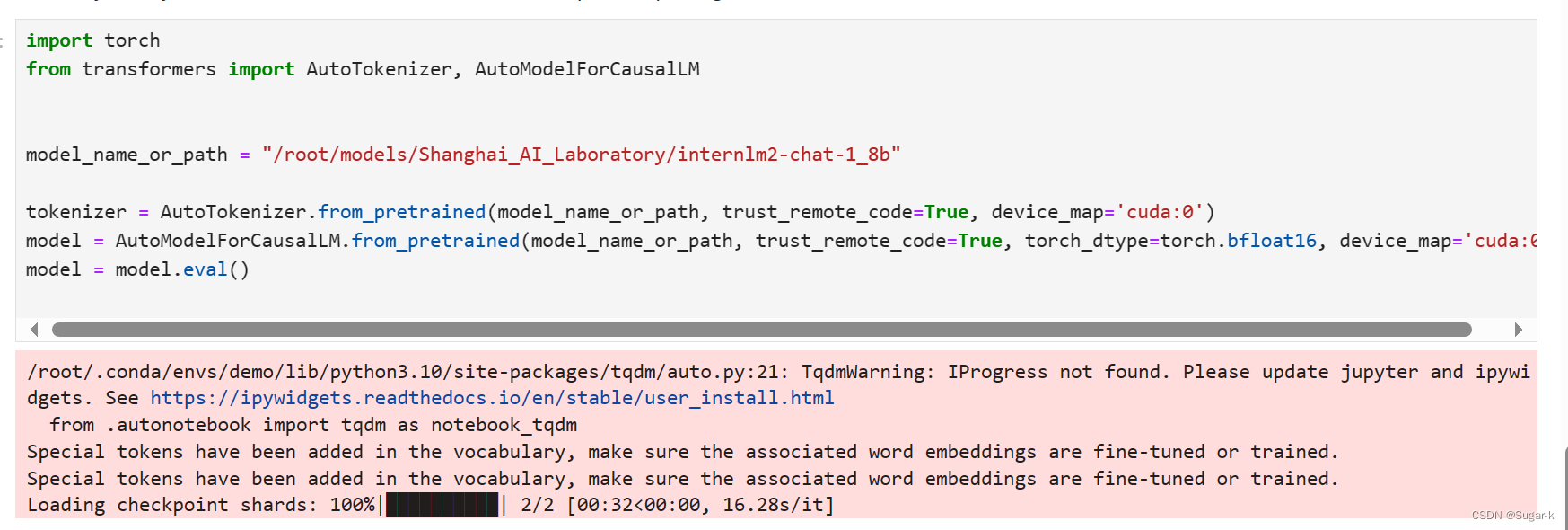
缘由
近段有个有趣想法:如果在一个二维的画布上画上三角形和四边形,AI可以将这些简单图形区别开么?
问题分析
初分析来看,觉得此问题虽然看似简单,但可能还是存在一些难度。 例如,如果有些三角形,实际上是四边形内部的三角形时,是不是AI学习器也很不好区分?
