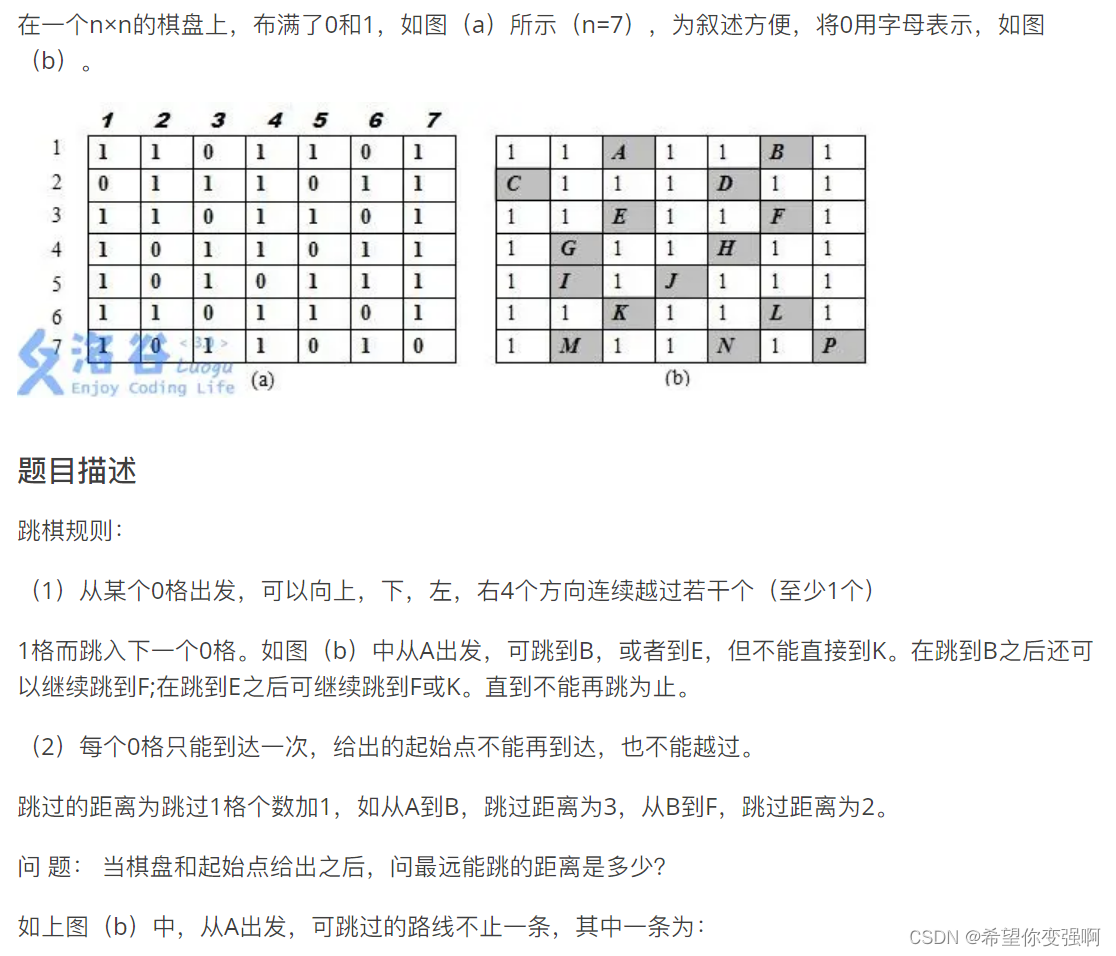
导语:在大数据时代,处理和分析结构化数据是每个数据工程师和数据科学家的核心任务之一。Apache Spark作为一个强大的大数据处理框架,提供了Spark SQL作为其模块之一,专门用于处理结构化数据。本文将深入介绍Spark SQL的强大功能,并通过使用Java脚本和生活中的例子来演示如何进行SQL查询、数据聚合和表连接等操作。
1. 引言
Apache Spark是一个快速、通用且易于使用的大数据处理框架,它提供了多个模块来满足不同的数据处理需求。其中,Spark SQL是Spark的一个模块,专门用于处理结构化数据。它提供了强大的功能和API,使得处理和分析结构化数据变得更加高效和便捷。
在本文中,我们将通过一个生活中的例子来深入学习Spark SQL的使用。我们假设有一个包含用户信息的表格数据,并使用Spark SQL来查询、聚合和连接这些数据。我们将使用Java脚本来模拟执行这些操作,并展示相应的结果。
2. 使用Spark SQL进行查询
首先,让我们使用Spark SQL来查询用户信息。假设我们有一个名为users的表格,包含字段id、name、age和city。我们想要从该表中选择年龄大于25岁的用户。
以下是使用Java脚本执行该查询的示例代码:
// 创建SparkSession对象
SparkSession spark = SparkSession.builder()
.appName("Spark SQL Example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
// 加载数据并创建DataFrame
String filePath = "path/to/users.csv";
Dataset<Row> usersDF = spark.read().csv(filePath)
.toDF("id", "name", "age", "city");
// 将DataFrame注册为临时表
usersDF.createOrReplaceTempView("users");
// 使用Spark SQL执行查询
Dataset<Row> result = spark.sql("SELECT * FROM users WHERE age > 25");
result.show();
在这个示例中,我们首先创建了一个SparkSession对象,然后加载数据并创建了一个DataFrame。接下来,我们使用createOrReplaceTempView()方法将DataFrame注册为一个临时表,以便使用Spark SQL来执行查询。最后,我们使用spark.sql()方法执行SQL查询语句,并使用show()方法打印结果。
3. 使用Spark SQL进行数据聚合
除了查询,Spark SQL还提供了丰富的数据聚合功能。让我们继续使用上述的users表格数据,计算用户的平均年龄和每个城市的用户数量。
以下是使用Java脚本执行数据聚合的示例代码:
// 使用Spark SQL进行数据聚合
