babyCoder是一个工作在AI系统的上的工具,它可以根据一些简单的目标写一些短的代码。作为babyagi的一部分,babycoder的目标是为越来越厉害的人工智能agent打下基础,能够生成更大、更复杂的项目。
babycoder主要的目的是为编写代码和修改的代码的AI agent提供一个简单的框架,随着时间的推移,变成一个更通用的系统。
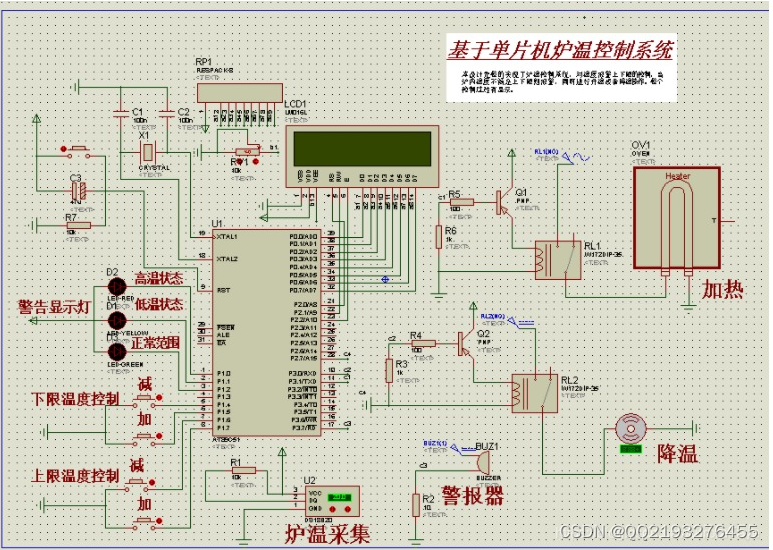
下面是整个babycoder的流程,同样从一个目标开始,然后进行任务创建、任务分解、调用相应的agents,编程代码。

有了之前代码的基础,让我们快速的浏览一遍babycoder的代码。
2. 设定系统参数
这里需要设置几个参数
OPENAI_API_KEYOpenAI的key,没有它基本上跑不了这个项目OPENAI_API_MODEL设定OpenAI的模型,默认是gpt-3.5-turbo,使用gpt-4这里还会告诉你很昂贵objective.txt这个文件存放的目标,再程序的根目录下就行
# Set Variables
load_dotenv()
current_directory = os.getcwd()
os_version = platform.release()
openai_calls_retried = 0
max_openai_calls_retries = 3
# Set API Keys
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
assert OPENAI_API_KEY, "OPENAI_API_KEY environment variable is missing from .env"
openai.api_key = OPENAI_API_KEY
OPENAI_API_MODEL = os.getenv("OPENAI_API_MODEL", "gpt-3.5-turbo")
assert OPENAI_API_MODEL, "OPENAI_API_MODEL environment variable is missing from .env"
if "gpt-4" in OPENAI_API_MODEL.lower():
print(
f"\033[91m\033[1m"
+ "\n*****USING GPT-4. POTENTIALLY EXPENSIVE. MONITOR YOUR COSTS*****"
+ "\033[0m\033[0m"
)
if len(sys.argv) > 1:
OBJECTIVE = sys.argv[1]
elif os.path.exists(os.path.join(current_directory, "objective.txt")):
with open(os.path.join(current_directory, "objective.txt")) as f:
OBJECTIVE = f.read()
assert OBJECTIVE, "OBJECTIVE missing"
2. 辅助函数
在这部分,主要封装了一些常用的函数,包括agents中要执行的tool函数
print_colored_text将一串字符串设置一个颜色,作者这个函数写的可以,终于不会把颜色再在字符串里写了,眼都快瞎了print_char_by_char一个一个字符的打印,可以设置答应字符的间隔和间隔时间openai_call封装的openai请求,这个封装的要比babyagi中的强,大家可以对比阅读下
def print_colored_text(text, color):
color_mapping = {
'blue': '\033[34m',
'red': '\033[31m',
'yellow': '\033[33m',
'green': '\033[32m',
}
color_code = color_mapping.get(color.lower(), '')
reset_code = '\033[0m'
print(color_code + text + reset_code)
def print_char_by_char(text, delay=0.00001, chars_at_once=3):
for i in range(0, len(text), chars_at_once):
chunk = text[i:i + chars_at_once]
print(chunk, end='', flush=True)
time.sleep(delay)
print()
def openai_call(
prompt: str,
model: str = OPENAI_API_MODEL,
temperature: float = 0.5,
max_tokens: int = 100,
):
global openai_calls_retried
if not model.startswith("gpt-"):
# Use completion API
response = openai.Completion.create(
engine=model,
prompt=prompt,
temperature=temperature,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response.choices[0].text.strip()
else:
# Use chat completion API
messages=[{"role": "user", "content": prompt}]
try:
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
n=1,
stop=None,
)
openai_calls_retried = 0
return response.choices[0].message.content.strip()
except Exception as e:
# try again
if openai_calls_retried < max_openai_calls_retries:
openai_calls_retried += 1
print(f"Error calling OpenAI. Retrying {openai_calls_retried} of {max_openai_calls_retries}...")
