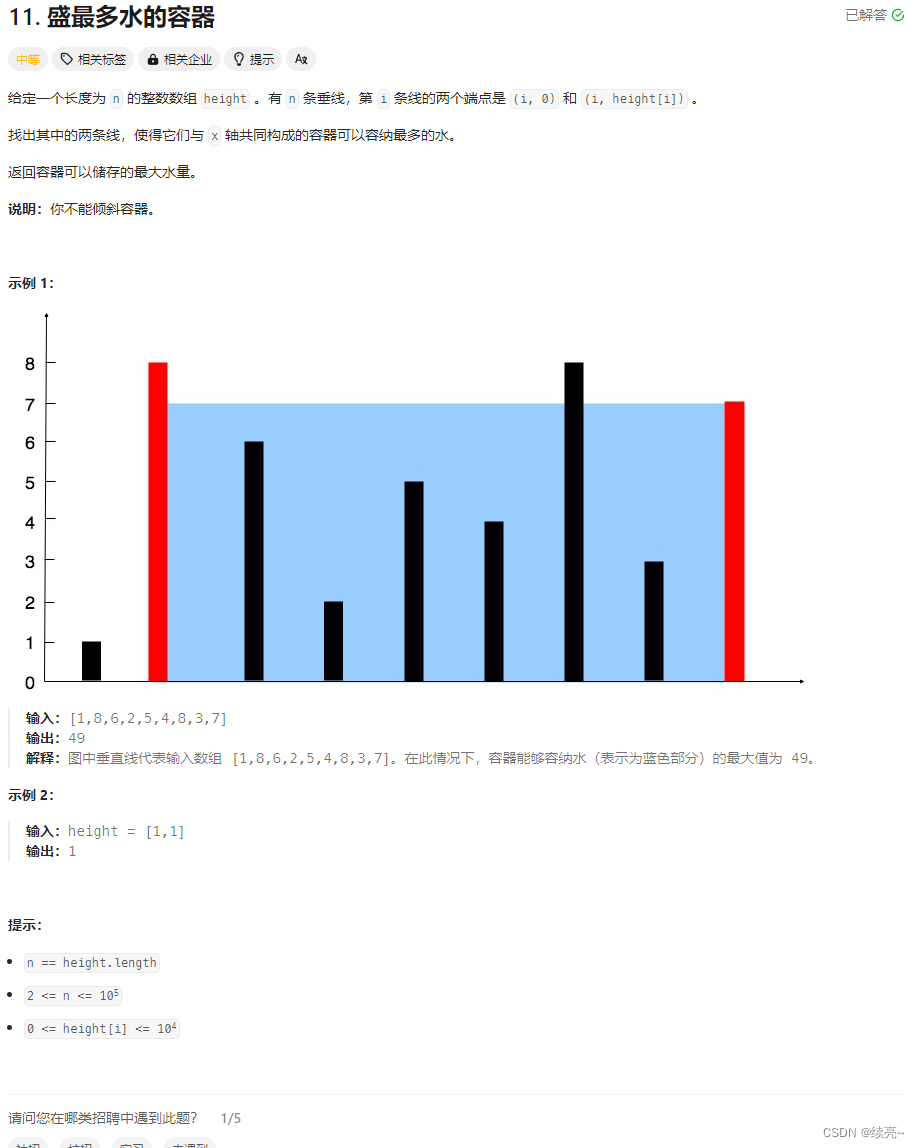
成语是汉语中的一种特殊表达形式,而语序成语则更加特殊,需要通过特定的语序才能表达其含义。在这篇文章中,我们将使用简单的神经网络来识别具有特定语序的成语。
首先,我们定义了一个数据集,其中包含了一些语序成语和非语序成语的例子:
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
# 定义数据集
sentences = [
'鱼水情深',
'水鱼情深',
'风和日丽',
'日和风丽'
]
labels = np.array([1, 1, 0, 0]) # 1代表含有语序成语,0代表不含
接下来,我们使用Tokenizer将句子转换为序列,并构建词汇表:
# 构建词汇表
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
vocab_size = len(word_index)
# 将句子转换为序列
sequences = tokenizer.texts_to_sequences(sentences)
然后,我们对序列进行填充,使它们的长度相同:
# 填充序列,使其长度相同
max_length = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_length, padding='post')
现在,我们可以构建神经网络模型来识别语序成语。这里我们使用一个简单的Embedding层和一个全连接层:
# 构建模型
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=vocab_size+1, output_dim=16, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(padded_sequences, labels, epochs=10, verbose=2)
更多内容访问网站