基础NLP知识…
线性变换
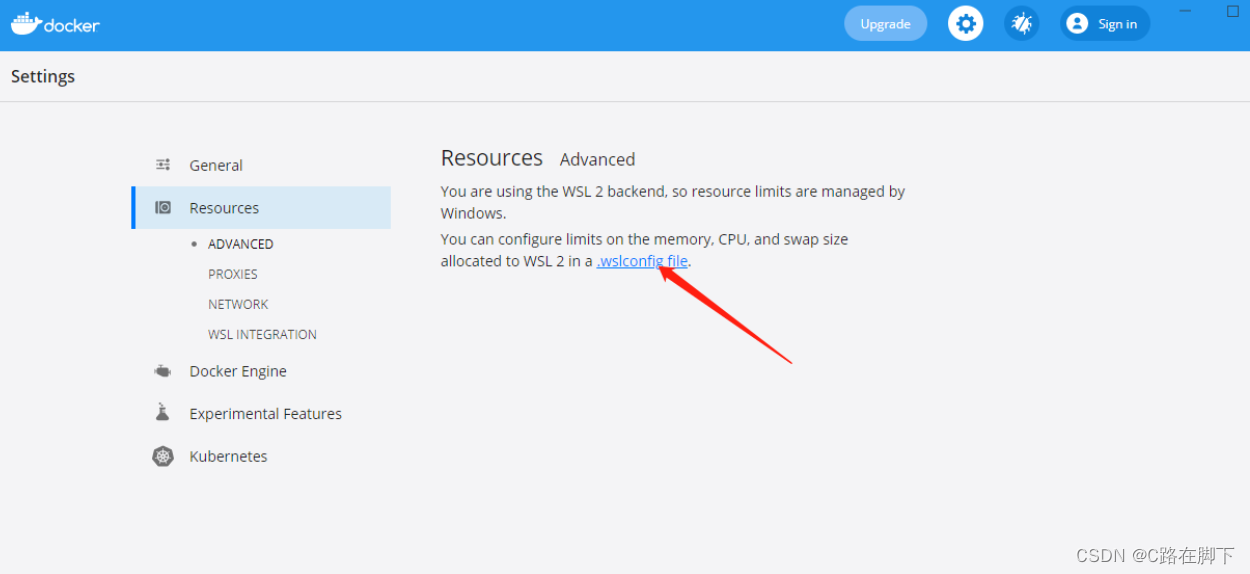
通过一个线性变换将隐藏状态映射到另一个维度空间,以获得预期维度的向量
$ outputs = hidden_layer * W + b$
这里的W是权重矩阵,b是偏置项,它们是线性变换的参数,通过训练数据学习得到。输出向量的维度由W的形状决定,如果我们想要得到一个维度为dim的多分类向量,那么W的形状应该是(hidden_state_size, dim)。
为了引入非线性,可能会在线性变换后应用一个激活函数,如Softmax。对于多分类问题,Softmax激活函数特别有用,因为它可以将输出向量转换为概率分布
$ probabilities = F.softmax(output, dim=-1)$
标准化和归一化(都是为了数据缩放):
标准化:标准化缩放数据集为均值为0,标准化差为1,$x_{new} = \frac{(x_i-\mu)}{\sigma} $, μ \mu μ是均值, σ \sigma σ是标准差
归一化:让每个元素落在0~1之间, x n e w = ( x i − x m i n ) ( x m a x − x m i n ) x_{new}=\frac{(x_i-x_{min})}{(x_{max}-x_{min})} xnew=(xmax−xmin)(xi−xmin)
BERT
在BERT(Bidirectional Encoder Representations from Transformers)模型中,[CLS]是一个特殊的标记(token),其全称为“classification token”。它主要用于分类任务中,作为整个输入序列的表示。[CLS]标记对应的最终隐藏状态被用作整个输入序列的聚合表示。在进行分类任务时,[CLS]所在位置的输出会被用来做最终的分类决策。
[SEP]用于分割句子
交叉熵(两个概率分布之间的相似性)
公式: H ( P , Q ) = − ∑ x P ( x ) l o g Q ( x ) H(P,Q)=-\sum_x P(x)logQ(x) H(P,Q)=−∑xP(x)logQ(x), P ( x ) P(x) P(x)是真实的概率分布, Q ( x ) Q(x) Q(x)是预测的概率分分布
用途:计算loss,用于表示真实分布和预测分布之间的差异
性质:非负;对称
KL散度(相对熵,用来衡量两个分布之间的差异,当用一个分布Q来拟合真实分布P时所需要的额外信息的平均量。)
公式: D K L ( P , Q ) = ∑ x P ( x ) l o g P ( x ) Q ( x ) D_{KL}(P,Q)=\sum_x P(x)log\frac{P(x)}{Q(x)} DKL(P,Q)=∑xP(x)logQ(x)P(x) P ( x ) P(x) P(x)是真实的概率分布, Q ( x ) Q(x) Q(x)是预测的概率分分布
性质:非负;不对称;不满足交换律
用途:一般用于无监督学习
对比学习(需要继续补充)
是一种机器学习技术,用于区分相似和不相似的数据点。训练最大化相似数据点之间的相似度。
batch_size和桶之间的关系:
batch_size指的是每次训练过程中,模型同时处理的数据样本的数量。较小的batch_size可以减少内存消耗并可能提高模型训练的泛化能力,而较大的batch_size可以提高数据处理效率和模型训练速度;桶是按照句子的特征进行分类,例如我们常用的是句子的长度,将句子长度相似的分配到一个桶里,这样可以在填充操作的时候少填充一些,提高计算的效率;在没有桶的时候,batch_size决定每个批次中的样本数,引入了桶之后,将样本分配到桶里,然后再在每个桶里面根据batch_size进行划分。
权重衰减:
在loss里面添加一个惩罚项来限制模型的复杂度,常被称为L2正则化。他本质上就是缩小了参数的取值范围
loss的可视化工具:animator
网络.weight.norm().item()用于计算权重的正则化
GloVe:生成的词向量是静态的,训练基于无监督学习,通过全局共现统计信息来优化词向量。它的模型结构相对简单,主要侧重于词与词之间的共现关系
ELMo:生成的词向量是动态的,根据词出现的具体上下文而变化。这使得ELMo能够更准确地表示语言,尤其是对于多义词和语境依赖的表达。使用深度学习方法,具体是通过双向LSTM来预训练一个语言模型。ELMo的训练复杂度较高,但能够捕捉到更丰富的语言特征。
Highway connection(高速连接)是一种神经网络架构,特别是在深度学习中使用的技术,旨在解决更深网络的训练难题。它由Srivastava等人在2015年提出,其核心思想是允许训练信号不经过整个网络的每一层直接传递,类似于残差网络(ResNet)中的跳跃连接(skip connection),但是在传递方式上有所不同。
Highway网络的主要特点是它引入了门控机制(gating mechanism),这些门控制了信息是直接传递还是经过非线性变换。具体来说,每一层的输出不仅取决于当前层的处理结果,还取决于前一层的输入,这种依赖关系由两个门(transform gate和carry gate)来调控。这使得网络能够自适应地决定在每一层保留多少之前层的信息,以及通过非线性变换传递多少新的信息。