文章目录
- 一、cmakelist
- 二、c/c++
- 三、Socket编程
- 四、计时
- 五、ELF
- 六、linux查看动态链接库地址
- 七、assert
- 八、C标准库宏
- 代码结构
一、cmakelist
SET
set方法是cmake-commands中的脚本方法,用于给下面的变量设置值:
- 一般变量(Set Normal Variable)
set(<variable> <value>... [PARENT_SCOPE])
variable:只能有一个
value:可以有0个,1个或多个,当value值为空时,方法同unset,用于取消设置的值
PARENT_SCOPE(父作用域):作用域,除PARENT_SCOPE外还有function scope(方法作用域)和directory scope(目录作用域)
- 缓存变量(Set Cache Entry)
set(<variable> <value>... CACHE <type> <docstring> [FORCE])
variable:只能有一个
value:可以有0个,1个或多个,当value值为空时,方法同unset,用于取消设置的值
CACHE:关键字,说明是缓存变量设置
type(类型):必须为以下中的一种:
BOOL:有ON/OFF,两种取值
FILEPATH:文件的全路径
PATH:目录路径
STRING:字符串
INTERNAL:字符串
docstring:总结性文字(字符串)
[FORCE]:变量名相同,第二次调用set方法时,第一次的value将会被覆盖
- 环境变量(Set Environment Variable)
set(ENV{<variable>} [<value>])
variable:只能有一个
value:一般来说,只有一个,为空时,将清除之前设置的变量值,多个时,取值最近的一个,之后的值将被忽略
OPTION
CMake中的option用于控制编译流程,相当于C语言中的宏条件编译
option(<variable> "<help_text>" [value])
variable:定义选项名称
help_text:说明选项的含义
value:定义选项默认状态,一般是OFF或者ON,除去ON之外,其他所有值都为认为是OFF。
option起到编译开关的作用,CMakeLists.txt中option以前的语句,变量按未定义处理,option之后的语句,变量才被定义。
二、c/c++
int main(int argc,char** argv)
int main(int argc,char** argv)
{
}
D:\tc2>test
这个时候,argc的值是1,argv[0]的值是 “test”
D:\tc2>test myarg1 myarg2
这个时候,argc的值是3,argc[0]的值是”test”,argc[1]的值是”myarg1”,argc[2]的值是”myarg2”。
这个赋值过程是编译器完成的,我们只需要读出数据就可以了。
argc 是 argument count的缩写,表示传入main函数的参数个数;
argv 是 argument vector的缩写,表示传入main函数的参数序列或指针,并且第一个参数argv[0]一定是程序的名称,并且包含了程序所在的完整路径.
argv是指向指针的指针,main函数的第二个参数“char *argv[]“也可以替换为 “char **argv“,两者是等价的。
printf
| 符号 | 含义 |
|---|---|
| %d | 输出一个整数值,并将其按照十进制形式显示 |
| %f | 输出一个浮点数值,并将其按照默认精度(通常为小数点后6位)显示 使用 .nf 来指定浮点数的精度,其中 n 是一个正整数 |
| %s | 输出一个字符串值 使用 .ns(其中 n 是一个正整数)来指定最大字符数。例如,%.10s 将限制输出的字符串最多为 10 个字符,10个字符包含结尾的空字符(\0) |
| %u | 输出一个无符号整数值,并将其按照十进制形式显示。 |
| %hu | 输出一个无符号短整数值,并将其按照十进制形式显示 |
| %#X | 输出一个整数值的十六进制表示 |
| %c | 输出一个字符 |
单例模式:
if(!instance)
instance = new xxx
通过单例模式, 可以做到:
1. 确保一个类只有一个实例被建立
2. 提供了一个对对象的全局访问指针
3. 在不影响单例类的客户端的情况下允许将来有多个实例
参考:https://blog.csdn.net/unonoi/article/details/121138176?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-121138176-blog-109306230.235%5Ev40%5Epc_relevant_3m_sort_dl_base3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-121138176-blog-109306230.235%5Ev40%5Epc_relevant_3m_sort_dl_base3&utm_relevant_index=2
静态局部变量的懒汉单例(C++11线程安全)
头文件:
/// 内部静态变量的懒汉实现 //
class Single
{
public:
// 获取单实例对象
static Single& GetInstance();
// 打印实例地址
void Print();
private:
// 禁止外部构造
Single();
// 禁止外部析构
~Single();
// 禁止外部拷贝构造
Single(const Single &single) = delete;
// 禁止外部赋值操作
const Single &operator=(const Single &single) = delete;
};
源文件:
Single& Single::GetInstance()
{
/**
* 局部静态特性的方式实现单实例。
* 静态局部变量只在当前函数内有效,其他函数无法访问。
* 静态局部变量只在第一次被调用的时候初始化,也存储在静态存储区,生命周期从第一次被初始化起至程序结束止。
*/
static Single single;
return single;
}
void Single::Print()
{
std::cout << "我的实例内存地址是:" << this << std::endl;
}
Single::Single()
{
std::cout << "构造函数" << std::endl;
}
Single::~Single()
{
std::cout << "析构函数" << std::endl;
}
static
https://blog.csdn.net/weixin_45031801/article/details/134215425
宏定义
#define 定义一个预处理宏
#undef 取消宏的定义
#if 编译预处理中的条件命令,相当于C语法中的if语句
#ifdef 判断某个宏是否被定义,若已定义,执行随后的语句
#ifndef 与#ifdef相反,判断某个宏是否未被定义
#elif 若#if, #ifdef, #ifndef或前面的#elif条件不满足,则执行#elif之后的语句,相当于C语法中的else-if
#else 与#if, #ifdef, #ifndef对应, 若这些条件不满足,则执行#else之后的语句,相当于C语法中的else
#endif #if, #ifdef, #ifndef这些条件命令的结束标志.
defined 与#if, #elif配合使用,判断某个宏是否被定义
define
https://www.jianshu.com/p/e9f00097904a
#表示字符串化操作符(stringification)。其作用是:将宏定义中的传入参数名转换成用一对双引号括起来参数名字符串。其只能用于有传入参数的宏定义中,且必须置于宏定义体中的参数名前。说白了,他是给x加双引号:
字符串拼接
#define S1 "hello"
#define S2 "world"
#define STR1 S1 S2
#define STR2 "/" S1 " the " S2 "/" // 或者"/"S1" the "S2"/"
printf("STR1 = %s\n", STR1);
printf("STR2 = %s\n", STR2);
output:
STR1 = helloworld
STR2 = /hello the world/
void*
void的字面意思是“无类型”,void* 则为“无类型指针”,void *可以指向任何类型的数据。
如果指针p1和p2的类型相同,那么我们可以直接在p1和p2间互相赋值;如果p1和p2指向不同的数据类型,则必须使用强制类型转换运算符把赋值运算符右边的指针类型转换为左边指针的类型。
float *p1;
int *p2;
p1 = p2; 错
p1 = (float *)p2;对
而void *则不同,任何类型的指针都可以直接赋值给它,无需进行强制类型转换:
void *p1;
int *p2;
p1 = p2;
函数传参
https://blog.csdn.net/qq_45487715/article/details/108796609
int a :一个int类型,名称叫a
int* a:一个整形的指针,名称叫a
int *a:一个指向整型的地址,名称叫a(一级指针,表示a所指向的地址里面存放的是一个int类型的值)
int **a :二级指针,表示a所指向的地址里面存放的是一个指向int类型的指针(即a指向的地址里面存放的是一个指向int的一级指针)
int & a:声明一个int引用类型,名称叫a
strcmp
strcmp(字符串1,字符串2)
说明:
当s1<s2时,返回为负数 注意不是-1
当s1==s2时,返回值= 0
当s1>s2时,返回正数 注意不是1
int sscanf(const char *str, const char * format, ...);
char c;
if(sscanf(argv[i],"-d%c",&c)==1)
gDebugLevel = c - '0';
sscanf()定义于头文件stdio.h。sscanf()会将参数str的字符串根据参数format字符串来转换并格式化数据。格式转换形式请参考scanf()。转换后的结果存于对应的参数内。如果您想要把 sscanf 操作的结果存储在一个普通的变量中,您应该在标识符前放置引用运算符(&)
返回值
成功则返回参数数目,失败则返回-1(也即EOF)。
append()
https://blog.csdn.net/weixin_42258743/article/details/107964192
1.在字符串的末尾添加字符串str。
string& append (const string& str);
string& append (const char* s);
4.在字符串的末尾添加n个字符c;
string& append (size_t n, char c);
string s1 = "hello";
s1.append(3, '!'); //在当前字符串结尾添加3个字符!
