERT。
然而,在跨话题评估中,SBERT的Spearman相关度下降了约7分。要被认为是相似的,论据需要针对相同的主张并提供相同的推理。BERT能够利用注意力直接比较两个句子(如逐词比较),而SBERT必须将来自未见过的话题的单个句子映射到向量空间,使得具有相似主张和理由的论据靠近。这是一个更具挑战性的任务,似乎需要超过两个话题的训练才能与BERT达到同等水平。
Wikipedia Sections Distinction
感觉这个实验就是证明了一下预训练的BERT比BiLSTM效果好,这当然了,感觉有点多余。
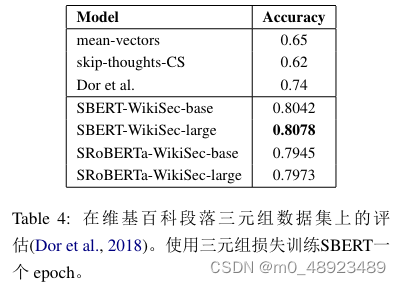
Doretal.(2018)利用维基百科创建了一个针对句子嵌入方法的细致主题划分的训练集、验证集和测试集。维基百科文章被分成专注于特定方面的独立部分。Dor等人假设来自同一部分的句子在主题上比来自不同部分的句子更接近。他们以此构建了一个大规模的弱标签三元组数据集:锚句和正例来自同一部分,而负例来自同一文章的不同部分。例如,来自AliceArnold文章的示例:锚句:*Arnold于1988年加入BBCRadioDramaCompany。*正例:*Arnold在2012年5月引起了媒体关注。*负例:Balding和Arnold是热衷的业余高尔夫爱好者。
我们使用Dor等人的数据集。我们采用三元组目标,对SBERT进行一epoch的训练,使用大约180万条训练三元组,并在222,957条测试三元组上进行评估。测试三元组来自独立的维基百科文章集合。作为评估指标,我们使用准确率:正例是否比负例更接近锚句?
结果见表4。Dor等人使用了带有三元组损失的双向长短时记忆(BiLSTM)架构进行微调,以获取句子嵌入。如表所示,SBERT显著优于Dor等人的BiLSTM方法。
Evaluation - SentEval
再次证明了一下该模型的效果好。
SentEval(Conneau and Kiela, 2018)是一个广受欢迎的工具包,用于评估句子嵌入的质量。句子嵌入被用作逻辑回归分类器的特征。逻辑回归分类器在10折交叉验证设置中针对各种任务进行训练,然后计算测试集的预测准确率。
SBERT句子嵌入的目的是不用于其他任务的迁移学习。我们认为,根据Devlin et al. (2018)描述的BERT微调方法更适合于新任务,因为它更新了BERT网络的所有层。然而,SentEval仍然可以让我们了解我们的句子嵌入在各种任务上的质量。
我们将在以下七个SentEval迁移任务上比较SBERT句子嵌入与其他句子嵌入方法:
• **情感预测(MR):**针对电影评论片段的五星级情感分析(Pang and Lee, 2005)。
• 情感分析(CR): 客户产品评论的情感预测(Hu and Liu, 2004)。
• 主题性预测: 电影评论和剧情摘要中的句子主观性判断(Pang and Lee, 2004)。
• MPQA:基于新闻报道的短语级观点极性分类(Wiebe et al., 2005)。
**• SST(斯坦福情感树库):**二分类标签的斯坦福情感树库(Socher et al., 2013)。
**• TREC:**来自TREC的精细粒度问题类型分类((Li and Roth, 2002))。
• 微软研究语义对齐语料库(MRPC): 来自平行新闻来源的微软研究近义句对数据集(Dolan et al., 2004)。
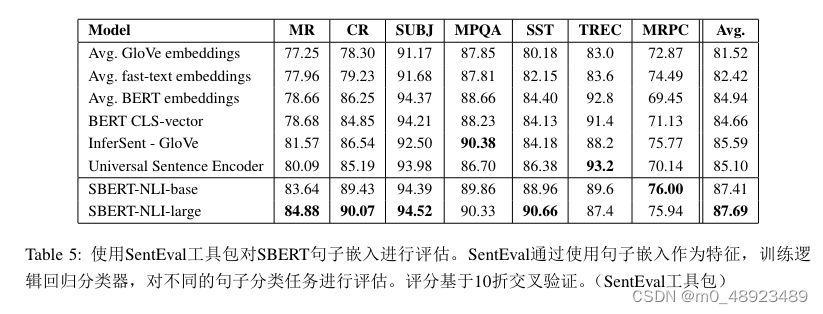
结果见表5。SBERT在7个任务中的5个中表现出最佳性能。与InferSent和Universal Sentence Encoder相比,其平均性能提高了约2个百分点。尽管SBERT的目标不是迁移学习,但它在该任务上仍优于其他最先进的句子嵌入方法。
SBERT的句子嵌入似乎很好地捕捉了情感信息:与InferSent和Universal Sentence Encoder相比,SentEval在所有情感任务(MR、CR和SST)上表现出显著提升。
