AI大模型学习
在当前技术环境下,AI大模型学习不仅要求研究者具备深厚的数学基础和编程能力,还需要对特定领域的业务场景有深入的了解。通过不断优化模型结构和算法,AI大模型学习能够不断提升模型的准确性和效率,为人类生活和工作带来更多便利。
方向一:AI大模型学习的理论基础
(1)神经网络:神经网络是一种受到生物神经系统启发的计算模型,它由多个神经元组成,每个神经元都与下一层的神经元相连接,并具有权重。大型 AI 模型通常是基于深度神经网络(DNN)构建的,其中包括多个层,每一层都包含多个神经元。
(2)深度学习:深度学习是一种基于神经网络的机器学习方法,其中网络有多个隐含层(即深度),可以自动从数据中学习特征表示。深度学习被广泛应用于计算机视觉、自然语言处理和语音识别等领域。
(3)反向传播算法:这是一种训练神经网络的优化方法,被广泛用于大模型训练。它通过计算损失函数对网络中每个参数的梯度,并沿着梯度的方向更新参数,以最小化损失函数。
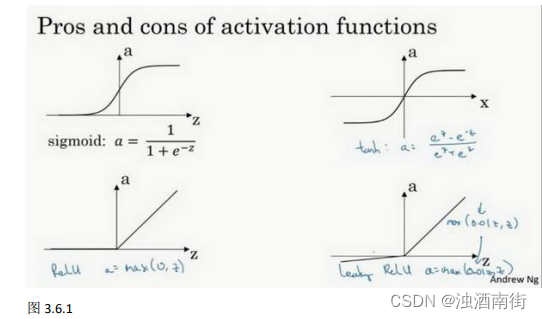
(4)激活函数:在神经网络中,激活函数用于计算神经元的输出。常用的激活函数包括sigmoid、ReLU、tanh等。激活函数的选择可以影响神经网络的表示能力和学习能力。
(5)优化算法:优化算法用于找到神经网络的最优参数配置,以最小化损失函数。常用的优化算法包括随机梯度下降(SGD)、Adam、Adagrad等。
正则化技术:正则化技术用于防止神经网络过拟合训练数据。常用的正则化技术包括L1正则化、L2正则化和dropout。
(6)数据增强:它是一种在机器学习和深度学习中常用的技术,旨在通过对原始数据进行各种变换和扭曲,生成更多样化、更丰富的数据集,以增加模型的泛化能力和鲁棒性。数据增强的目标是通过对原始数据施加随机性的变换,生成具有相同标签但稍微不同的样本,从而扩充训练数据的规模,减少过拟合,并提高模型的性能。
(7)分布式计算:这是一种计算范式,它涉及将一个计算任务分解成多个子任务,并在多个计算节点上并行执行这些子任务。这种方式可以加速计算速度,提高计算资源的利用率,并允许处理大规模数据集。它在大数据处理、机器学习、人工智能、科学计算等领域得到了广泛应用。常见的分布式计算框架包括Apache Hadoop、Apache Spark、Apache Flink、MPI(Message Passing Interface)等。这些框架提供了高级的编程接口和运行时环境,简化了分布式计算任务的开发和部署。
这些理论基础为AI大模型学习提供了框架和方法,使得我们能够训练出更复杂、更精确的模型来应对各种实际问题。
方向二:AI大模型的训练与优化
数据准备:
- 收集和清洗数据:准备用于训练的数据集,确保数据质量和标注准确性。
- 数据增强:对数据进行增强,以扩充训练集并提高模型的泛化能力。
选择模型架构:
- 选择合适的模型架构:根据任务需求选择适当的模型类型,如卷积神经网络(CNN)、循环神经网络(RNN)或变换器(Transformer)等。
- 模型大小和复杂度:根据数据规模和任务复杂度选择合适的模型大小和复杂度。
初始化模型参数:
- 随机初始化:使用随机初始化来初始化模型参数。
- 预训练:使用预训练的模型参数进行初始化,以加速训练和提高模型性能。
选择损失函数和优化器:
- 损失函数:选择适当的损失函数,如交叉熵损失函数、均方误差损失函数等,根据任务需求进行选择。
- 优化器:选择合适的优化器,如随机梯度下降(SGD)、Adam、RMSprop 等,并调整学习率。
训练模型:
- 前向传播:将数据输入模型,计算模型的输出。
- 反向传播:计算损失函数对模型参数的梯度,并更新参数。
- 批量训练:使用批量训练的方式来加速训练过程,并减小梯度的方差。
评估模型性能:
- 验证集评估:使用验证集来评估模型在训练过程中的性能,并调整超参数。
- 测试集评估:最终使用测试集来评估模型的泛化能力和性能。
调整和优化:
- 超参数调优:调整学习率、批量大小、模型大小等超参数,以优化模型性能。
- 正则化:使用正则化技术如 L1 正则化、L2 正则化等来避免过拟合。
- 提前停止:使用提前停止技术来防止模型过拟合训练数据。
部署和应用:
- 部署到生产环境:将训练好的模型部署到生产环境中,以供实际应用和服务。
- 持续监控和优化:持续监控模型的性能,及时调整和优化模型,以保持模型的良好性能。
- 总结:训练和优化大型 AI 模型是一个迭代的过程,需要不断地尝试和调整,以找到最佳的模型和参数配置。随着数据规模和任务复杂度的增加,训练和优化大型 AI 模型的挑战也会不断增加,需要使用更加先进的技术和方法来应对。
方向三:AI大模型在特定领域的应用
自然语言处理 (NLP):
- 语言模型:如GPT、BERT等大型语言模型,用于文本生成、语言理解、问答系统等任务。
