Pandas 库是一个免费、开源的第三方 Python 库,是 Python 数据分析和机器学习的工具之一。Pandas 提供了两种数据结构,分别是 Series(一维数组结构)与 DataFrame(二维数组结构),极大地增强的了 Pandas 的数据分析能力。
import pandas as pd
import numpy as np
Series
- Series是一种类似于一维数组的对象,由下面两个部分组成:
- Values:一组数据(ndarray类型)
- index:相关的数据索引标签
- Series的创建
- 由列表或numpy数组创建
- 由字典创建
s1 = pd.Series([1,2,3,4,5])
s1

s1 = pd.Series([1,2,‘three’,4,5.1])
s1
#Series只可以存储相同类型的元素

#使用一维数组作为Series的数据源
s2 = pd.Series(np.random.randint(0,10,size=(4,)))
s2

#使用字典作为Series的数据源
dic = {
‘name’:‘bobo’,
‘age’:20,
‘salary’:1000
}
s3 = pd.Series(dic)
s3
#字典做Series的数据源,字典的key充当的是Series的索引,字典的value值充当的是Series的value值

- Series的索引
- 隐式索引:默认形式的索引(0,1,2…)
- 显式索引:自定义的索引,可以通过index参数设置显式索引
s4 = pd.Series([99,100,120],index=[‘语文’,‘数学’,‘英语’])
s4

显式索引的作用:增加了数据的可读性
- Series的索引和切片:和列表一致
s = pd.Series([99,100,120,100],index=[‘语文’,‘数学’,‘英语’,‘理综’])
s
#显式索引不会覆盖隐式索引

#索引操作
s[0],s[‘语文’],s.语文
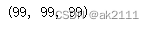
s[[0,1]],s[[‘语文’,‘理综’]]
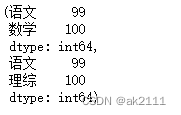
#切片
s[0:3],s[‘语文’:‘理综’]

- Series的常用属性
- shape
- size
- index
- values
s.shape#返回形状
s.size#返回Series元素的个数
s.index#返回索引
s.values#返回value值
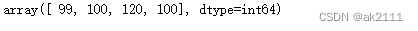
- Series的常用方法(重要)
- head(),tail()
- unique(),nunuque(),values_counts()
- isnull(),notnull()
- add(),sub(),mul(),div()
s1 = pd.Series(np.random.randint(0,10,size=(5,)),index=[‘a’,‘b’,‘c’,‘d’,‘e’])
s2 = pd.Series(np.random.randint(0,10,size=(5,)),index=[‘a’,‘b’,‘c’,‘f’,‘e’])
s1

s2

s = s1 + s2 #s1.add(s2)
s #Series的运算法则:只有索引一致的元素可以进行算术运算,否则就补空NaN

s.head(3) #只显示前3个元素
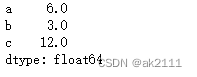
s.tail(2) #只显示后2个元素

#nuique():对Series的元素进行去重
s.unique()
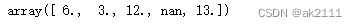
#nunique():可以统计去重后非空元素的个数
s.nunique()
4
#value_counts():可以统计Series中非空元素出现的次数
s.value_counts()

#isnull():可以对Series中存储的每一个元素进行空值判定,如果为空则返回True,否则返回False
s.isnull()

#notnull():可以对Series中存储的每一个元素进行非空判定,如果为非空则返回True,否则返回False
s.notnull()

#可以使用布尔值作为Series的索引进行取值:可以将True对应位置的元素取出,False对应的元素忽略
s[[True,True,True,False,True,False]]
#对Series中的空值进行了过滤

s[s.notnull()] #实现了空值的过滤

DataFrame(重点)
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
DataFrame的创建
- ndarray创建
- 字典创建
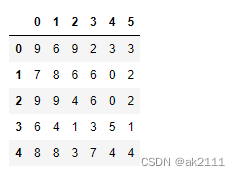
df1 = pd.DataFrame(data=np.random.randint(0,10,size=(5,6)))
df1
dic = {
‘name’:[‘bobo’,‘tom’,‘jerry’],
‘age’:[19,20,21]
}
df2 = pd.DataFrame(data=dic)
df2 #字典的key作为df的列索引

#可以指定df的显示行列索引
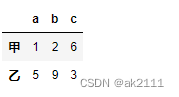
df3 = pd.DataFrame(data=np.random.randint(0,10,size=(2,3)),columns=[‘a’,‘b’,‘c’],index=[‘甲’,‘乙’])
df3
- 问题:DataFrame中是否可以存储不同类型的元素?
- 可以的
- DataFrame的属性
- values、columns、index、shape
df3.values #df的value值
df3.columns #返回列索引
df3.index #返回行索引
df3.shape #返回形状
(2,3)
#info():查看df表格的基本信息
df3.info()