运行结果为 s1 = "hello!!!";
free()
ifstream fstream

当我们使用#include 时,我们就可以使用其中的 ifstream,ofstream以及fstream 这三个类了(ofstream是从内存到硬盘,ifstream是从硬盘到内存),也就可以用这三个类来定义相应的对象了,这三个类分别代表一个输入文件,一个输出文件,以及一个输入输出文件。Ifstream类支持>>操作符,ofstream类支持<<操作符,fstream类同时支持>>和<<操作符。
FILE
fopen()
FILE *fopen(const char *filename,const char *mode)
fopen实现三个功能:
为使用而打开一个流
把一个文件和此流相连接
给此流返回一个FILR指针
参数filename指向要打开的文件名,mode表示打开状态的字符串
w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
fprintf()
int fprintf(FILE *stream, const char *format[, argument, ...]);
按格式输入到流,其用法和printf()相同,不过不是写到控制台,而是写到流罢了
fprintf(fp,"-%s",4,"Hahaha");
str.find
std::string 的方法 find,返回值类型是std::string::size_type, 对应的是查找对象在字符串中的位置(从0开始),
如果未查找到,该返回值是一个很大的数据(4294967295),判断时与 std::string::npos 进行对比
npos是一个常数,表示size_t的最大值(Maximum value for size_t)。许多容器都提供这个东西,用来表示不存在的位置,类型一般是std::container_type::size_type。
模式 说明
ios::in 以读方式打开
ios::out 以写方式打开(以out打开的文件隐含被截断,要使不被截断,就要同时指定app模式。)
ios::app 以追加写方式打开(每次写操作前均定位到文件末尾)
ios::trunc 以截断方式打开文件(如果打开的文件存在,其内容将被丢弃,其大小被截断为零)
ios:binary 以二进制方式打开文件
ios::ate 打开文件后指针定位到文件尾
#pragma
#pragma 预编译指令的作用是设定编译器的状态或者是指示编译器完成一些特定的动作。#pragma指令对每个编译器给出了一个方法,在保持与C和C++语言完全兼容的情况下,给出主机或操作系统专有的特征。
#pragma once
#pragma once是一个比较常用的C/C++预处理指令,只要在头文件的最开始加入这条预处理指令,就能够保证头文件只被编译一次,防止头文件被重复引用。
**“被重复引用”**指头文件在cpp文件中多次被include,include嵌套造可能现象造成头文件多次引用。
#ifndef,#define,#endif是C/C++语言中的宏定义,通过宏定义避免文件多次编译。所以在所有支持C++语言的编译器上都是有效的,如果写的程序要跨平台,最好使用这种方式。
#pragma once则由编译器提供保证:同一个文件不会被编译多次。注意这里所说的“同一个文件”是指物理上的一个文件,而不是指内容相同的两个文件。
#pragma pack
https://blog.csdn.net/qq_28256407/article/details/118975111
- 机器的位数
计算机一次能处理数据的最大位数称为该机器的位数,位数跟电脑的CPU有关。
64位的机器一次最多从内存中读取8字节
32位的机器一次最多从内存中读取4字节
- 对齐系数
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。
默认的结构体对齐系数,取决于成员中最大的变量所占的字节数,按照最大变量所占的字节数进行对齐
struct test { // 测试的结构体
char a;
int b;
}
std::cout << sizeof(test) << std::endl;
// 输出的结果为8,而不是5
// 因为结构体按照int 4位来对齐
// char a 存储1个字节后,int b需要从第五个字节开始存放,来保证对齐方式。因此总共占8个字节
// cpu 需要2次读完该结构体数据
匿名函数
所谓匿名函数,其实类似于python中的lambda函数,其实就是没有名字的函数。使用匿名函数,可以免去函数的声明和定义。这样匿名函数仅在调用函数的时候才会创建函数对象,而调用结束后立即释放,所以匿名函数比非匿名函数更节省空间
C++中的匿名函数通常为[capture](parameters)->return-type{body},当parameters为空的时候,()可以被省去,当body只有“return”或者返回为void,那么”->return-type“可以被省去,下面将将对其中的参数一一解释
- capture:
[] //未定义变量.试图在Lambda内使用任何外部变量都是错误的.
[x, &y] //x 按值捕获, y 按引用捕获.
