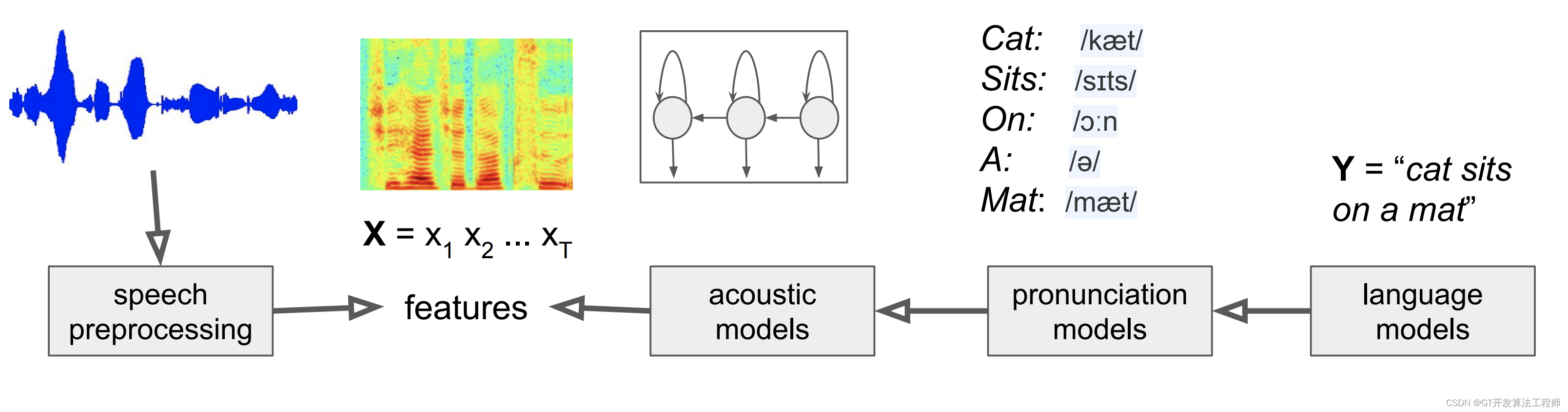
HMM语音识别的解码过程
从麦克风采集的输入音频波形被转换为固定尺寸的一组声学向量:
其中是
维的语音特征向量(例如MFCC)。
解码器尝试去找到上述特征向量序列对应的单词(word)的序列:
单词序列的长度是。
也即是解码器尝试寻找模型产生的那个最有可能的单词序列
:
经过贝叶斯公式:
似然概率是语音识别的声学模型,先验概率
是语音模型。
是一个单词由基本音素组成的发音序列(也就是单词的音标),
是该句子的一个可能发音序列,由该句子的每个单词的基本音素拼接而成。
这里的求和是使用了全概率公式,因为一个单词可能由多个发音,所以句子的发音序列也是多个。
对于该句子的一个可能发音序列,可得
剩下就是计算了。
给定发音序列,对每一个可能的状态序列求句子HMM的概率。
是特征序列对应的一个候选的状态序列。
解码过程不需要计算所有可能状态序列的似然概率,我们只需要使用维特比(Viterbi)算法获取概率最大的那个状态序列路径。
模型参数:
![]()
HMM语音识别声学模型的训练过程(单音素)
个语料片段,每个语料片段对应的特征向量序列为
,
序列的长度为
,
HMM的训练(选择正确的参数)意味着:找到模型的参数(如转移概率和发射概率),使得给定的所有输入语料的概率最大:
关于,
E-step
前向概率:
即对的前
个特征向量与
时刻的状态为
的联合概率;
后向概率:
给定时刻的状态为
,模型生成
+1到
之间的特征向量序列的条件概率。

给定前向和向后的概率,对于任何给定的语料,模型在时间
时占据状态
的概率是
![]()
其中,可通过前向概率或者后向概率的递推公式获得,等于
时刻的前向概率,也等于
时刻的后向概率。
M-step
对于所有的语料,给定初始的模型参数(均值,方差,转移概率),可通过如下的公式迭代参数
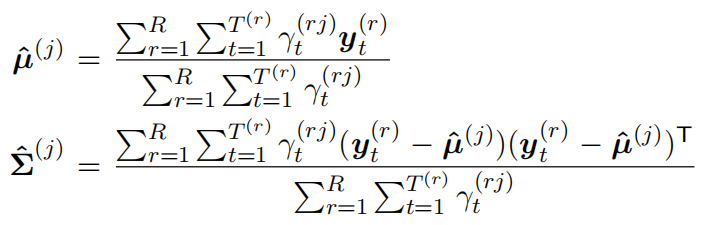
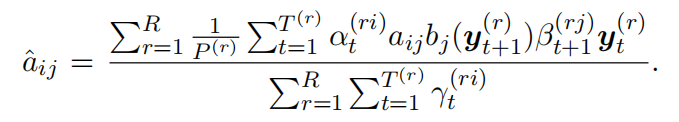
注意,这里使用的是单个高斯分布建模观察概率而不是GMM。
Kaldi中使用的HMM声学模型训练方法
因为转移概率对识别结果的影响很小,甚至有时候可以忽略。Kaldi中一般是将转移概率固定不变,不在训练中更新转移概率。声学模型包含的信息主要是状态定义和各个状态的观察概率(发射概率)分布。
使用从左到右的线性HMM模型结构(只有向右跳转和自跳转),训练过程中只更新每个状态的高斯混合模型(GMM)参数。
上面介绍的HMM训练方法是经典的训练HMM的方法(baum welch算法),该算法就是在给定一个初始的模型参数,通过不断的E-step,M-step迭代模型的参数。一种更加实际的方法是使用Viterbi训练方法:
1、给定初始的参数
2、使用维特比算法和当前的参数找到能够解释
的最可能的状态序列
,这样就得到了每一帧
对应的状态。这个过程也叫做对齐(Align)或者强制对齐(Forced alignment),目的是获取每一帧对应的状态。
3、使用统计公式更新模型的参数。因为此时已经有大量已知隐藏状态和特征(观察值)的帧,所以可以更新每个状态对应的发射概率分布(GMM)的均值和协方差以及权重等参数(可能会用到GMM的EM算法估计GMM的参数)
4、重复步骤2、3,直到状态序列不再更新(收敛)。
参考: