一、继承有哪些方式?以及优缺点
继承的方式包括原型链继承、构造函数继承、组合继承、原型式继承、寄生式继承和组合式继承。
1.原型链继承:
- 实现方式:将子类的原型指向父类的实例来实现继承。
- 优点:简单易懂,代码量少。
- 缺点:存在引用类型共享的问题。
function Parent() { this.name = 'Parent'; } Parent.prototype.sayHello = function() { console.log('Hello from Parent'); } function Child() { this.age = 10; } Child.prototype = new Parent(); Child.prototype.constructor = Child; var child = new Child();2.构造函数继承:
- 实现方式:在子类构造函数中调用父类构造函数,通过apply或call方法继承父类属性。
- 优点:避免了引用类型共享的问题。
- 缺点:无法继承父类原型链上的方法
function Parent(name) { this.name = name; } function Child(name, age) { Parent.call(this, name); this.age = age; } var child = new Child('Child', 10);3.组合继承:
- 实现方式:结合原型链继承和构造函数继承的方式。
- 优点:兼具原型链继承和构造函数继承的优点。
- 缺点:调用了两次父类构造函数,存在父类属性重复的问题。
function Parent(name) { this.name = name; } Parent.prototype.sayHello = function() { console.log('Hello from Parent'); } function Child(name, age) { Parent.call(this, name); this.age = age; } Child.prototype = new Parent(); Child.prototype.constructor = Child; var child = new Child('Child', 10);4.原型式继承:
- 实现方式:通过一个空函数作为中介,将一个对象作为另一个对象的原型。
- 优点:简单易用。
- 缺点:存在引用类型共享的问题。
var parent = { name: 'Parent', sayHello: function() { console.log('Hello from Parent'); } }; var child = Object.create(parent); child.age = 10;5.寄生式继承:
- 实现方式:在原型式继承的基础上,在函数内部增强对象,返回新对象。
- 优点:可以对对象进行增强。
- 缺点:存在引用类型共享的问题。
function createChild(parent) { var child = Object.create(parent); child.age = 10; return child; } var parent = { name: 'Parent', sayHello: function() { console.log('Hello from Parent'); } }; var child = createChild(parent);6.组合式继承:
- 实现方式:组合使用构造函数继承和寄生式继承。
- 优点:避免了父类构造函数被调用两次的问题。
- 缺点:相对复杂。
function Parent(name) { this.name = name; } Parent.prototype.sayHello = function() { console.log('Hello from Parent'); } function Child(name, age) { Parent.call(this, name); this.age = age; } Child.prototype = Object.create(Parent.prototype); Child.prototype.constructor = Child; var child = new Child('Child', 10);
二、缓存策略有哪些?
1.浏览器缓存
*(1)强缓存:
通过设置响应头中的
Cache-Control和Expires字段来控制缓存策略,使浏览器直接从本地缓存获取资源,不发送请求到服务器。*(2)协商缓存:
通过设置响应头中的
Last-Modified和ETag字段来控制缓存策略,当资源过期时,浏览器发送请求到服务器验证资源是否有更新,如果未更新则返回304状态码,浏览器使用本地缓存。2.CDN缓存:
CDN(内容分发网络)可以缓存静态资源,加速资源加载速度。CDN节点会根据资源的URL来判断是否命中缓存,如果命中则直接返回缓存的资源,减少请求到源服务器的次数。
3.Service Worker缓存:
·Service Worker是浏览器中的一种脚本,可以拦截和处理网络请求。开发者可以通过Service Worker来实现自定义的缓存策略,例如将请求结果缓存到IndexedDB或Cache Storage中,实现离线访问和更灵活的缓存控制。