[&] //用到的任何外部变量都隐式按引用捕获
[=] //用到的任何外部变量都隐式按值捕获
[&, x] //x显式地按值捕获. 其它变量按引用捕获
[=, &z] //z按引用捕获. 其它变量按值捕获 - parameters:存储函数的参数
- return-type:函数的返回值
- body:函数体
三、Socket编程
socket本质就是一种数据类型,转定义下看类型,就是一个整数(unsigned int)
但是这个数是唯一的,标识着我们当前的应用程序,协议特点等信息
socket和thread的关系
https://www.cnblogs.com/dongxiaodong/p/11309140.html
int sendto(int sockfd, const void *msg, size_t len, int flags, const struct sockaddr *to, int tolen);
返回:大于0-成功发送数据长度;-1-出错;
UDP套接字使用无连接协议,因此必须使用sendto函数,指明目的地址;
msg:发送数据缓冲区的首地址;
len:缓冲区的长度;
flags:传输控制标志,通常为0;
to:发送目标;
tolen: 地址结构长度——sizeof(struct sockaddr)
int recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *from, int *fromlen);
返回:大于0——成功接收数据长度;-1——出错;
buf:接收数据的保存地址;
len:接收的数据长度
flags:是传输控制标志,通常为0;
from:保存发送方的地址
fromlen: 地址结构长度。
Win Socket
Windows Sockets DLL期望调用者使用的Windows Sockets规范的版本。 高位字节存储副版本号, 低位字节存储主版本号,可以用WORD MAKEWORD(BYTE,BYTE ) 返回这个值
WORD:字,是2byte的无符号整数,表示范围0~65535.相当于c语言中2个char的范围。
在socket通信中,在初始化WSA的时候我们常用WORD定义socket的版本号进行初始化:
WORD sockVersion = MAKEWORD(2, 2);
其中MAKEWORD是将两个byte合并成一个WORD,一个在高八位(b),一个在低八位(a):(MAKERWORD(a,b))。
高位字节存储副版本号, 低位字节存储主版本号,
int WSAStartup ( WORD wVersionRequested, LPWSADATA lpWSAData );
使用Socket的程序在使用Socket之前必须调用WSAStartup函数。以后应用程序就可以调用所请求的Socket库中的其它Socket函数了。
当一个应用程序调用WSAStartup函数时,操作系统根据请求的Socket版本来搜索相应的Socket库,然后绑定找到的Socket库到该应用程序中。以后应用程序就可以调用所请求的Socket库中的其它Socket函数了。该函数执行成功后返回0。
例:假如一个程序要使用2.1版本的Socket,那么程序代码如下
wVersionRequested = MAKEWORD( 2, 1 );
err = WSAStartup( wVersionRequested, &wsaData );
int WSACleanup (void);
应用程序在完成对请求的Socket库的使用后,要调用WSACleanup函数来解除与Socket库的绑定并且释放Socket库所占用的系统资源。
socket函数
SOCKET WSAAPI socket(
int af, //地址族规范。 地址族的可能值在Winsock2.h头文件中定义。
int type,//新套接字的类型规范。
int protocol//要使用的协议。
);
socket返回的值是一个文件描述符,SOCKET类型本身也是定义为int的,既然是文件描述符,那么在系统中都当作是文件来对待的,0,1,2分别表示标准输入、标准输出、标准错误。所以其他打开的文件描述符都会大于2, 错误时就返回 -1. 这里INVALID_SOCKET 也被定义为 -1
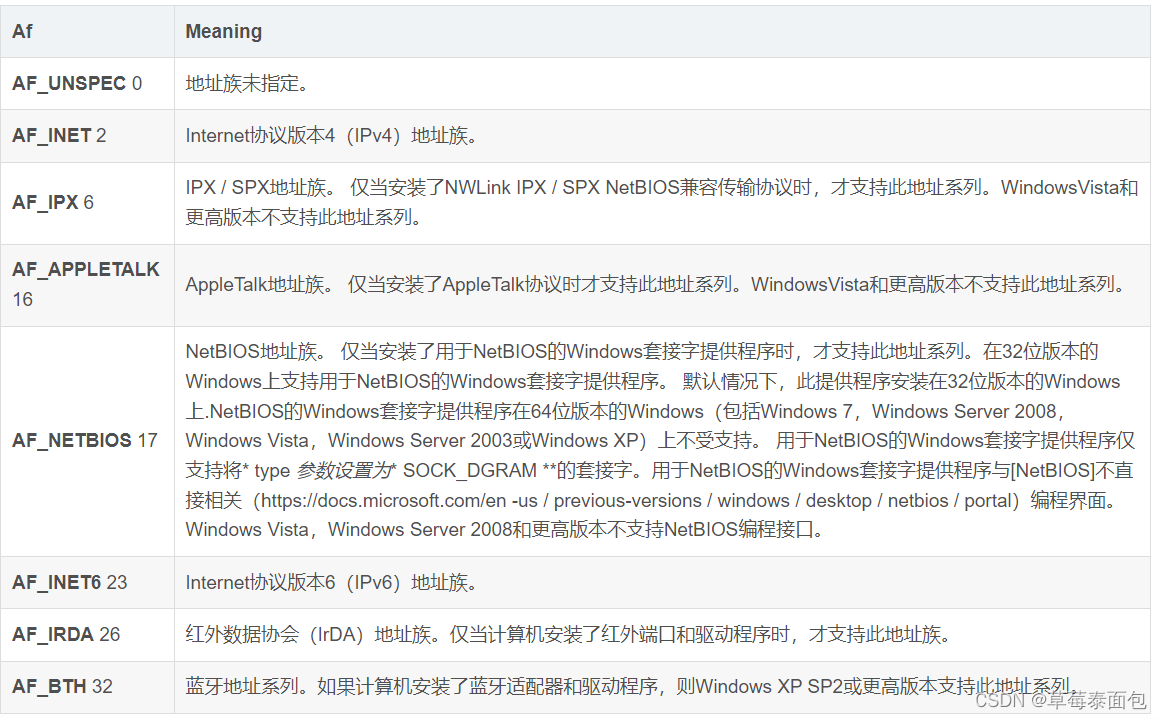
- AF 地址族规范。
在socket编程中只能是AF_INET。
- type 套接字的类型规范。

- protocl 要使用的协议。
protocol参数的可能选项特定于指定的地址族和套接字类型。
如果指定的值为0,则调用者不希望指定协议,服务提供商将选择要使用的协议。
由于指定了type,所以这个地方一般只要用0来代替就可以了。
当af参数为AF_INET或AF_INET6且类型为SOCK_RAW时,在IPv6或IPv4数据包头的协议字段中设置为协议指定的值。

端口复用setsockopt
https://blog.csdn.net/JMW1407/article/details/107321853
场景分析:
在A机上进行客户端网络编程,假如它所使用的本地端口号是1234,如果没有开启端口复用的话,它用本地端口1234去连接B机再用本地端口连接C机时就不可以,若开启端口复用的话在用本地端口1234访问B机的情况下还可以用本地端口1234访问C机。若是服务器程序中监听的端口,即使开启了复用,也不可以用该端口望外发起连接了。
端口复用允许在一个应用程序可以把 n 个套接字绑在一个端口上而不出错。
setsockopt
用于任意类型、任意状态套接口的设置选项值。
- 选项可能存在于多层协议中,它们总会出现在最上面的套接字层。
- 当操作套接字选项时,选项位于的层和选项的名称必须给出。
- 为了操作套接字层的选项,应该将层的值指定为SOL_SOCKET。
- 为了操作其它层的选项,控制选项的合适协议号必须给出。
例如,为了表示一个选项由TCP协议解析,层应该设定为协议 号TCP。
#include <sys/types.h>
#include <sys/socket.h>
int setsockopt(int sockFd, int level, int optname, const void *optval, socklen_t optlen);
1、sockfd:将要被设置或者获取选项的套接字。
2、level:选项定义的层次;支持SOL_SOCKET、IPPROTO_TCP、IPPROTO_IP和IPPROTO_IPV6。一般设成SOL_SOCKET以存取socket层。
SOL_SOCKET:通用套接字选项.
IPPROTO_IP:IP选项.IPv4套接口
IPPROTO_TCP:TCP选项.
