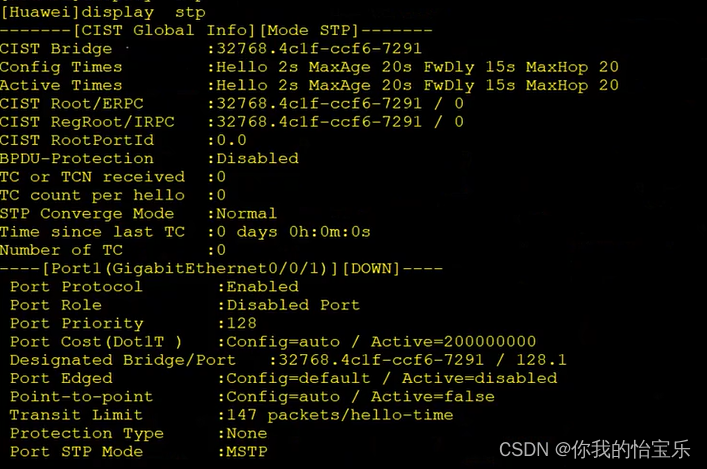
Scikit-Learn逻辑回归二:多项式与正则化
1、多项式回归回顾
本文接上篇:Scikit-Learn逻辑回归(一)
上篇中,我们详细介绍了逻辑回归的概念、原理和推导,以及Scikit-Learn线性回归模型在鸢尾花数据集中的应用。本文主要介绍如何在逻辑回归中使用多项式特征、正则化,以提高模型性能
1.1、为什么使用多项式
以下举例说明。准备二分类样本数据并绘制:
import numpy as np
import matplotlib.pyplot as plt
# 随机数种子,只需设置一次,设置后只要种子不变,每次生成相同的随机数
np.random.seed(666)
# 构建均值为0,标准差为1(标准正态分布)的矩阵,200个样本
X = np.random.normal(0, 1, size=(200, 2))
# 构建一个生成y的函数,将y以>1.5还是<1.5进行分类
y = np.array(X[:, 0] ** 2 + X[:, 1] ** 2 < 1.5, dtype='int')
# 绘制样本数据
plt.xlim(-4, 4)
plt.ylim(-4, 4)
plt.scatter(X[y == 0, 0], X[y == 0, 1])
plt.scatter(X[y == 1, 0], X[y == 1, 1])
plt.show()
样本数据分布如图所示:

使用逻辑回归(二分类)训练模型:
from sklearn.linear_model import LogisticRegression
# 训练逻辑回归模型
lr = LogisticRegression()
lr.fit(X, y)
# 准确度评分
print(lr.score(X, y)) # 0.605
绘制该样本数据在逻辑回归模型上的决策边界(函数详解见上篇):
# 绘制决策边界
decision_boundary(lr, axis=[-4, 4, -4, 4])
plt.scatter(X[y == 0, 0], X[y == 0, 1])
plt.scatter(X[y == 1, 0], X[y == 1, 1])
plt.show()
决策边界如图所示:

从图中可以看到,我们线性决策边界明显无法将样本分成两类,训练的模型准确度评分很低
从样本数据图可以看出,二分类的决策边界应该是一个圆或椭圆。圆的标准方程为
( x − a ) 2 + ( y − b ) 2 = r 2 (x-a)^2+(y-b)^2=r^2 (x−a)2+(y−b)2=r2
将圆沿特定方向压缩或伸长即可得到椭圆(标准方程):
x 2 a 2 + y 2 b




![[Python] 什么是<span style='color:red;'>逻辑</span><span style='color:red;'>回归</span>模型?使用<span style='color:red;'>scikit</span>-<span style='color:red;'>learn</span>中的LogisticRegression来解决乳腺癌数据集上的二分类问题](https://img-blog.csdnimg.cn/direct/3585c45763514fecb1b95de83c3a0084.png)