中文分词库 Python windows
目前项目中用到了一些自然语言处理的一些知识,虽然之前多少有了解,但是没有详细总结过,这次就总结一下常用的这些中文分词库,网上搜了搜相应的资料要不半残要不收费,没办法我去把所有的文档都看了一遍,有相似经历的同学一定知道看完得多疲惫,中国有非常多优秀的NLP研究者,但是愿意可能花费大量的心血总结一篇基础向的文档的还是比较少,自己做课题的时候知道如果在入门阶段找到一篇总结性质的高质量内容得多高兴。每次刷新看见点赞和收藏的小红点的时候,动力都多增添了几分。
文章目录
0.前置:新建一个环境(有基础可跳过)
为了在一个环境下运行所有的分词库,所以新建了一个anaconda的环境,python版本参考了官方的安全版本中最新的3.10,避免各种库不适应各种的版本。
这里把网页链接给上,时间长了之后可以进来看一下最新的版本
python下载官网:https://www.python.org/downloads/
新建一个环境的命令
conda create --name NLP python=3.10
1.jieba
1.1 jieba简介
jieba分词是国内目前最知名的分词库,其有三种常用的分词模式精确模型,全模式,和搜索引擎模式,支持繁体
其实还有一种paddle模型,但是其需要安装的库paddlepaddle-tiny库已经不支持更新,目前只支持到3.7版本。


1.1 jieba安装
官方GitHub文档网址:https://github.com/fxsjy/jieba

安装命令:
jieba库安装
pip install jieba
1.3 jieba分词代码
分词代码:
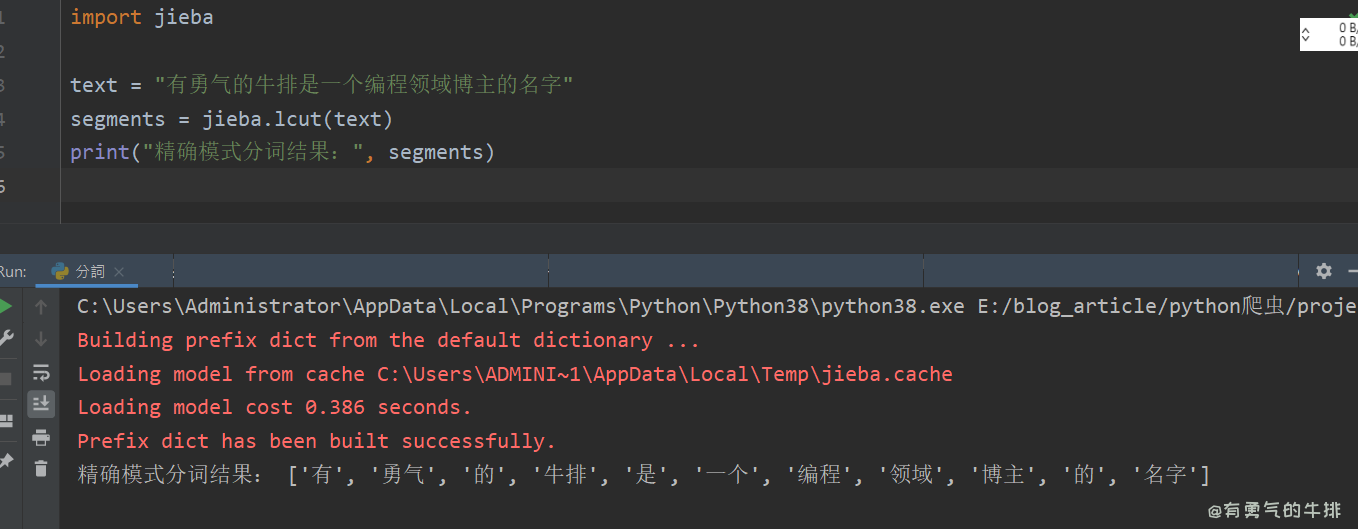
import jieba
text = "我爱学习自然语言处理"
seg_list = jieba.cut(text, cut_all=False)
print(list(seg_list)) # 精确模式
seg_list = jieba.cut(text) # 默认是精确模式
print(list(seg_list))
seg_list = jieba.cut(text, cut_all=True)
print(list(seg_list)) # 全模式
seg_list = jieba.cut_for_search(text) # 搜索引擎模式
print(list(seg_list))
运行结果:
Building prefix dict from the default dictionary ...
Loading model from cache D:\Temp\jieba.cache
Loading model cost 0.545 seconds.
Prefix dict has been built successfully.
['我', '爱', '学习', '自然语言', '处理']
['我', '爱', '学习', '自然语言', '处理']
['我', '爱', '学习', '自然', '自然语言', '语言', '处理']
['我', '爱', '学习', '自然', '语言', '自然语言', '处理']
2.Hanlp
2.1Hanlp简介
HanLP旨在提供面向生产环境的一站式语言处理解决方案。它支持包括中文在内的多种语言,并且拥有广泛的功能,如分词、词性标注、命名实体识别、依存句法分析、语义依存分析、关键词提取、自动摘要、文本分类和情感分析等。