在TREC数据集上,SBERT明显不如Universal Sentence Encoder。Universal Sentence Encoder在预训练阶段使用了问答数据,这似乎对TREC数据集的问答类型分类任务有利。
对于各种STS任务(见表1),BERT的平均嵌入和BERT的CLS-token输出表现不佳,甚至不如平均的GloVe嵌入。然而,在SentEval中,BERT的平均嵌入和CLS-token输出表现良好(见表5),优于平均GloVe嵌入。这是因为不同的设置。在STS任务中,我们使用余弦相似度来估计句子嵌入之间的相似性,这假设所有维度平等。相比之下,SentEval使用逻辑回归分类器对句子嵌入进行拟合,允许某些维度对分类结果产生更大或更小的影响。
总结来说,BERT的平均嵌入/CLS-token输出生成的句子嵌入不适合与余弦相似度或曼哈顿/欧几里得距离直接使用。在迁移学习中,它们的表现略逊于InferSent或Universal Sentence Encoder。然而,通过使用描述的基于siamese网络结构的微调设置在NLI数据集上,SBERT产生了SentEval工具包的新状态-of-the-art句子嵌入。
消融实验(仅仅给出了实验结果,并未对结果进行分析)
针对不同的pooling方式和不同的特征拼拼接方式进行了笑容实验研究。
池化方面,在NLI数据集上,采用平均池化效果最好,其他两种方式有所下降但是不显著。在STSB数据集上,平均池化和CLS池话效果相差不大,但是最大池化效果出现了明显下降。
在特征拼接方面,单独使用==$u * v$====效果最好,联合使用 ====$|u-v|$==的鲁棒性最好,和哪种方式结合都能够提升最后的效果。
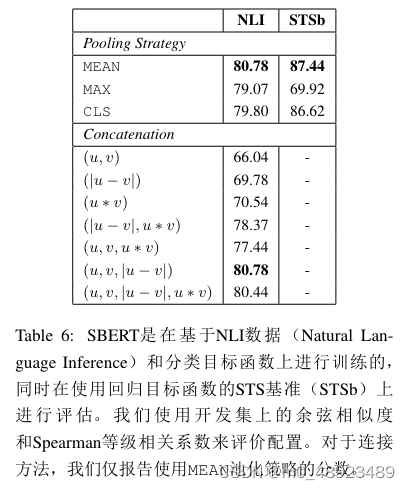
我们已经展示了SBERT句子嵌入的强大实证结果。在本节中,我们对SBERT的不同方面进行了消融研究,以更好地理解它们的相对重要性。
我们评估了不同的池化策略(MEAN、MAX和CLS)。对于分类目标函数,我们评估了不同的拼接方法。对于每种可能的配置,我们使用10个不同的随机种子训练SBERT,并计算性能的平均值。
目标函数(分类还是回归)取决于标注的数据集。对于分类目标函数,我们在SNLI和Multi-NLI数据集上训练SBERTbase。对于回归目标函数,我们在STS基准数据集的训练集上进行训练。性能在STS基准数据集的开发集上进行评估。结果见表6。
当使用分类目标函数在NLI数据上训练时,池化策略的影响相对较小。连接模式的影响要大得多。InferSent(Conneau et al., 2017)和Universal Sentence Encoder(Cer et al., 2018)都使用(u, v, |u − v|, u · v)作为softmax分类器的输入。然而,在我们的架构中,添加元素级的u · v会降低性能。
最重要的组件是元素级的差分|u − v|。请注意,连接模式仅在训练softmax分类器时相关。在推理阶段,当预测STS基准数据集的相似度时,仅使用句子嵌入u和v,结合余弦相似度。元素级的差分衡量两个句子嵌入维度之间的距离,确保相似对更接近,不相似对更远。
当使用回归目标函数训练时,我们观察到池化策略有较大影响。在这种情况下,MAX策略的表现明显劣于MEAN或CLS-token策略。这与Conneau等人的研究结果相反,他们发现InferSent的双向LSTM层使用MAX池化优于MEAN池化。
总结:
改文章为了解决相似文本对的快速搜索问题,提出了一种基于孪生网络的有监督训练分类训练,目的是帮助模型获得有效的句子特征。实验结果表明了该方法的有效性,改论文数据比较老的论文,现在普遍采用的方式都是基于对比学习的方式。
消融实验仅仅给出了实验结果,并未对结果进行分析。算是科普了几种方法吧。