再深入分析下去,首先遇到的问题,就是如何要对此二分类问题产生大量的三角形和四边形数据。
这些数据首先要具有随机性,次之还要避免重复,再者要避免成为一条直线,觉得还是稍微复杂了点。
那么能否采用较为简单的场景呢,因为三角形和四边形都具有顶点,问题可以简化为几个表达特征的顶点即可。
想到一般在送入学习器前,都需要将二维数据转化为向量数据,那么实际上这个问题可以进一步简化为向量中非零的个数问题。
但对于要试验的问题,未从理论上进行分析和确认,仅在直观上来看,似乎差距并不是很大。四个顶点信息,通常蕴含或内嵌一些三个顶点信息,所以,AI将其区分开,可能也没有那么简单。
是否线性问题分析
在一个向量中非零元素的个数,这个问题从理论上而言,是一个线性问题,因为仅需要o(N)复杂度就可以将这个问题解决。
如果AI可以学得计算某一个向量的计算非零元素个数的算法,就可以将这个问题解决。
AI试验
对于自己来讲,比较熟悉的还是OpenCV SVM技术手段。虽然,在技术原理上,SVM支持向量机用超平面的办法来区分不同的分类,可能对于计算向量非零元素个数的概念拟合的不够好,但不正好可以借助这个问题,试试SVM支持向量机AI的能力。
如果在这个问题上SVM能力欠缺,则准备试验CNN神经网络学习器试试
结论先行
最终试验来看,SVM支持向量机可以很好地解决问题,甚至在对于不可见数据,例如,二分类之外,其它的非零个数向量数据,也能够区分的相当棒
试验准备
在一个向量中选择非零元素的位置是一个顺序无关的组合问题,所以,可以粗略计算某一个非零量级向量集合的规模数据。
在阅读《西瓜书.机器学习》书籍时谈到分类问题中类别不平衡的问题,所以,在产生数据集时,需要选择空间规模大致一致的非零个数向量数据。
同时,因为随机性的存在,对于某一非零个数向量,粗略按照其空间个数的的十倍进行采样数据。
不可见数据的试验
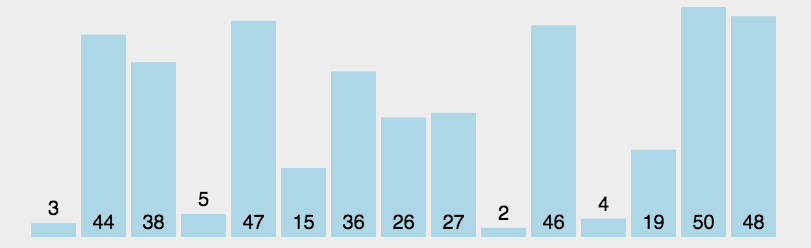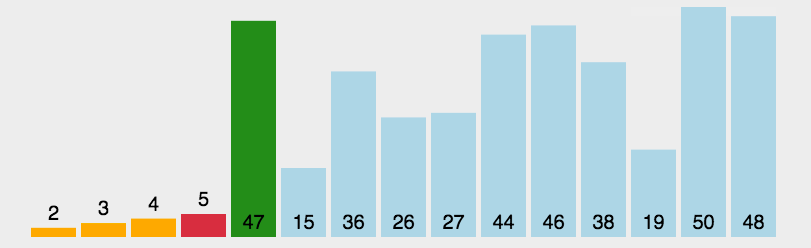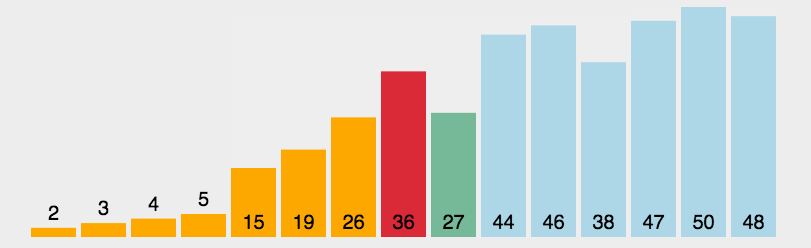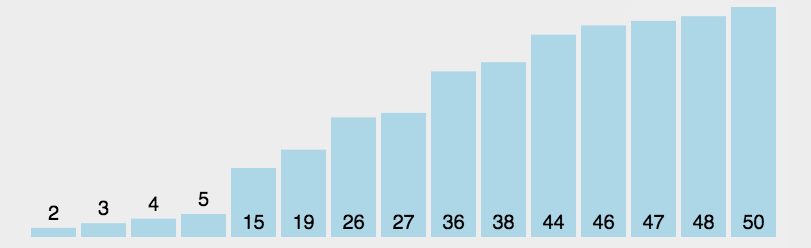
对于选定的两个量级的非零元素个数后,其它非零元素个数的向量,那么其实可以作为不可见数据,对于这些不可见数据,恰好可以测试模型的泛化能力。
原来想着对于这些不可见数据,模型针对于某一非零元素个数的向量预测的成功率可能是对错参半,但,实际上以形成模型的量级为楚河汉界,归为二分类的其中某一类了。
AI的能耐
- 回归、分类、统计概率分布可以认为是AI的最基本的能力
- 马尔可夫过程智能生成最大可能性数据序列,例如,语音识别
- 以关键词为代表的搜索引擎,将很快替换为以chatGPT为代表的搜索技术
从信息论观点来看,交流式搜索,将提供更多的信息输入,更有助于搜索引擎梦寐以求的用户信息,来消除不确定性
- 生成式智能,技术原理待补