IPPROTO_IPV6: IPv6套接口
3、optname: 欲设置的选项,有下列几种数值:

SO_REUSEADDR提供如下四个功能:
- 允许启动一个监听服务器并捆绑其众所周知端口,即使以前建立的将此端口用做他们的本地端口的连接仍存在。这通常是重启监听服务器时出现,若不设置此选项,则bind时将出错。
- 允许在同一端口上启动同一服务器的多个实例,只要每个实例捆绑一个不同的本地IP地址即可。对于TCP,我们根本不可能启动捆绑相同IP地址和相同端口号的多个服务器。
- 允许单个进程捆绑同一端口到多个套接口上,只要每个捆绑指定不同的本地IP地址即可。这一般不用于TCP服务器。
- 允许完全重复的捆绑:当一个IP地址和端口绑定到某个套接口上时,还允许此IP地址和端口捆绑到另一个套接口上。一般来说,这个特性仅在支持多播的系统上才有,而且只对UDP套接口而言(TCP不支持多播)。
4、optval: 对于setsockopt(),指针,指向存放选项待设置的新值的缓冲区。获得或者是设置套接字选项.根据选项名称的数据类型进行转换。
5、optlen:optval缓冲区长度。
close()
int close(int fd);
close()函数存在于函数库unistd.h函数库中;
close()函数用于释放系统分配给套接字的资源,该函数即文件操作中常用的close函数。
参数fd为需要关闭的套接字文件描述符;
调用成功返回0,否则返回-1并设置errno;
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main(int argc, char *argv[])
{
int sockfd_one;
int err_log;
sockfd_one = socket(AF_INET, SOCK_DGRAM, 0); //创建UDP套接字one
if(sockfd_one < 0)
{
perror("sockfd_one");
exit(-1);
}
// 设置本地网络信息
struct sockaddr_in my_addr;
bzero(&my_addr, sizeof(my_addr));
my_addr.sin_family = AF_INET;
my_addr.sin_port = htons(8000); // 端口为8000
my_addr.sin_addr.s_addr = htonl(INADDR_ANY);
// 在sockfd_one绑定bind之前,设置其端口复用
int opt = 1;
setsockopt( sockfd_one, SOL_SOCKET,SO_REUSEADDR,
(const void *)&opt, sizeof(opt) );
// 绑定,端口为8000
err_log = bind(sockfd_one, (struct sockaddr*)&my_addr, sizeof(my_addr));
if(err_log != 0)
{
perror("bind sockfd_one");
close(sockfd_one);
exit(-1);
}
int sockfd_two;
sockfd_two = socket(AF_INET, SOCK_DGRAM, 0); //创建UDP套接字two
if(sockfd_two < 0)
{
perror("sockfd_two");
exit(-1);
}
// 在sockfd_two绑定bind之前,设置其端口复用
opt = 1;
setsockopt( sockfd_two, SOL_SOCKET,SO_REUSEADDR,
(const void *)&opt, sizeof(opt) );
// 新套接字sockfd_two,继续绑定8000端口,成功
err_log = bind(sockfd_two, (struct sockaddr*)&my_addr, sizeof(my_addr));
if(err_log != 0)
{
perror("bind sockfd_two");
close(sockfd_two);
exit(-1);
}
close(sockfd_one);
close(sockfd_two);
return 0;
}
端口复用允许在一个应用程序可以把 n 个套接字绑在一个端口上而不出错。同时,这 n 个套接字发送信息都正常,没有问题。
但是,这些套接字并不是所有都能读取信息,只有最后一个套接字会正常接收数据。
在之前的代码上,添加两个线程,分别负责接收sockfd_one,sockfd_two的信息:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <pthread.h>
// 线程1的回调函数
void *recv_one(void *arg)
{
printf("===========recv_one==============\n");
int sockfd = (int )arg;
while(1){
int recv_len;
char recv_buf[512] = "";
struct sockaddr_in client_addr;
char cli_ip[INET_ADDRSTRLEN] = "";//INET_ADDRSTRLEN=16
socklen_t cliaddr_len = sizeof(client_addr);
recv_len = recvfrom(sockfd, recv_buf, sizeof(recv_buf), 0, (struct sockaddr*)&client_addr, &cliaddr_len);
inet_ntop(AF_INET, &client_addr.sin_addr, cli_ip, INET_ADDRSTRLEN);
printf("\nip:%s ,port:%d\n",cli_ip, ntohs(client_addr.sin_port));
printf("sockfd_one =========== data(%d):%s\n",recv_len,recv_buf);
}
return NULL;
}
// 线程2的回调函数
void *recv_two(void *arg)
{
printf("+++++++++recv_two++++++++++++++\n");
int sockfd = (int )arg;
while(1){
int recv_len;
char recv_buf[512] = "";
struct sockaddr_in client_addr;
char cli_ip[INET_ADDRSTRLEN] = "";//INET_ADDRSTRLEN=16
socklen_t cliaddr_len = sizeof(client_addr);
recv_len = recvfrom(sockfd, recv_buf, sizeof(recv_buf), 0, (struct sockaddr*)&client_addr, &cliaddr_len);
inet_ntop(AF_INET, &client_addr.sin_addr, cli_ip, INET_ADDRSTRLEN);
printf("\nip:%s ,port:%d\n",cli_ip, ntohs(client_addr.sin_port));
printf("sockfd_two @@@@@@@@@@@@@@@ data(%d):%s\n",recv_len,recv_buf);
}
return NULL;
}
int main(int argc, char *argv[])
{
int err_log;
/sockfd_one
int sockfd_one;
sockfd_one = socket(AF_INET, SOCK_DGRAM, 0); //创建UDP套接字one
if(sockfd_one < 0)
{
perror("sockfd_one");
exit(-1);
}
// 设置本地网络信息
struct sockaddr_in my_addr;
bzero(&my_addr, sizeof(my_addr));
my_addr.sin_family = AF_INET;
my_addr.sin_port = htons(8000); // 端口为8000
my_addr.sin_addr.s_addr = htonl(INADDR_ANY);
// 在sockfd_one绑定bind之前,设置其端口复用
int opt = 1;
setsockopt( sockfd_one, SOL_SOCKET,SO_REUSEADDR,
(const void *)&opt, sizeof(opt) );
// 绑定,端口为8000
err_log = bind(sockfd_one, (struct sockaddr*)&my_addr, sizeof(my_addr));
if(err_log != 0)
{
perror("bind sockfd_one");
close(sockfd_one);
exit(-1);
}
//接收信息线程1
pthread_t tid_one;
pthread_create(&tid_one, NULL, recv_one, (void *)sockfd_one);
/sockfd_two
int sockfd_two;
sockfd_two = socket(AF_INET, SOCK_DGRAM, 0); //创建UDP套接字two
if(sockfd_two < 0)
{
perror("sockfd_two");
exit(-1);
}
// 在sockfd_two绑定bind之前,设置其端口复用
opt = 1;
setsockopt( sockfd_two, SOL_SOCKET,SO_REUSEADDR,
(const void *)&opt, sizeof(opt) );
// 新套接字sockfd_two,继续绑定8000端口,成功
err_log = bind(sockfd_two, (struct sockaddr*)&my_addr, sizeof(my_addr));
if(err_log != 0)
{
perror("bind sockfd_two");
close(sockfd_two);
exit(-1);
}
//接收信息线程2
pthread_t tid_two;
pthread_create(&tid_two, NULL, recv_two, (void *)sockfd_two);
while(1){ // 让程序阻塞在这,不结束
NULL;
}
close(sockfd_one);
close(sockfd_two);
return 0;
}
线程thread
https://blog.csdn.net/sevens_0804/article/details/102823184

在Linux系统中,多线程的管理使用 pthread_t

pthread_create
int pthread_create(pthread_t *thread, pthread_attr_t *attr, void *(*start_routine)(void *), void *arg)
第一个参数为指向线程标识符的指针,也就是线程对象的指针
第二个参数用来设置线程属性。
第三个参数是线程运行函数的地址,通俗理解线程要执行函数(线程做的事情的)指针。一般这个函数执行时间比较长(有while循环),做的事情比较多。如果单次动作(执行时间比较短),也就无需多线程执行了。
最后一个参数是线程要运行函数的参数。
线程的默认堆栈大小是1MB,就是说,系统每创建一个线程就要至少提供1MB的内存,那么,创建线程失败,极有可能就是内存不够用了。
pthread_create会导致内存泄露! pthread_create创建的线程结束后,系统并未回收其资源,从而导致了泄露。
为什么要分离线程?