2.2Hanlp安装
在Hanlp的安装文档中介绍了Hanlp一直以来的版本,可以说是非常详细,我给大家把里面给的流程图截个图出来,然后我直接调一个最基础的然后实践一下,降低入门难度。
安装文档网址:https://hanlp.hankcs.com/install.html

他里面给了各种版本安装详细介绍,和优缺点对比,甚至还抨击了网上下载本地版的安装教程库🤧,那我就分享一个最最最基础的,充分尊重作者,如果大家想具体了解Hanlp,请认真阅读文档。

Resful版需要联网应该然后初学者也有点学习成本,我们直接安装一个本地完整版,避免出现各种奇奇怪怪的版本依赖问题
pip install hanlp[full]
运行之后表示成功安装了这些库
Successfully installed MarkupSafe-2.1.5 absl-py-2.1.0 astunparse-1.6.3 charset-normalizer-3.3.2 colorama-0.4.6 fasttext-wheel-0.9.2 filelock-3.13.3 flatbuffers-24.3.7 fsspec-2024.3
.1 gast-0.5.4 google-pasta-0.2.0 grpcio-1.62.1 h5py-3.10.0 hanlp-2.1.0b57 hanlp-common-0.0.20 hanlp-downloader-0.0.25 hanlp-trie-0.0.5 huggingface-hub-0.22.0 jinja2-3.1.3 keras-3.1
.1 libclang-18.1.1 markdown-3.6 markdown-it-py-3.0.0 mdurl-0.1.2 ml-dtypes-0.3.2 mpmath-1.3.0 namex-0.0.7 networkx-3.2.1 optree-0.11.0 packaging-24.0 penman-1.2.1 perin-parser-0.0.
12 phrasetree-0.0.9 protobuf-4.25.3 pybind11-2.11.1 pygments-2.17.2 pynvml-11.5.0 pyyaml-6.0.1 regex-2023.12.25 requests-2.31.0 rich-13.7.1 safetensors-0.4.2 scipy-1.12.0 sentencep
iece-0.2.0 six-1.16.0 sympy-1.12 tensorboard-2.16.2 tensorboard-data-server-0.7.2 tensorflow-2.16.1 tensorflow-intel-2.16.1 tensorflow-io-gcs-filesystem-0.31.0 termcolor-2.4.0 toke
nizers-0.15.2 toposort-1.5 torch-2.2.1 tqdm-4.66.2 transformers-4.39.1 urllib3-2.2.1 werkzeug-3.0.1 wrapt-1.16.0
2.3 Hanlp分词代码
import hanlp
# 加载分词模型 hanlp.pretrained.tok.COARSE_ELECTRA_SMALL_ZH
tokenizer = hanlp.load(hanlp.pretrained.tok.COARSE_ELECTRA_SMALL_ZH)
text = "我爱学习自然语言处理"
运行结果
['我', '爱', '学习', '自然', '语言', '处理']
第一次运行需要联网会下载模型我的是下载到了这个文件夹下
C:\Users\系统用户名\AppData\Roaming\hanlp\tok