- 机器翻译:使用Seq2Seq模型、Transformer等进行机器翻译,如Google的GNMT系统。
- 文本分类和情感分析:用于垃圾邮件过滤、情感分析等任务。
计算机视觉 (CV):
- 目标检测和识别:使用YOLO、Faster R-CNN等模型进行物体检测和识别,如智能安防系统、自动驾驶汽车等。
- 图像生成和修复:如GAN、Pix2Pix等模型用于图像生成和修复,如人脸生成、图像修复等。
- 图像分割:用于医学图像分割、地图制作等领域。
语音识别 (ASR):
- 声学模型和语言模型:用于语音识别的声学模型和语言模型,如DeepSpeech、Transformer等。
- 语音生成:使用WaveNet、Tacotron等模型进行语音生成和合成。
医疗健康:
- 医学影像诊断:利用深度学习模型进行医学影像诊断,如肿瘤检测、疾病诊断等。
- 个性化医疗:根据患者的基因信息和临床数据,进行个性化的疾病预防和治疗。
金融领域:
- 风险管理:利用大数据和机器学习模型进行风险评估和管理,如信用评分、欺诈检测等。
- 量化交易:使用机器学习模型进行股票市场分析和量化交易,如AlphaGo等。
智能推荐系统:
- 电商推荐:利用用户行为数据和商品信息,构建个性化的商品推荐系统,如亚马逊的商品推荐系统。
- 内容推荐:根据用户的兴趣和行为,推荐适合的新闻、视频、音乐等内容,如Netflix的电影推荐系统。
智能交通:
- 交通管理:利用大数据和智能算法进行交通拥堵监测和调度优化,如城市智能交通系统。
- 自动驾驶:利用深度学习和感知技术,实现自动驾驶汽车的环境感知和决策控制。
游戏行业:
- 游戏智能体:使用强化学习等技术构建游戏智能体,如AlphaGo、OpenAI的Dota 2智能体等。
方向四:AI大模型学习的伦理与社会影响
隐私问题:大型AI模型需要大量的数据进行训练,而这些数据可能包含个人隐私信息。因此,数据收集、存储和处理过程中的隐私保护问题成为关注焦点。
数据偏差和公平性:训练数据中的偏差可能会导致模型在某些群体或种类上表现不佳,进而加剧社会不平等。例如,在招聘和贷款决策中使用AI模型可能会造成性别、种族或经济地位等方面的歧视。
透明度和解释性:大型AI模型往往是黑盒子,难以理解其决策过程和推理逻辑,这给其应用带来了可解释性和透明度方面的挑战。对于一些关键领域,如医疗诊断和司法决策,透明度和解释性尤为重要。
社会就业和劳动力市场:自动化和智能化技术的发展可能会影响传统的劳动力市场,导致某些行业和职业的消失或减少。这可能引发社会不稳定和失业问题。
安全和风险:大型AI模型可能受到恶意攻击或滥用,造成严重的安全和风险问题。例如,对抗性样本攻击可以欺骗模型,导致错误的决策和预测。
社会控制和权力关系:AI技术的广泛应用可能会改变社会权力关系和控制结构,引发新的社会政治问题。谁控制和拥有AI技术可能会影响未来社会的发展方向。
人类价值观和道德标准:AI大模型的应用涉及到一系列复杂的道德和价值观问题,如人工智能是否应该具有道德判断能力,以及AI技术如何与人类价值观相协调等。
方向五:未来发展趋势与挑战
发展趋势:
持续技术进步:AI技术将继续快速发展,包括深度学习、自然语言处理、计算机视觉等领域的进步,以及量子计算、脑机接口等新兴技术的应用。
多模态AI:未来的AI系统将更多地结合多种数据和感知模态,实现更复杂、更智能的决策和交互,如语音、图像、视频等。
自动化和智能化应用:AI技术将在各个行业和领域广泛应用,包括自动驾驶、智能制造、智能医疗、智能物流等,推动产业升级和经济增长。
个性化和定制化服务:AI技术将带来更个性化、定制化的服务和产品,满足用户多样化的需求,如个性化推荐、定制化医疗等。
人机协同合作:人工智能将与人类更紧密地合作,共同完成复杂的任务和工作,提高生产效率和生活质量,如协作机器人、智能助理等。
社会责任和可持续发展:AI技术的发展需要考虑其对社会的影响,推动AI技术的可持续发展和社会责任,确保其造福全人类。
挑战:
数据隐私和安全:随着AI应用的增多,数据隐私和安全问题将变得更加突出,需要加强数据保护和安全技术。
公平和道德:AI系统可能存在偏见和歧视问题,需要解决数据偏差、算法公平性和道德问题,确保AI技术的公正和公平。
人才短缺和人机关系:AI领域的人才短缺和人机关系问题将是未来的挑战,需要培养更多的人工智能人才,推动人机协同合作。
社会影响和伦理问题:AI技术的广泛应用可能会对社会产生深远影响,需要解决与之相关的伦理和社会问题,如就业变革、社会不平等等。
监管和政策:AI技术的发展需要建立健全的监管和政策框架,平衡创新和风险,保护消费者权益和社会公共利益。
环境和可持续发展:AI技术的高能耗和碳排放可能对环境造成负面影响,需要寻找更环保、可持续的AI技术和应用方式。