线程的分离状态决定一个线程以什么样的方式来终止自己。线程的默认属性是非分离状态,这种情况下,原有的线程等待创建的线程结束。只有当pthread_join()函数返回时,创建的线程才算终止,才能释放自己占用的系统资源。而分离线程不是这样子的,它没有被其他的线程所等待,自己运行结束了,线程也就终止了,马上释放系统资源。程序员应该根据自己的需要,选择适当的分离状态。
从上面的描述中可以得知如果调用pthread_create函数创建一个默认非分离状态的线程,如果不用pthread_join()函数,线程结束时并不算终止,所以仍然会占用系统资源。
std::thread与pthread对比
std::thread是C++11接口,使用时需要包含头文件#include ,编译时需要支持c++11标准。thread中封装了pthread的方法,所以也需要链接pthread库
pthread是C++98接口且只支持Linux,使用时需要包含头文件#include <pthread.h>,编译时需要链接pthread库
pthread_detach
int pthread_detach(pthread_t thread);
成功:0;失败:错误号
作用:从状态上实现线程分离,注意不是指该线程独自占用地址空间。
线程分离状态:指定该状态,线程主动与主控线程断开关系。线程结束后(不会产生僵尸线程),其退出状态不由其他线程获取,而直接自己自动释放(自己清理掉PCB的残留资源)。【进程没有该机制】
一般情况下,线程终止后,其终止状态一直保留到其它线程调用pthread_join获取它的状态为止(或者进程终止被回收了)。但是线程也可以被置为detach状态,这样的线程一旦终止就立刻回收它占用的所有资源,而不保留终止状态。不能对一个已经处于detach状态的线程调用pthread_join,这样的调用将返回EINVAL错误(22号错误)。也就是说,如果已经对一个线程调用了pthread_detach就不能再调用pthread_join了。
分析:
- 使用pthread_detach函数实现线程分离时,应当先创建线程(pthread_create),然后再用pthread_detach实现该线程的分离。因此,这种方式与修改线程属性来实现线程分离的方法相比,不会发生在线程创建函数还未来得及返回时子线程提前结束导致返回的线程号是错误的线程号的情况。因为采用这种方法,即使子线程提前结束(先于pthread_create返回),但是子线程还未处于分离状态,因此其PCB的残留信息依然存在,如线程号等一些系统资源,所以线程号等系统资源仍被占据,还未分配出去,所以创建函数返回的线程号依然是该线程的线程号;
- 对处于分离状态的线程进行回收,会出现错误,且错误编号为22;
- 还可采用修改线程属性的方法来实现线程分离。
pthread_cancel
线程结束执行的方式共有 3 种,分别是:
1.线程将指定函数体中的代码执行完后自行结束;
2.线程执行过程中,遇到 pthread_exit() 函数结束执行。
3.线程执行过程中,被同一进程中的其它线程(包括主线程)强制终止;
第一种方式:很容易理解,就是函数内所有代码执行完毕后,线程主动结束。
第二种方式:已经在《pthread_exit()函数》一节中做了详细的介绍。
第 3 种方式:本节给大家重点介绍,多线程程序中,一条线程可以借助
pthread_cancel() 函数向另一条线程发送“终止执行”的信号(后续称“Cancel”信号),从而令目标线程结束执行。
int pthread_cancel(pthread_t tid); //向 tid 目标线程发送 Cancel 信号
如果 pthread_cancel() 函数成功地发送了 Cancel 信号,返回数字 0;反之如果发送失败,函数返回值为非零数。
对于接收 Cancel 信号后结束执行的目标线程,等同于该线程自己执行如下语句:
pthread_exit(PTHREAD_CANCELED);
bind函数
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
(1)参数 sockfd ,需要绑定的socket。
(2)参数 addr ,存放了服务端用于通信的地址和端口。
(3)参数 addrlen ,表示 addr 结构体的大小
(4)返回值:成功则返回0 ,失败返回-1,错误原因存于 errno 中。如果绑定的地址错误,或者端口已被占用,bind 函数一定会报错,否则一般不会返回错误。
UDP recvfrom sendto

#include <sys/socket.h>
ssize_t recvfrom(int sockfd, void *buf, size_t nbytes,int flags, struct sockaddr *from, socklen_t *addrlen);
ssize_t sendto(int sockfd, const void *buf, size_t nsize,int flags, const struct sockaddr *to, const socklen_t *addrlen);
若成功,均返回读或者写的字节数;失败则返回-1
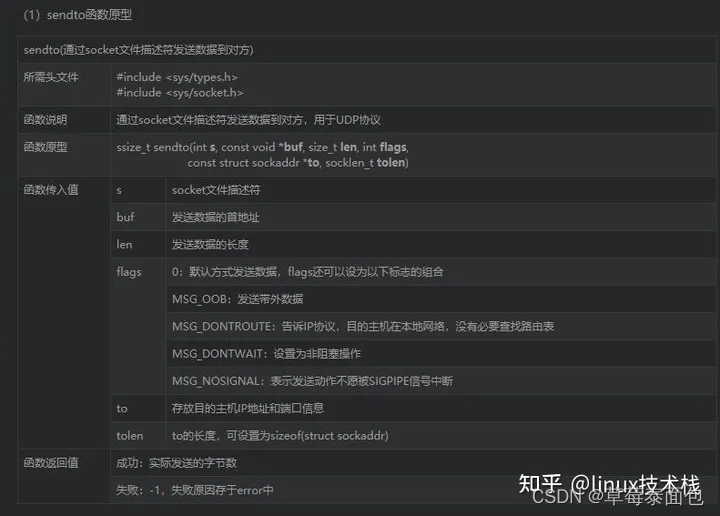
sendto() 用来将数据由指定的 socket 传给对方主机. 参数s 为已建好连线的 socket , 如果利用 UDP 协议则不需经过连线操作. 参数 msg 指向欲连线的数据内容, 参数 flags 一般设 0 , 详细描述请参考 send(). 参数 to 用来指定欲传送的网络地址, 结构sockaddr 请参考 bind(). 参数 tolen 为 sockaddr 的结果长度.