return openai_call(prompt, model, temperature, max_tokens)
这里我们重点看两个函数
2.1 Agent tool
agents tool指的根据大模型返回的结果,进行执行的函数。也就是说大模型根据目标的分解,自己判断执行那些函数,而不必人再去设置逻辑去执行。
下面就是这样的三个函数
execute_command_json这个函数主要用作执行结果json中的command,这个类似于agent的toolsexecute_command_string这个没什么好说的,跟上面的类似,不过是根据字符串执行命令save_code_to_file将代码保存到文件中
def execute_command_json(json_string):
try:
command_data = json.loads(json_string)
full_command = command_data.get('command')
process = subprocess.Popen(full_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, shell=True, cwd='playground')
stdout, stderr = process.communicate(timeout=60)
return_code = process.returncode
if return_code == 0:
return stdout
else:
return stderr
except json.JSONDecodeError as e:
return f"Error: Unable to decode JSON string: {str(e)}"
except subprocess.TimeoutExpired:
process.terminate()
return "Error: Timeout reached (60 seconds)"
except Exception as e:
return f"Error: {str(e)}"
def execute_command_string(command_string):
try:
result = subprocess.run(command_string, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, shell=True, cwd='playground')
output = result.stdout or result.stderr or "No output"
return output
except Exception as e:
return f"Error: {str(e)}"
def save_code_to_file(code: str, file_path: str):
full_path = os.path.join(current_directory, "playground", file_path)
try:
mode = 'a' if os.path.exists(full_path) else 'w'
with open(full_path, mode, encoding='utf-8') as f:
f.write(code + '\n\n')
except:
pass
重构代码函数
这个函数是将修改后的代码内容替换为当前目录下playground文件夹中的某个文件的要修改内容内容,具体逻辑是获取要修改内容的起始行和结束行,让后将其中的内容替换为修改后的内容,这个要结合后续的prompt内容去看
def refactor_code(modified_code: List[Dict[str, Union[int, str]]], file_path: str):
full_path = os.path.join(current_directory, "playground", file_path)
with open(full_path, "r", encoding="utf-8") as f:
lines = f.readlines()
for modification in modified_code:
start_line = modification["start_line"]
end_line = modification["end_line"]
modified_chunk = modification["modified_code"].splitlines()
# Remove original lines within the range
del lines[start_line - 1:end_line]
# Insert the new modified_chunk lines
for i, line in enumerate(modified_chunk):
lines.insert(start_line - 1 + i, line + "\n")
with open(full_path, "w", encoding="utf-8") as f:
f.writelines(lines)
将代码进行分割
这个函数将代码中的文件按照chunk_size分割开,并安装以下格式放到字典中
start_line代码开始的行数end_line代码结束的行数code存放代码
def split_code_into_chunks(file_path: str, chunk_size: int = 50) -> List[Dict[str, Union[int, str]]]:
full_path = os.path.join(current_directory, "playground", file_path)
with open(full_path, "r", encoding="utf-8") as f:
lines = f.readlines()
chunks = []
for i in range(0, len(lines), chunk_size):
start_line = i + 1
end_line = min(i + chunk_size, len(lines))
chunk = {"start_line": start_line, "end_line": end_line, "code": "".join(lines[i:end_line])}
chunks.append(chunk)
return chunks
以上就是babycoder中的配置和通用类,包括agent调用的tool的函数,从以上我们可以看到,一个不用langchian的项目是如何编写的。
下一篇我们将看到,如何使用prompt操作这些tool函数,完成代码编写的任务