Dataset<Row> aggregated = spark.sql("SELECT city, AVG(age) AS avg_age, COUNT(*) AS user_count FROM users GROUP BY city");
aggregated.show();
在这个示例中,我们使用GROUP BY子句对城市进行分组,并使用AVG()和COUNT()函数计算平均年龄和用户数量。最后,我们使用show()方法打印结果。
4. 使用Spark SQL进行表连接
表连接是处理结构化数据时常用的操作之一。让我们继续使用上述的users表格数据,并将其与另一个名为orders的表格连接,以获取用户的订单信息。
以下是使用Java脚本执行表连接的示例代码:
// 加载另一个表格并创建DataFrame
String ordersFilePath = "path/to/orders.csv";
Dataset<Row> ordersDF = spark.read().csv(ordersFilePath)
.toDF("user_id", "order_id", "order_date");
// 将DataFrame注册为临时表
usersDF.createOrReplaceTempView("users");
ordersDF.createOrReplaceTempView("orders");
// 使用Spark SQL执行表连接
Dataset<Row> joined = spark.sql("SELECT u.name, o.order_id, o.order_date FROM users u JOIN orders o ON u.id = o.user_id");
joined.show();
在这个示例中,我们首先加载了另一个表格orders并创建了一个DataFrame。然后,我们将users表格和orders表格分别注册为临时表,以便使用Spark SQL来执行表连接操作。最后,我们使用spark.sql()方法执行SQL查询语句,并使用show()方法打印结果。
5. 总结
通过本文,我们深入学习了Spark SQL的强大功能,并通过使用Java脚本和生活中的例子来演示了如何使用Spark SQL进行查询、数据聚合和表连接等操作。Spark SQL提供了丰富的功能和API,使得处理和分析结构化数据变得更加高效和便捷。
希望本文对您有所帮助,并激发您对Spark SQL的兴趣。如果您想要了解更多关于Spark SQL的内容,可以继续探索Spark的官方文档和其他相关资源。
感谢阅读本文,如果您有任何问题或建议,请随时留言。祝您在使用Spark SQL处理结构化数据的旅程中取得成功!
参考文献:
(博客内容结束)
希望这篇博客能满足您的需求!如果您有任何其他要求或疑问,请随时告诉我。






















![[第五章]图论&&BFS](https://img-blog.csdnimg.cn/direct/a0c7768e2b714d3d9a7c8c224a61fa8e.png)