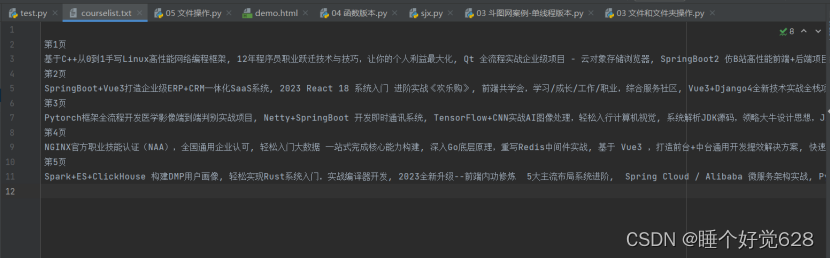
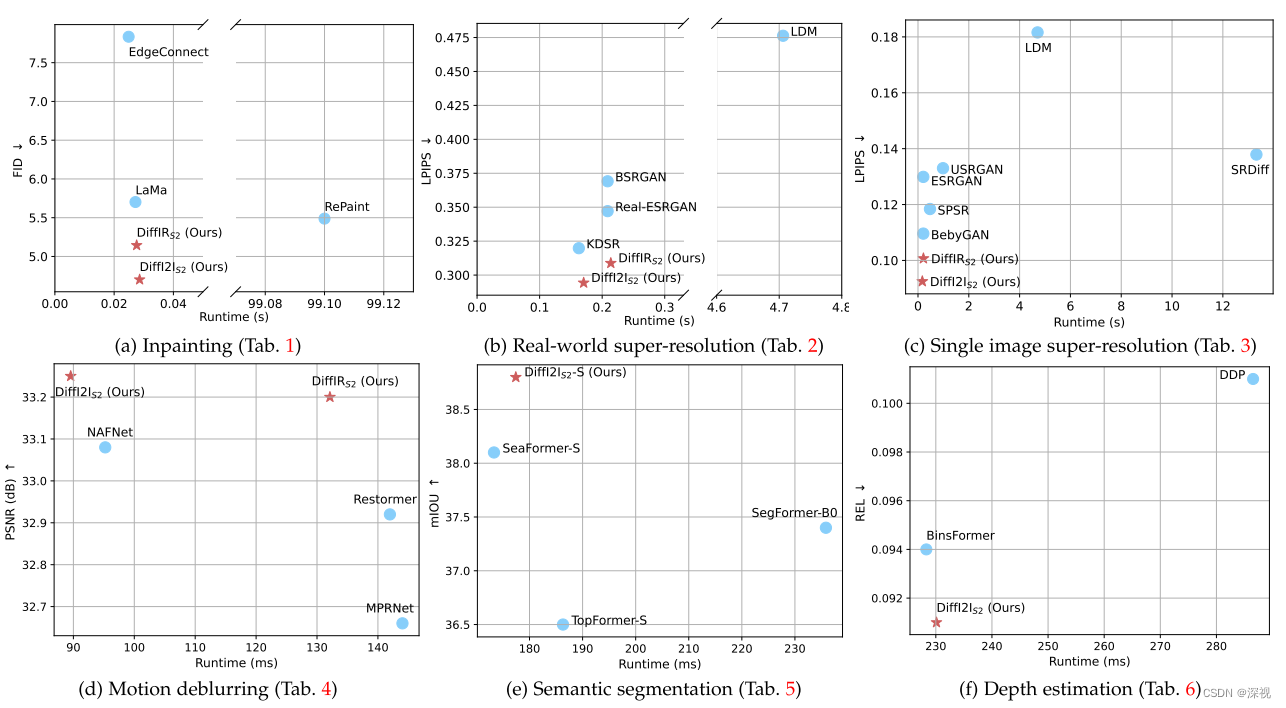
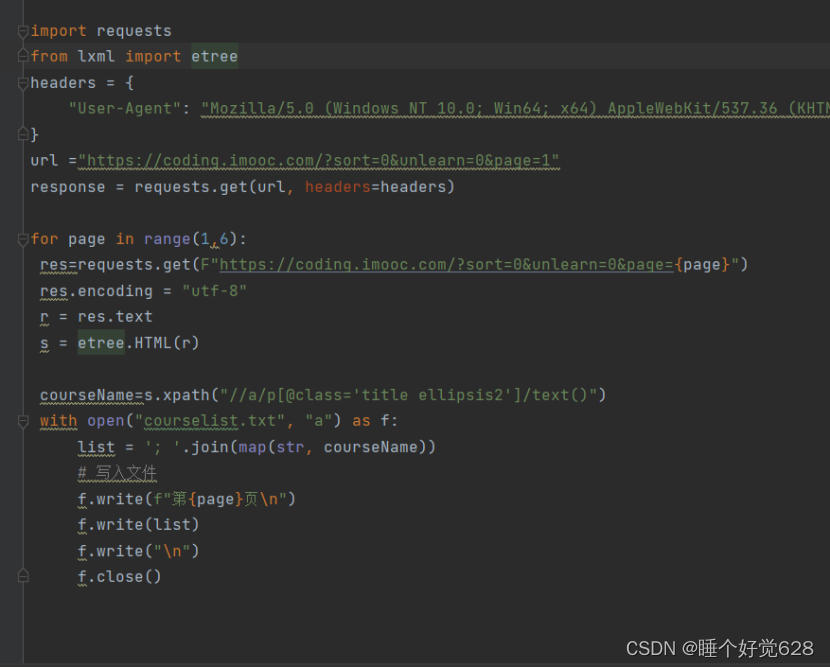
1.抓取imooc网站实战课程部分的课程名称(所有课程大概7页,抓取1到5页),并把所有课程名称存储为txt文件第一页地址
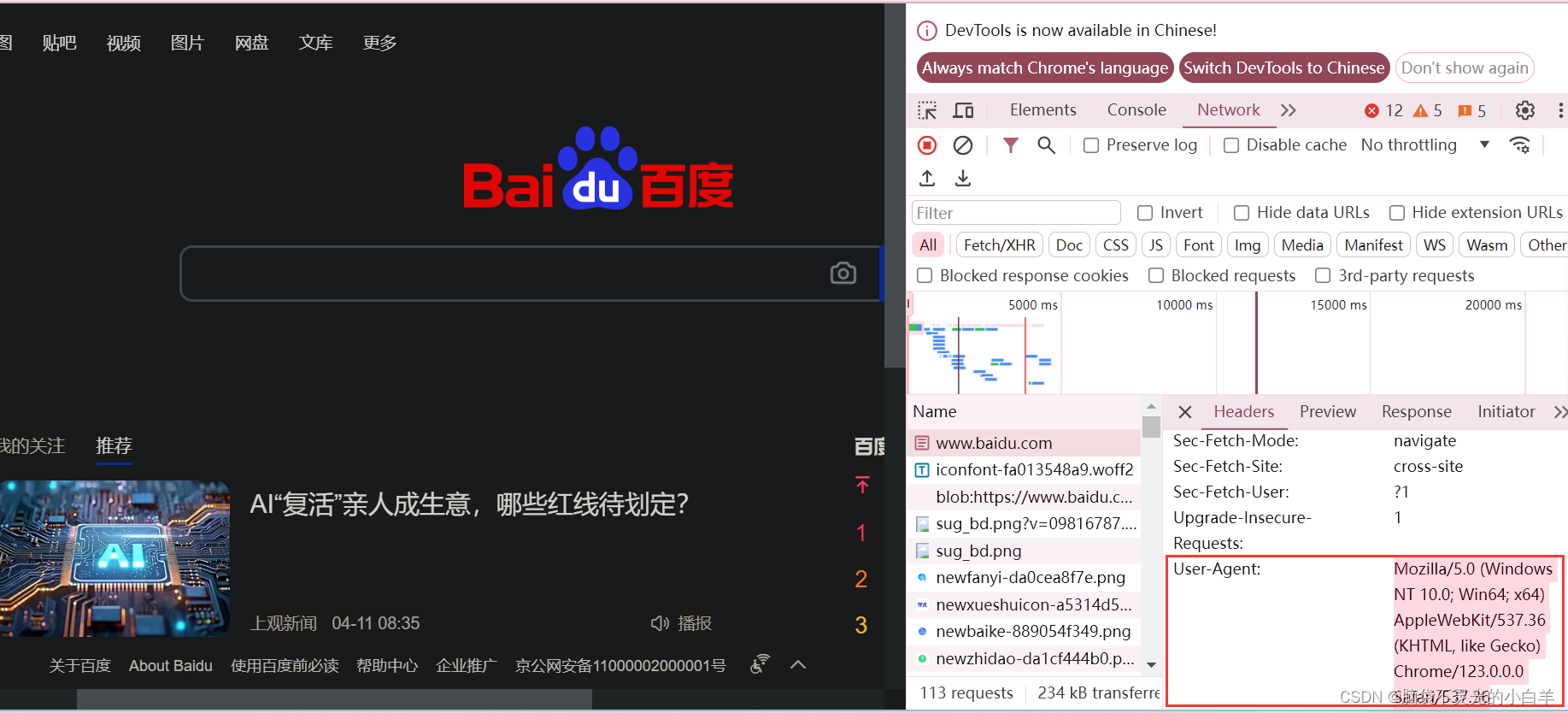
2.设置一个请求头(headers),这是一个字典,用于在HTTP请求中设置请求头信息。在这里,请求头信息被设置为一个Chrome浏览器的User-Agent字符串。
3.定义一个URL(url),这个URL是你要爬取的网页的链接。
4.使用requests.get方法发送一个GET请求到上面定义的URL,获取网页的内容,并将响应内容保存到response变量中。
5.使用一个for循环,循环遍历页码范围为1到5(共5页)。
在循环内,对于每一页:
- 使用requests.get方法发送GET请求到URL,这个URL的页码是循环变量page的值,获取页面的内容,并将响应内容保存到res变量中。
- 设置响应内容的编码方式为utf-8。
- 将响应内容保存到r变量中。
- 使用etree.HTML方法解析响应内容,并将解析结果保存到s变量中。
6.使用XPath表达式从解析的HTML中提取课程名称。XPath表达式为://a/p[@class='title ellipsis2']/text()。提取到的课程名称保存在变量courseName中。
7.使用open函数以追加模式打开文件"courselist.txt",如果文件不存在则创建该文件。
8.在文件内写入当前页码,然后将课程名称列表转换为字符串,每个课程名称之间用分号分隔,并写入文件。最后写入一个换行符。
9.关闭文件。
源代码截图:
courselist.txt内容截图: