简介
研究了最初用于图像生成的去噪扩散模型(DDM)的表示学习能力
解构DDM,逐步将其转变为经典的去噪自动编码器(DAE)
探索现代ddm的各个组成部分如何影响自监督表征学习
结论:
只有很少的现代组件对于学习良好的表示是至关重要的,而其他许多组件则是不必要的
DDM的表示能力主要是由去噪驱动的过程获得的,而不是扩散驱动的过程
成果:一种高度简化的方法,并且在很大程度上类似于经典的DAE——l-DAE
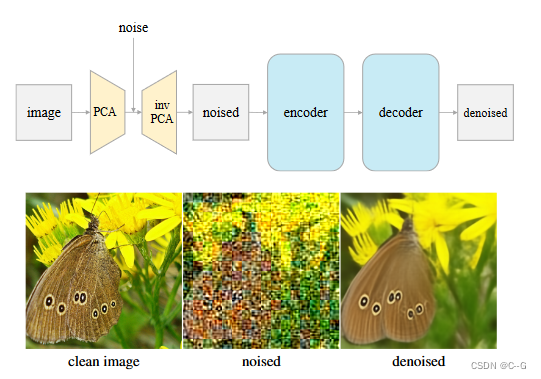
通过主成分基(即V)将输入图像投影到隐空间中,在隐空间中加入噪声,并通过逆主成分基将带噪声的隐投影回图像空间
上图(中间,底部)显示了在潜在空间中添加噪声的示例图像
将这个有噪声的图像作为网络的输入,可以应用一个标准的ViT网络,它直接对图像进行操作,就好像没有tokenizer一样
背景
Denoising Diffusion Models (DDM) 实现了令人印象深刻的图像生成质量,特别是对于高分辨率、逼真的图像,对于理解视觉内容似乎具有很强的识别表征
t时间步的噪声图像为

ϵ ∼ N ( 0 , I ) \epsilon \sim N(0,I) ϵ∼N(0,I), γ t 2 + σ t 2 = 1 \gamma^2_t + \sigma^2_t=1 γt2+σt2=1
网络预测噪声拟合增加的噪声
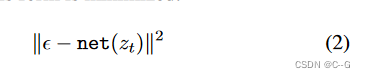
实验过程
noise
去掉DDM的分类条件
假设直接对模型进行类标签的调节可以减少模型对与类标签相关的信息编码的需求。移除类条件可以迫使模型学习更多的语义
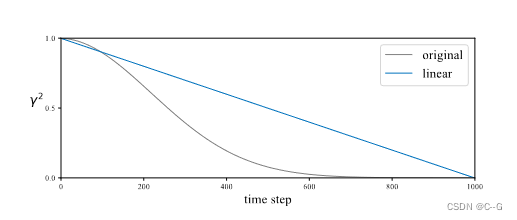
采用线性衰减噪声噪声
实验结果

结论:自监督学习绩效与生成质量无关
Tokenizer
更换Tokenizer,分别为Convolutional VAE、Patch-wise VAE、Patch-wise AE和Patch-wise PCA