成功则返回实际传送出去的字符数,失败返回-1,错误原因存于errno 中

send 和 sendto 函数在 UDP 层没有输出缓冲区,在 TCP 层有输出缓冲区,recv 和recvfrom 无论在 UDP 层还是 TCP 层都有接收缓冲区。这样看来 sendto 应该是不会阻塞的。

UDP 发送缓冲区和接收缓冲区细节分析:
这一次我们展示的套接口发送缓冲区用虚框表示,因为它并不存在。UDP 套接口有发送缓冲区大小(SO_SNDBUF修改),不过它仅仅是写到套接口的 UDP 数据报的大小上限。 如果应用程序写一个大于套接口发送缓冲区大小的数据报,内核将返回一个 EMSGSIZE 错误。 既然 UDP 不可靠,他不必保存应用进程的数据拷贝,因此无需真正的发送缓冲区(应用进程的数据在沿协议栈往下传递,以某种形式拷贝到内核缓冲区,然而数据链路层在送出数据之后将丢弃该拷贝)
UDP 没有 MSS(最大分节大小)的概念,如果某个 UDP 应用程序发送大数据,那么他比 TCP 应用程序更容易分片。从 UDP 套接口 write 成功返回仅仅表示用户写入的数据报或者所有片段已经加入到数据链路层的输出队列。如果该队列没有足够的空间存放该数据报或者他的某个片段,内核 通常返回给应用进程一个 ENOBUFS 错误(也有的系统不会返回错误)。
TCP 和 UDP 都拥有套接口接收缓冲区。TCP 套接口接收缓冲区不可能溢出,因为 TCP 具有流量控制(窗口).然而对于 TCP 来说, 当接收到的数据报装不进套接口接收缓冲区时,该数据报就丢弃 。 UDP 是没有流量控制的:较快的发送端可以很容易淹没较慢的接收端,导致接收端的 UDP 丢弃数据报。
sockaddr和sockaddr_in
sockaddr常用于bind、connect、recvfrom、sendto等函数的参数,指明地址信息,是一种通用的套接字地址。
sockaddr_in 是internet环境下套接字的地址形式。所以在网络编程中我们会对sockaddr_in结构体进行操作,使用sockaddr_in来建立所需的信息,最后使用类型转化就可以了。一般先把sockaddr_in变量赋值后,强制类型转换后传入用sockaddr做参数的函数
sockaddr在头文件#include <sys/socket.h>中定义,sockaddr的缺陷是:sa_data把目标地址和端口信息混在一起了
struct sockaddr {
sa_family_t sin_family;//地址族
char sa_data[14]; //14字节,包含套接字中的目标地址和端口信息
};
sockaddr_in在头文件#include<netinet/in.h>或#include <arpa/inet.h>中定义,该结构体解决了sockaddr的缺陷,把port和addr 分开储存在两个变量中
sin_port和sin_addr都必须是网络字节序(NBO),一般可视化的数字都是主机字节序(HBO)

主机字节序与网络字节序
主机字节序(host-byte)指的是处理器存储数据的字节顺序。对于Inter x86处理器来说,将数据的不重要的部分保存在低地址,重要的部分保存在高地址,即低地址中保存的是数据的低字节位,高地址保存的是数据的高字节位。
主机字节序又叫做“小头”(little-endian)。
int ip_Address_hostbyte = 0x12345678;
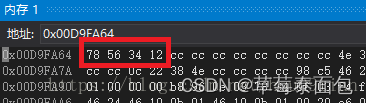
网络字节序(network-byte)指的是网络编程时,存储数据的字节顺序。与“主机字节序”相反,网络字节序将数据的重要部分保存在低地址,不重要的部分保存到高地址,即低地址保存的是数据的高字节位,高地址保存的是数据的低字节位。在网络编程时用到的IP地址和端口号都需要网络字节序。
htons htonl
htons()作用是将端口号由主机字节序转换为网络字节序的整数值。(host to net)
htonl()作用和htons()一样,不过它针对的是32位的(long),而htons()针对的是两个字节,16位的(short)。
servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // 任意ip地址。
servaddr.sin_addr.s_addr = inet_addr("192.168.190.134"); // 指定ip地址。
sin.sin_port = htons(4567);
inet_pton()和inet_ntop()
这两个函数是随IPv6出现的函数,对于IPv4地址和IPv6地址都适用,函数中p和n分别代表表达(presentation)和数值(numeric)
// windows下头文件
#include <ws2tcpip.h>
// linux下头文件
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
inet_pton()
功能:将标准文本表示形式的IPv4或IPv6 Internet网络地址转换为数字二进制形式。
INT WSAAPI inet_pton(
INT Family, //地址家族 IPV4使用AF_INET IPV6使用AF_INET6
PCSTR pszAddrString, //指向以NULL为结尾的字符串指针,该字符串包含要转换为数字的二进制形式的IP地址文本形式。
PVOID pAddrBuf//指向存储二进制表达式的缓冲区
);
sockaddr_in addrServer;
inet_pton(AF_INET, "127.0.0.1", &addrServer.sin_addr);
addrServer.sin_port = htons(6000); // 该函数需要添加头文件: #include <winsock.h>
addrServer.sin_family = AF_INET;
返回值:
1.若无错误发生,则inet_pton()返回1,pAddrBuf参数执行的缓冲区包含按网络字节顺序的二进制数字IP地址。
2.若pAddrBuf指向的字符串不是一个有效的IPv4点分十进制字符串或者不是一个有效的IPv6点分十进制字符串,则返回0。否则返回-1。
3.可以通过WSAGetLastError()获得错误错误代码
inet_ntop()
功能:将IPv4或IPv6 Internet网络地址转换为 Internet标准格式的字符串。
PCWSTR WSAAPI InetNtopW(
INT Family, //地址家族 IPV4使用AF_INET IPV6使用AF_INET6
const VOID *pAddr, //指向网络字节中要转换为字符串的IP地址的指针
PWSTR pStringBuf,//指向缓冲区的指针,该缓冲区用于存储IP地址的以NULL终止的字符串表示形式。
size_t StringBufSize//输入时,由pStringBuf参数指向的缓冲区的长度(以字符为单位)
);
char buf[20] = { 0 };
inet_ntop(AF_INET, &recvAddr.sin_addr, buf, sizeof(buf));//其中recvAddr为SOCKADDR_IN类型
cout << "客户端地址:" << buf << endl;
返回值:
1.若无错误发生,Inet_ntop()函数返回一个指向缓冲区的指针,该缓冲区包含标准格式的IP地址的字符串表示形式。
2.否则返回NULL
3.获取错误码:WSAGetLastError()
INADDR_ANY
INADDR_ANY表示不管是哪个网卡接收到数据,只要目的端口是SERV_PORT,就会被该应用程序接收到
转换过来就是0.0.0.0,泛指本机的意思,也就是表示本机的所有IP,因为有些机子不止一块网卡,多网卡的情况下,这个就表示所有网卡ip地址的意思。
比如一台电脑有3块网卡,分别连接三个网络,那么这台电脑就有3个ip地址了,如果某个应用程序需要监听某个端口,那他要监听哪个网卡地址的端口呢?
如果绑定某个具体的ip地址,你只能监听你所设置的ip地址所在的网卡的端口,其它两块网卡无法监听端口,如果我需要三个网卡都监听,那就需要绑定3个ip,也就等于需要管理3个套接字进行数据交换,这样岂不是很繁琐?