- DataFrame索引操作(重点)
- 对列进行索引
- 对行进行索引
- 对元素进行索引
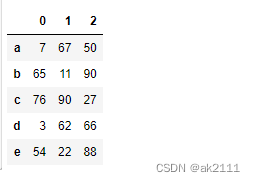
df = pd.DataFrame(data=np.random.randint(0,100,size=(5,6)),index=[‘a’,‘b’,‘c’,‘d’,‘e’])
df
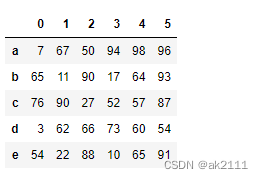
#索引取单列
df[0]

#索引取多列
df[[0,3]]
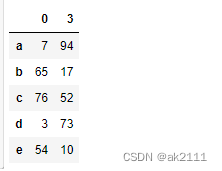
#索引取单行
df.loc[‘a’] #loc后面务必要使用显式索引

df.iloc[0] #iloc后面务必使用隐式索引

#索引取多行
df.loc[[‘a’,‘e’]]
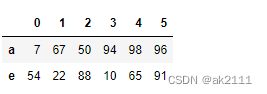
#索引取元素
df.iloc[0,1]
67
df.loc[‘a’,0]
7
- DataFrame的切片操作(重点)
- 对行进行切片
- 对列进行切片
#切行
df[0:3]
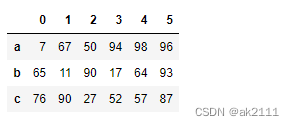
#切列
df.iloc[:,0:3]
- 时间数据类型的转换
- pd.to_datetime(col)
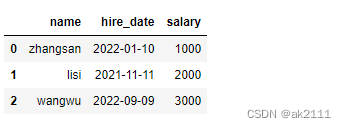
dic = {
‘name’:[‘zhangsan’,‘lisi’,‘wangwu’],
‘hire_date’:[“2022-01-10”,“2021-11-11”,“2022-09-09”],
‘salary’:[1000,2000,3000]
}
df = pd.DataFrame(dic)
df
df.info()

df[‘hire_date’] = pd.to_datetime(df[‘hire_date’])
df.info()

#提取时间类型数据中的年,月,日,周
df[‘hire_date’].dt.year #提取年份
df[‘hire_date’].dt.month #提取月份
df[‘hire_date’].dt.day #提取天
df[‘hire_date’].dt.week #提取周

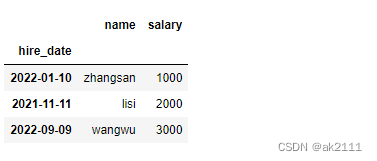
- 将某一列设置为行索引
- df.set_index()
df.set_index(‘hire_date’)
- reset_index():可以将Series转换成一个df
s = pd.Series([1,2,3,4,5],index=[‘a’,‘b’,‘c’,‘d’,‘e’])
s

s.reset_index()

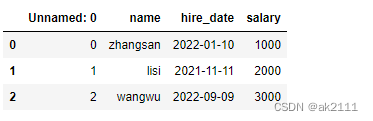
- 将df中的数据存储到外部文件中
df.to_csv(‘./df.csv’)
- 可以将外部文件的数据加载到df
data = pd.read_csv(‘df.csv’)
data
#删除指定的行or列
data.drop(columns=‘Unnamed: 0’,inplace=True) #删除列
#删除行
data.drop(index=0,inplace=True)
data
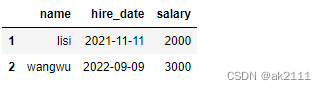
- 如何将MySQL和pandas进行关联
- 工具:pymysql(可以使用python程序远程连接指定的数据库)
- 安装工具:pip install pymysql
import pymysql
#1.使用pymysql连接数据库
conn = pymysql.Connect(
host = “127.0.0.1”, #数据库服务器的ip地址
port = 3306, #mysql端口号
user = ‘root’,#用户名
password = ‘自己设置的MySQL密码’,
db = ‘testdb’
)
#2.将数据库库表中的数据读取加载到df
sql = ‘select job,ename from emp where sal > 1000’
df = pd.read_sql(sql,conn)
df

源文件可在这里下载:
https://download.csdn.net/download/ak2111/89023256?spm=1001.2014.3001.5501



















![[Vue warn]: Invalid vnode type when creating vnode: false](https://img-blog.csdnimg.cn/direct/93d5ab4356144cf88d8488c571a2adba.png)