4.内存缓存:
在前端开发中,可以使用内存缓存来存储一些临时数据,例如在页面间传递数据或存储一些频繁使用的数据,以提高访问速度。
5.HTTP缓存控制:
通过设置HTTP响应头中的
Cache-Control、Expires、Pragma、ETag、Last-Modified等字段,可以控制浏览器和代理服务器的缓存行为,从而优化资源加载速度。6.数据库缓存:
对于需要频繁读取的数据,可以将其缓存到本地数据库(如IndexedDB、WebSQL等)中,减少对服务器的请求,提高数据加载速度。
三、url输入到渲染全过程
1.URL解析:
当用户在浏览器地址栏输入URL时,浏览器会对URL进行解析,包括解析协议、域名、端口号、路径等信息。
2.DNS解析:
浏览器需要将域名解析为对应的IP地址,以便向服务器发送请求。如果在本地缓存中找不到对应的IP地址,浏览器会向DNS服务器发送请求进行解析。
3.建立TCP连接:
浏览器通过TCP协议与服务器建立连接,包括三次握手的过程。
4.发送HTTP请求:
浏览器向服务器发送HTTP请求,请求资源文件(如HTML、CSS、JavaScript、图片等)。
5.服务器处理请求:
服务器接收到请求后,根据请求的资源类型和路径进行处理,可能需要读取数据库、执行后端代码等操作。
6.返回HTTP响应:
·服务器将处理结果封装成HTTP响应返回给浏览器,响应包括状态码、响应头和响应体。
7.浏览器接收响应:
浏览器接收到服务器返回的响应后,根据响应头中的信息进行处理,包括判断是否命中缓存、解析响应体等。
8.解析HTML:
浏览器解析HTML文件,构建DOM树。
9.加载资源:
浏览器根据HTML中的链接和脚本标签,加载对应的CSS、JavaScript等资源文件。
10.构建渲染树:
浏览器将DOM树和CSS样式表结合起来,构建渲染树。
11.布局和绘制:
浏览器根据渲染树进行布局(计算元素的位置和大小)和绘制(绘制像素到屏幕上)。
12.页面渲染完成:
当所有资源加载完成、布局和绘制完成后,页面渲染完成,用户可以看到页面内容。
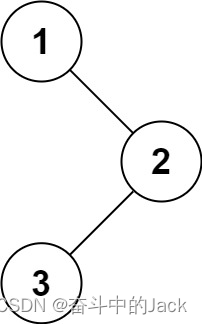
四、【算法】 二叉树中序遍历
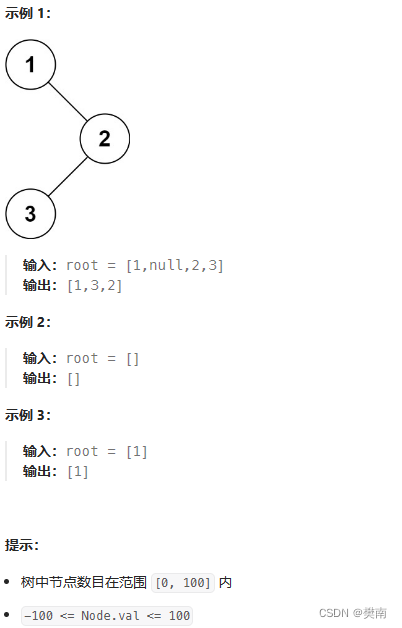
1.题目:
给定一个二叉树的根节点
root,返回 它的 中序 遍历 。
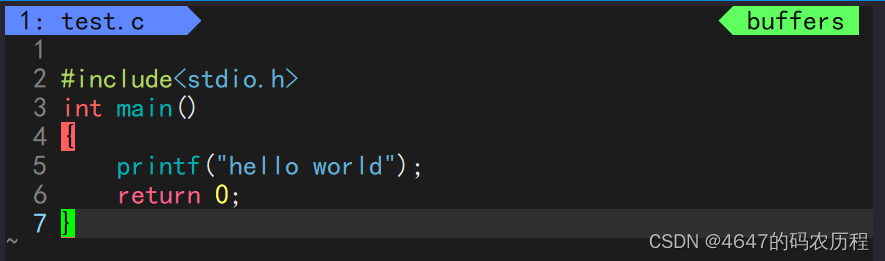
/** * Definition for a binary tree node. * struct TreeNode { * int val; * struct TreeNode *left; * struct TreeNode *right; * }; */ /** * Note: The returned array must be malloced, assume caller calls free(). */ int* inorderTraversal(struct TreeNode* root, int* returnSize) { }2.解题:
中序遍历的思路是先遍历左子树,然后访问根节点,最后遍历右子树。因此,我们可以通过递归的方式实现中序遍历:递归遍历左子树,访问当前节点,再递归遍历右子树。
在实现函数时,我们可以先判断根节点是否为空,若为空则返回空数组;然后创建一个足够大的数组来存储遍历结果;接着定义一个辅助函数来进行递归中序遍历,并在每次访问节点时将节点的值存入数组;最后返回存储遍历结果的数组,并更新返回大小
/** * Definition for a binary tree node. * struct TreeNode { * int val; * struct TreeNode *left; * struct TreeNode *right; * }; */ /** * Note: The returned array must be malloced, assume caller calls free(). */ void inorder(struct TreeNode* root, int* result, int* index) { if (root == NULL) { return; } inorder(root->left, result, index); result[(*index)++] = root->val; inorder(root->right, result, index); } int* inorderTraversal(struct TreeNode* root, int* returnSize) { if (root == NULL) { *returnSize = 0; return NULL; } int* result = (int*)malloc(sizeof(int) * 1000); // 假设最多有1000个节点 int index = 0; inorder(root, result, &index); *returnSize = index; return result; }

























![[html]基础知识点汇总](https://img-blog.csdnimg.cn/direct/25af7f9a08d2405f99d5b1205ff4d618.png)