所以出现INADDR_ANY,你只需绑定INADDR_ANY,管理一个套接字就行,不管数据是从哪个网卡过来的,只要是绑定的端口号过来的数据,都可以接收到。
thread构造函数
std::thread类的构造函数是使用可变参数模板实现的,也就是说,可以传递任意个参数,第一个参数是线程的入口函数,而后面的若干个参数是该函数的参数。
第一参数的类型并不是c语言中的函数指针(c语言传递函数都是使用函数指针),在c++11中,增加了可调用对象(Callable Objects)的概念,总的来说,可调用对象可以是以下几种情况:
- 函数指针
- 重载了operator()运算符的类对象,即仿函数
- lambda表达式(匿名函数)
- std::function
linux 互斥锁
- 互斥锁创建
有两种方法创建互斥锁,静态方式和动态方式。
POSIX定义了一个宏PTHREAD_MUTEX_INITIALIZER来静态初始化互斥锁,方法如下:
pthread_mutex_t mutex=PTHREAD_MUTEX_INITIALIZER;
在LinuxThreads实现中,pthread_mutex_t是一个结构,而PTHREAD_MUTEX_INITIALIZER则是一个结构常量。
pthread_mutex_init()
动态方式是采用pthread_mutex_init()函数来初始化互斥锁,API定义如下:
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr)
其中mutexattr用于指定互斥锁属性(见下),如果参数attr为空(NULL),则使用默认的互斥锁属性,默认属性为快速互斥锁 。互斥锁的属性在创建锁的时候指定,在LinuxThreads实现中仅有一个锁类型属性,不同的锁类型在试图对一个已经被锁定的互斥锁加锁时表现不同。
- 函数成功完成之后会返回零,其他任何返回值都表示出现了错误。
- 函数成功执行后,互斥锁被初始化为未锁住态。
pthread_mutex_t mutex;
pthread_mutex_init(&mutex,NULL);
- 锁操作
锁操作主要包括加锁 pthread_mutex_lock()、解锁pthread_mutex_unlock()和测试加锁 pthread_mutex_trylock()三个,不论哪种类型的锁,都不可能被两个不同的线程同时得到,而必须等待解锁。对于普通锁和适应锁类型,解锁者可以是同进程内任何线程;而检错锁则必须由加锁者解锁才有效,否则返回EPERM;对于嵌套锁,文档和实现要求必须由加锁者解锁,但实验结果表明并没有这种限制,这个不同目前还没有得到解释。在同一进程中的线程,如果加锁后没有解锁,则任何其他线程都无法再获得锁。
int pthread_mutex_lock(pthread_mutex_t *mutex)
int pthread_mutex_unlock(pthread_mutex_t *mutex)
int pthread_mutex_trylock(pthread_mutex_t *mutex)
pthread_mutex_destroy()
int pthread_mutex_destroy(pthread_mutex_t *mutex);
头文件: #include <pthread.h>
返回值: 成功则返回0, 出错则返回错误编号
用于注销一个互斥锁
对于动态分配的互斥量, 在申请内存(malloc)之后, 通过pthread_mutex_init进行初始化,
并且在释放内存(free)前需要调用pthread_mutex_destroy.
socket连接报错Cannot assign requested address
https://www.cnblogs.com/thatsit/p/cannot-assign-requested-address.html
https://blog.csdn.net/ccgshigao/article/details/109763478
四、计时
-精确测量一段代码的执行时间
1.LARGE_INTERGER类型
LARGE_INTERGER是union类型,用于表示一8个字节的有符号整数,定义如下:
typedef union _LARGE_INTEGER {
struct {
ULONG LowPart;
LONG HighPart;
} DUMMYSTRUCTNAME;
struct {
ULONG LowPart;
LONG HighPart;
} u;
#endif //MIDL_PASS
LONGLONG QuadPart;
} LARGE_INTEGER;
如果编译器支持64整数,可以直接使用QuadPart(64位),否则分别对LowPart和HighPart存取,HighPart的最高位为符号位
表示数的范围:-3689348814741910324到+4611686018427387903
2.LONGLONG
用8个字节表示一个有符号整数
3.double
双精度浮点型,用8个字节表示一浮点数
4.QueryPerformanceFrequency()
原型:BOOL QueryPerformanceFrequency(LARGE_INTERGER *lpFrequency);
功能:返回硬件支持的高精度计数器的频率(每秒钟的CPU Tick数)
5.QueryPerformanceCounter()
原型:BOOL QueryPerformanceCounter(LARGE_INTEGER *lpCount);
功能:返回高精度计数器的计数值
返回值:非零,硬件支持高精度计数器;零,硬件不支持,读取失败。
6.利用上述API精确计算执行时间
在进行定时之前,先调用QueryPerformanceFrequece()函数获得机器内部定时器的时钟频率,然后在需要严格定时的事件发生之前和发生之后分别调用QueryPerformanceCounter()函数,利用两次获得的计数之差及时钟频率,计算出事件经历的精确时间,计算公式如下:
double time = (nStopCounter.QuadPart – nStartCounter.QuadPart)/frequency.QuadPart
单位是秒精度,计时误差不超过1微妙,精度与CPU等机器配置有关
time.h
struct timeb
{
time_t time; /* Seconds since epoch, as from `time'. */
unsigned short int millitm; /* Additional milliseconds. */
short int timezone; /* Minutes west of GMT. */
short int dstflag; /* Nonzero if Daylight Savings Time used. */
};
/* Fill in TIMEBUF with information about the current time. */
extern int ftime (struct timeb *__timebuf);
五、ELF
https://juejin.cn/post/7025762625543733261
ELF(Executable and Linkable Format)是一种行业标准的二进制数据封装格式,主要用于封装可执行文件、动态库、object 文件和 core dumps 文件。
使用google NDK对源代码进行编译和链接,生成的动态库或可执行文件都是ELF格式的。
内存
基地址
在进程的内存空间中,各种ELF的加载地址是随机的,只有在运行时才能拿到加载地址,也就是基地址。
道哥注解:
我们在查看一个动态链接库时,看到的入口地址都是 0x0000_0000。
动态库在被加载到内存中时,因为存在加载顺序的问题,所以加载地址不是固定的。
还有一种说法:对于某一个进程而言,它在被加载到内存中时,它所依赖的所有动态库的顺序是一定的。
因此,每个动态库的加载地址也是固定的,因此,理论上可以在第一次重定位之后,把重定位之后的代码段存储下来。
这样,以后再次启动这个进程时,就不需要重定位了,加快程序的启动速度。
我们需要知道ELF的基地址,才能将相对地址换算成绝对地址。
dl_iterate_phdr 这个函数真的很有用,以回调函数的形式可到每一个动态链接库的加载地址等信息。
如果没有这个函数,很多信息就需要从 /proc/xxx/maps 中来获取,执行速度慢,因为要处理很多字符串信息。
六、linux查看动态链接库地址
dl_iterate_phdr
dl_iterate_phdr()函数允许应用程序在运行时进行查询,以了解其已加载了哪些共享库以及它们的加载顺序。
dl_iterate_phdr()函数遍历应用程序共享对象的列表,并为每个对象调用一次函数回调,直到所有共享对象都已处理或回调返回非零值为止。
每个对回调的调用都接收三个参数:info,它是指向包含有关共享库信息的结构的指针;大小,即info指向的结构的大小;和数据,它是调用程序作为对dl_iterate_phdr()的调用中的第二个参数(也称为数据)传递的任何值的副本。
info参数是以下类型的结构
dlpi_addr字段指示共享库的基地址(即,共享库的虚拟内存地址与该对象在从中加载该文件的文件中的偏移量之间的差)。 dlpi_name字段是一个以空字符结尾的字符串,提供了从中加载共享库的路径名。
为了理解dlpi_phdr和dlpi_phnum字段的含义,我们需要意识到ELF共享库由许多段组成,每个段都有一个描述该段的相应程序头。 dlpi_phdr字段是指向此共享库程序头数组的指针。 dlpi_phnum字段指示此数组的大小。
struct dl_phdr_info {