分词模型选择见文档该部分
分词部分:https://hanlp.hankcs.com/docs/api/hanlp/pretrained/tok.html

也可以直接预先手动下载
每个模型版本下面有一个网页链接,将网页链接输入到浏览器上按回车访问,会下载该包含模型的pt文件的安装包。

之后解压到项目文件夹下,就是你分词的代码的文件夹下
解压之后里面的东西可以看一眼

然后将load中填入文件夹路径运行结果是一样的。
import hanlp
# 加载分词模型
# tokenizer = hanlp.load(hanlp.pretrained.tok.COARSE_ELECTRA_SMALL_ZH)
tokenizer = hanlp.load("coarse_electra_small_20220616_012050")
text = "我爱学习自然语言处理"
seg_list = tokenizer(text)
print(seg_list)
3.SnowNLP
3.1SnowNLP简介
这个是一个比较老的的库,GitHub,最后一次更新是7年前(此时2024年),但是还是有6.3k个Star,基本的分词,词性判断,情感倾向判断,获取拼音,繁体分词,都能实现,文档里全是干货,文档里还说支持自己训练,这个有待研究,先关注一下简单基础的分词功能吧。
官方文档: https://github.com/isnowfy/snownlp

3.2 SnowNLP安装
pip install snownlp
3.3 SnowNLP分词代码
from snownlp import SnowNLP
# 待分词的文本
text = "我爱学习自然语言处理"
# 创建SnowNLP对象
s = SnowNLP(text)
# 进行分词
words = s.words
# 打印分词结果
print(list(words))
分词结果:
['我', '爱', '学习', '自然', '语言', '处理']
4.thulac (清华)
4.1thulac简介
清华做的一个库也是上古时期的了,该库自我简介的自己的优点为:
- 能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
- 准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
- 速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
官方网址:https://github.com/thunlp/THULAC-Python

4.2thulac安装
pip install thulac
4.3thulac分词代码
import thulac
# 初始化THULAC,使用默认模型
thu = thulac.thulac(seg_only=True) # 只进行分词,不进行词性标注
# 待分词的文本
text = "我爱学习自然语言处理"
# 执行分词
tokens = thu.cut(text, text=True)
print(tokens)
运行结果:
Model loaded succeed
我 爱 学习 自然 语言 处理
5.LTP (哈工大)
5.1LTP简介
哈工大的分词库,目前还在更新,使用的是Pytorch的模型,除了安装ltp库之外,还需要安装transform库和ptorch,也就是说该分词库应该是支持GPU推理的。
官方文档: https://github.com/HIT-SCIR/ltp

5.2LTP安装
下面是官方的安装文档部分的内容,直接复制过来了,这里的pytorch应该默认都是cpu的,如果想用GPU推理的话这里需要安装GPU版本,如果是新手就方法一直接安装就完事了,剩下的啥也不用想。
# 方法 1: 使用清华源安装 LTP
# 1. 安装 PyTorch 和 Transformers 依赖
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch transformers
# 2. 安装 LTP
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ltp ltp-core ltp-extension
# 方法 2: 先全局换源,再安装 LTP
# 1. 全局换 TUNA 源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 2. 安装 PyTorch 和 Transformers 依赖
pip install torch transformers
# 3. 安装 LTP
pip install ltp ltp-core ltp-extension
然后是模型下载,下载需要到HuggingFace上下载

选这个small然后把文件下载挨个点一遍,然后放到一个文件夹里起名small然后放到项目文件夹下


5.3LTP分词代码
from ltp import LTP
ltp = LTP("small")
output = ltp.pipeline(["他叫汤姆去拿外衣。"], tasks=["cws"])
# 使用字典格式作为返回结果
print(output.cws)
分词结果:
Loading weights from local directory
[['他', '叫', '汤姆', '去', '拿', '外衣', '。']]
6.其它(各种原因没使用成功)
6.1FoolNLTK -Linux
官方文档:https://github.com/rockyzhengwu/FoolNLTK?tab=readme-ov-file

失败原因:
只支持Linux系统,Windows能安装不能用,有待测试

6.2 pkuseg-python(北大)-安装不上
官方文档:https://github.com/lancopku/pkuseg-python

失败原因安装不上:然后搜了一下安装不上的还挺多,目前不知道什么情况,已经提问了,不知道能不能得到回复。

6.3 CoreNLP (斯坦福)-JAVA语言
官方文档:https://github.com/stanfordnlp/CoreNLP


失败原因:这是一个Java库不是Python的
6.4FastText JAVA-macOS
文档地址:https://github.com/facebookresearch/fastText

失败原因:系统和语言都不满足条件


















![每日一题--- 环形链表[力扣][Go]](https://img-blog.csdnimg.cn/img_convert/9cbc3866fc7c3b6fc90977e59e47f988.png)