llamafactory是什么,能干什么
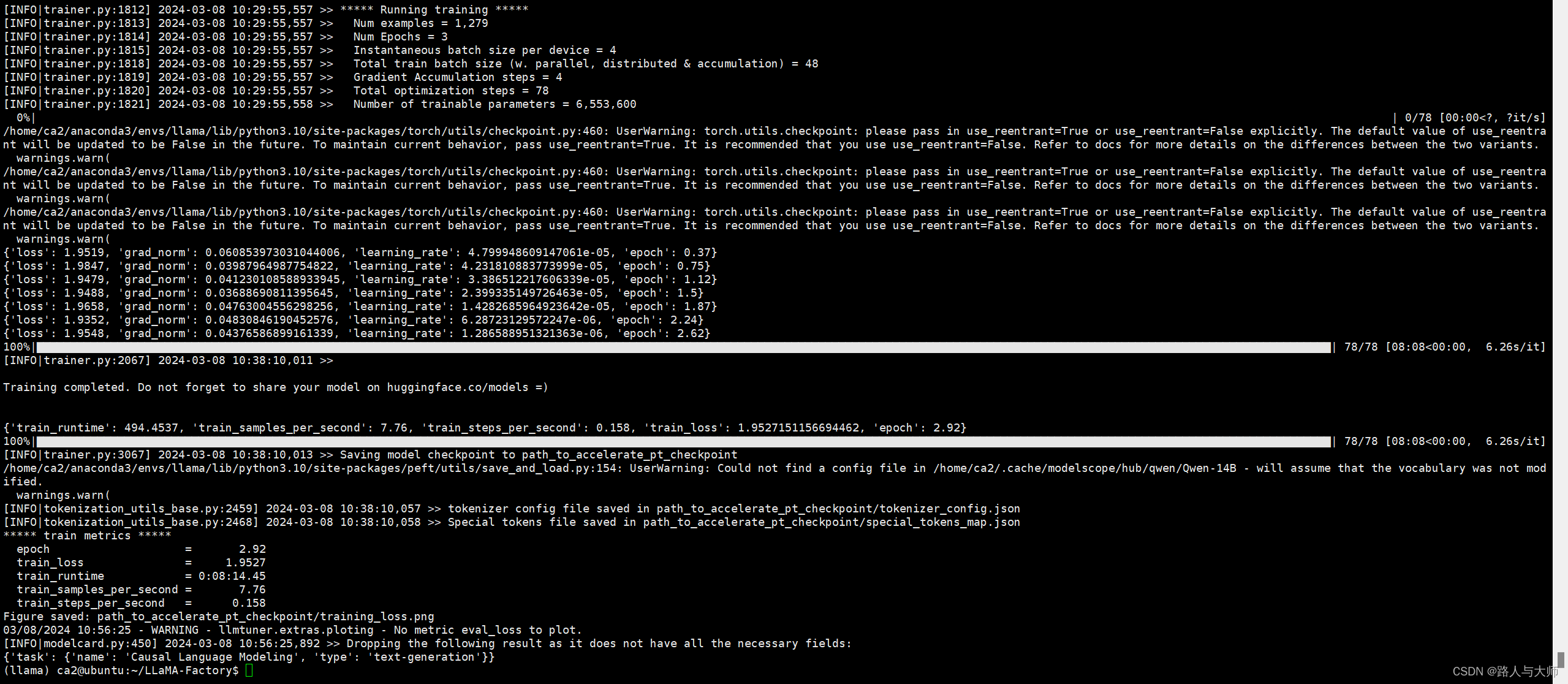
LLaMA-Factory 是一个易于使用的大规模语言模型(Large Language Model, LLM)微调框架,它支持多种模型,包括 LLaMA、BLOOM、Mistral、Baichuan、Qwen 和 ChatGLM 等。该框架旨在简化大型语言模型的微调过程,提供了一套完整的工具和接口,使得用户能够轻松地对预训练的模型进行定制化的训练和调整,以适应特定的应用场景。
llamafactory支持哪些模型,支持哪些微调技术
多种模型:LLaMA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
集成方法:(增量)预训练、指令监督微调、奖励模型训练、PPO 训练、DPO 训练和 ORPO 训练。
多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
先进算法:GaLore、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ 和 Agent 微调。
实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口
部分支持的模型:
模型名 |
模型大小 |
默认模块 |
Template |
7B/13B |
W_pack |
baichuan2 |
|
560M/1.1B/1.7B/3B/7.1B/176B |
query_key_value |
- |
|
560M/1.1B/1.7B/3B/7.1B/176B |
query_key_value |
- |
|
6B |
query_key_value |
chatglm3 |
|
7B/16B/67B |
q_proj,v_proj |
deepseek |
|
7B/40B/180B |
query_key_value |
falcon |
|
2B/7B |
q_proj,v_proj |
gemma |
|
7B/20B |
wqkv |
intern2 |
|
7B/13B/33B/65B |
q_proj,v_proj |
- |
|
7B/13B/70B |
q_proj,v_proj |
llama2 |
|
7B |
q_proj,v_proj |
mistral |
|
8x7B |
q_proj,v_proj |
mistral |
|
1B/7B |
att_proj |
olmo |
|
1.3B/2.7B |
q_proj,v_proj |
- |
|
1.8B/7B/14B/72B |
c_attn |
qwen |
|
0.5B/1.8B/4B/7B/14B/72B |
q_proj,v_proj |
qwen |
|
3B/7B/15B |
q_proj,v_proj |
- |
|
7B/13B/65B |
q_proj,v_proj |
xverse |
|
6B/9B/34B |
q_proj,v_proj |
yi |
|
2B/51B/102B |
q_proj,v_proj |
yuan |
训练方法
方法 |
全参数训练 |
部分参数训练 |
LoRA |
QLoRA |
预训练 |
✅ |
✅ |
✅ |
✅ |
指令监督微调 |
✅ |
✅ |
✅ |
✅ |
奖励模型训练 |
✅ |
✅ |
✅ |
✅ |
PPO 训练 |
✅ |
✅ |
✅ |
✅ |
DPO 训练 |
✅ |
✅ |
✅ |
✅ |
ORPO 训练 |
✅ |
✅ |
✅ |
✅ |
数据集请参考:
LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory · GitHub
参考:LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory · GitHub
llamafactory如何加载训练数据,对模型存储有哪些约束
模型加载都是通过命令行指定的
model_name_or_path: Path to the model weight or identifier from huggingface.co/models or modelscope.cn/models.
训练数据 是指定名称,位置放在项目的data目录下
dataset--the name of provided dataset(s) to use. Use commas to separate multiple datasets.
dataset_dir--Path to the folder containing the datasets.
llamafactory的模型评估具备哪些能力
有专门的一个评估类Evaluator,可以通过脚本运行评估
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py \ --model_name_or_path path_to_llama_model \ --adapter_name_or_path path_to_checkpoint \ --template vanilla \ --finetuning_type lora \ --task mmlu \ --split test \ --lang en \ --n_shot 5 \ --batch_size 4
每次微调有记录吗
没有记录,都是调用的命令行
可以定时训练吗
没有定时训练能力
是否有量化能力
有的,CUDA_VISIBLE_DEVICES=0, --export_quantization_bit 4 导出量化模型