ElfW(Addr) dlpi_addr; /* 基地址 */
const char* dlpi_name; /* 对象名 */
const Elf(Phdr) *dlpi_phdr; /* 对象的elf 头数组的指针*/
ElfW(Half) dlpi_phnum; /* 头的数量 */
};
下面的程序显示它已加载的共享库的路径名列表。对于每个共享对象,程序为ELF段的每个对象列出一些信息(虚拟地址,大小,标志和类型)。
以下shell会话演示了该程序在x86-64系统上产生的输出。显示输出的第一个共享库(名称为空字符串)是主程序。
$ ./a.out
Name: "" (9 segments)
0: [ 0x400040; memsz: 1f8] flags: 0x5; PT_PHDR
1: [ 0x400238; memsz: 1c] flags: 0x4; PT_INTERP
2: [ 0x400000; memsz: ac4] flags: 0x5; PT_LOAD
3: [ 0x600e10; memsz: 240] flags: 0x6; PT_LOAD
4: [ 0x600e28; memsz: 1d0] flags: 0x6; PT_DYNAMIC
5: [ 0x400254; memsz: 44] flags: 0x4; PT_NOTE
6: [ 0x400970; memsz: 3c] flags: 0x4; PT_GNU_EH_FRAME
7: [ (nil); memsz: 0] flags: 0x6; PT_GNU_STACK
8: [ 0x600e10; memsz: 1f0] flags: 0x4; PT_GNU_RELRO
Name: "linux-vdso.so.1" (4 segments)
0: [0x7ffc6edd1000; memsz: e89] flags: 0x5; PT_LOAD
1: [0x7ffc6edd1360; memsz: 110] flags: 0x4; PT_DYNAMIC
2: [0x7ffc6edd17b0; memsz: 3c] flags: 0x4; PT_NOTE
3: [0x7ffc6edd17ec; memsz: 3c] flags: 0x4; PT_GNU_EH_FRAME
Name: "/lib64/libc.so.6" (10 segments)
0: [0x7f55712ce040; memsz: 230] flags: 0x5; PT_PHDR
1: [0x7f557145b980; memsz: 1c] flags: 0x4; PT_INTERP
2: [0x7f55712ce000; memsz: 1b6a5c] flags: 0x5; PT_LOAD
3: [0x7f55716857a0; memsz: 9240] flags: 0x6; PT_LOAD
4: [0x7f5571688b80; memsz: 1f0] flags: 0x6; PT_DYNAMIC
5: [0x7f55712ce270; memsz: 44] flags: 0x4; PT_NOTE
6: [0x7f55716857a0; memsz: 78] flags: 0x4; PT_TLS
7: [0x7f557145b99c; memsz: 544c] flags: 0x4; PT_GNU_EH_FRAME
8: [0x7f55712ce000; memsz: 0] flags: 0x6; PT_GNU_STACK
9: [0x7f55716857a0; memsz: 3860] flags: 0x4; PT_GNU_RELRO
Name: "/lib64/ld-linux-x86-64.so.2" (7 segments)
0: [0x7f557168f000; memsz: 20828] flags: 0x5; PT_LOAD
1: [0x7f55718afba0; memsz: 15a8] flags: 0x6; PT_LOAD
2: [0x7f55718afe10; memsz: 190] flags: 0x6; PT_DYNAMIC
3: [0x7f557168f1c8; memsz: 24] flags: 0x4; PT_NOTE
4: [0x7f55716acec4; memsz: 604] flags: 0x4; PT_GNU_EH_FRAME
5: [0x7f557168f000; memsz: 0] flags: 0x6; PT_GNU_STACK
6: [0x7f55718afba0; memsz: 460] flags: 0x4; PT_GNU_RELRO
#define _GNU_SOURCE
#include <link.h>
#include <stdlib.h>
#include <stdio.h>
static int
callback(struct dl_phdr_info *info, size_t size, void *data)
{
char *type;
int p_type, j;
printf("Name: \"%s\" (%d segments)\n", info->dlpi_name,
info->dlpi_phnum);
for (j = 0; j < info->dlpi_phnum; j++) {
p_type = info->dlpi_phdr[j].p_type;
type = (p_type == PT_LOAD) ? "PT_LOAD" :
(p_type == PT_DYNAMIC) ? "PT_DYNAMIC" :
(p_type == PT_INTERP) ? "PT_INTERP" :
(p_type == PT_NOTE) ? "PT_NOTE" :
(p_type == PT_INTERP) ? "PT_INTERP" :
(p_type == PT_PHDR) ? "PT_PHDR" :
(p_type == PT_TLS) ? "PT_TLS" :
(p_type == PT_GNU_EH_FRAME) ? "PT_GNU_EH_FRAME" :
(p_type == PT_GNU_STACK) ? "PT_GNU_STACK" :
(p_type == PT_GNU_RELRO) ? "PT_GNU_RELRO" : NULL;
printf(" %2d: [%14p; memsz:%7lx] flags: 0x%x; ", j,
(void *) (info->dlpi_addr + info->dlpi_phdr[j].p_vaddr),
info->dlpi_phdr[j].p_memsz,
info->dlpi_phdr[j].p_flags);
if (type != NULL)
printf("%s\n", type);
else
printf("[other (0x%x)]\n", p_type);
}
return 0;
}
int
main(int argc, char *argv[])
{
dl_iterate_phdr(callback, NULL);
exit(EXIT_SUCCESS);
}
七、assert
https://blog.csdn.net/houxiaoni01/article/details/103609389
默认情况下,assert 宏只有在 Debug 版本(内部调试版本)中才能够起作用,而在 Release 版本(发行版本)中将被忽略。当然,也可以通过定义宏或设置编译器参数等形式来在任何时候启用或者禁用断言检查(不建议这么做)。同样,在程序投入运行后,最终用户在遇到问题时也可以重新起用断言。这样可以快速发现并定位软件问题,同时对系统错误进行自动报警。对于在系统中隐藏很深,用其他手段极难发现的问题也可以通过断言进行定位,从而缩短软件问题定位时间,提高系统的可测性。
void assert(int expression);
assert宏的原型定义在<assert.h>中,其作用是先计算表达式expression的值为假(即为0),那么它就先向stderr打印一条出错信息,然后通过条用abort来终止程序;
使用assert的缺点是,频繁的调用会极大的影响程序的性能,增加额外的开销。
在调试结束后,可以通过在包含#include 的语句之前插入 #define NDEBUG 来禁用assert调用,示例代码如下:
#include
#define NDEBUG
#include
八、C标准库宏
va_arg()
检索函数参数列表中类型为 type 的下一个参数。它无法判断检索到的参数是否是传给函数的最后一个参数。
type va_arg(va_list ap, type)
#include <stdarg.h>
#include <stdio.h>
int sum(int, ...);
int main()
{
printf("15 和 56 的和 = %d\n", sum(2, 15, 56) );
return 0;
}
int sum(int num_args, ...)
{
int val = 0;
va_list ap;
int i;
va_start(ap, num_args);
for(i = 0; i < num_args; i++)
{
val += va_arg(ap, int);
}
va_end(ap);
return val;
}
参数
ap – 这是一个 va_list 类型的对象,存储了有关额外参数和检索状态的信息。该对象应在第一次调用 va_arg 之前通过调用 va_start 进行初始化。
type – 这是一个类型名称。该类型名称是作为扩展自该宏的表达式的类型来使用的。
返回值
该宏返回下一个额外的参数,是一个类型为 type 的表达式。