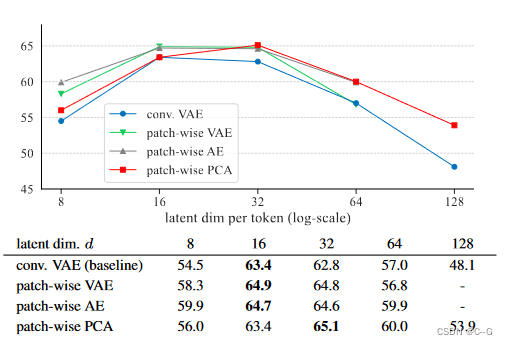
结论:标记器的潜在维数是DDM在自监督学习中发挥作用的关键
卷积VAE标记器既不是必要的,也不是有利的;相反,所有基于补丁的标记器,其中每个补丁都是独立编码的,彼此之间的表现相似,并且始终优于Conv VAE变体。此外,KL正则化项是不必要的,因为AE和PCA变体都能很好地工作
结论:高分辨率、基于像素的ddm不如自监督学习。
Autoencoders
不同与DDM预测噪声,经典DAE直接预测清晰图像
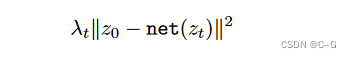
λ t = γ t 2 / σ t 2 \lambda_t =\gamma^2_t / \sigma^2_t λt=γt2/σt2,实验设置 λ t = γ t 2 \lambda_t=\gamma^2_t λt=γt2效果更好
去掉输入缩放
设置 γ t = 1 \gamma_t=1 γt=1, σ t \sigma_t σt是0到 2 \sqrt{2} 2的线性变化, λ t = 1 / ( 1 + σ t 2 ) \lambda_t=1/(1+\sigma^2_t) λt=1/(1+σt2)

结论:不需要按 γ t \gamma_t γt缩放数据3
用逆PCA对图像空间进行操作
通过主成分基(即V)将输入图像投影到隐空间中,在隐空间中加入噪声,并通过逆主成分基将带噪声的隐投影回图像空间,将这个有噪声的图像作为网络的输入,可以应用一个标准的ViT网络,它直接对图像进行操作,就好像没有tokenizer一样
结论:用逆主成分分析对图像空间进行处理可以获得与对潜在空间进行处理相似的结果
预测原始图像(l-DAE)
PCA对于任何降维d都是有损编码器
当让网络预测原始图像时,引入的“噪声”包括两部分:(i)加性高斯噪声,其固有维数为d; (ii) PCA重构误差,其固有维数为D - d (d为768)
使用干净的原始图像 x 0 x_0 x0和网络预测网( x t x_t xt),可以计算投影到完整PCA空间上的残差 r ≜ V ( x 0 − n e t ( x t ) ) r \triangleq V(x_0-net(x_t)) r≜V(x0−net(xt)),V是表示完整PCA基的D乘D矩阵
损失函数为:
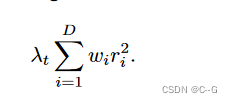
i 表示向量 r 的第 i 维,当 i≤d 时,每维权重 w i w_i wi 为1,当d < i≤d时,每维权重 w i w_i wi 为0.1, w i w_i wi 降低了PCA重构误差损失的权重

单层噪声
设置 σ = 1 / 3 \sigma=\sqrt{1/3} σ=1/3,指标下降为61.5%下降了三个点
结论:
使用多级噪声类似于DAE中的一种数据增强形式:它是有益的,但不是促成因素
DDM的表示能力主要是通过去噪驱动过程获得的,而不是扩散驱动过程
总结
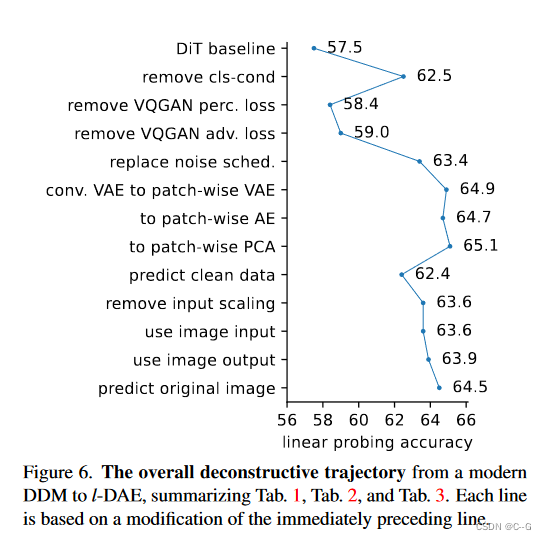

可视化可以帮助更好地理解l-DAE如何学习良好的表示
l-DAE,它在很大程度上类似于经典DAE,可以在自监督学习中表现得很有竞争力。关键分量是加有噪声的低维潜在空间。