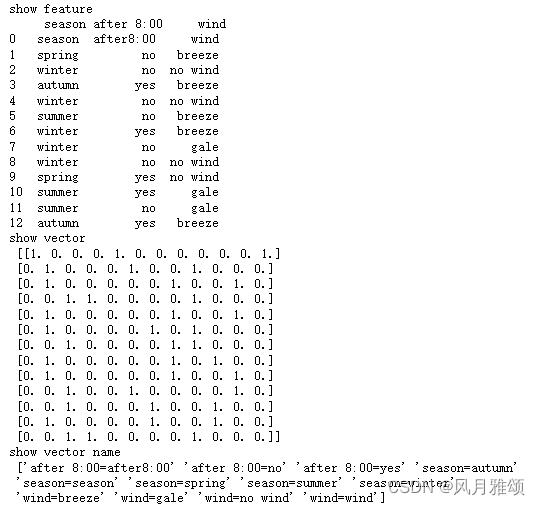
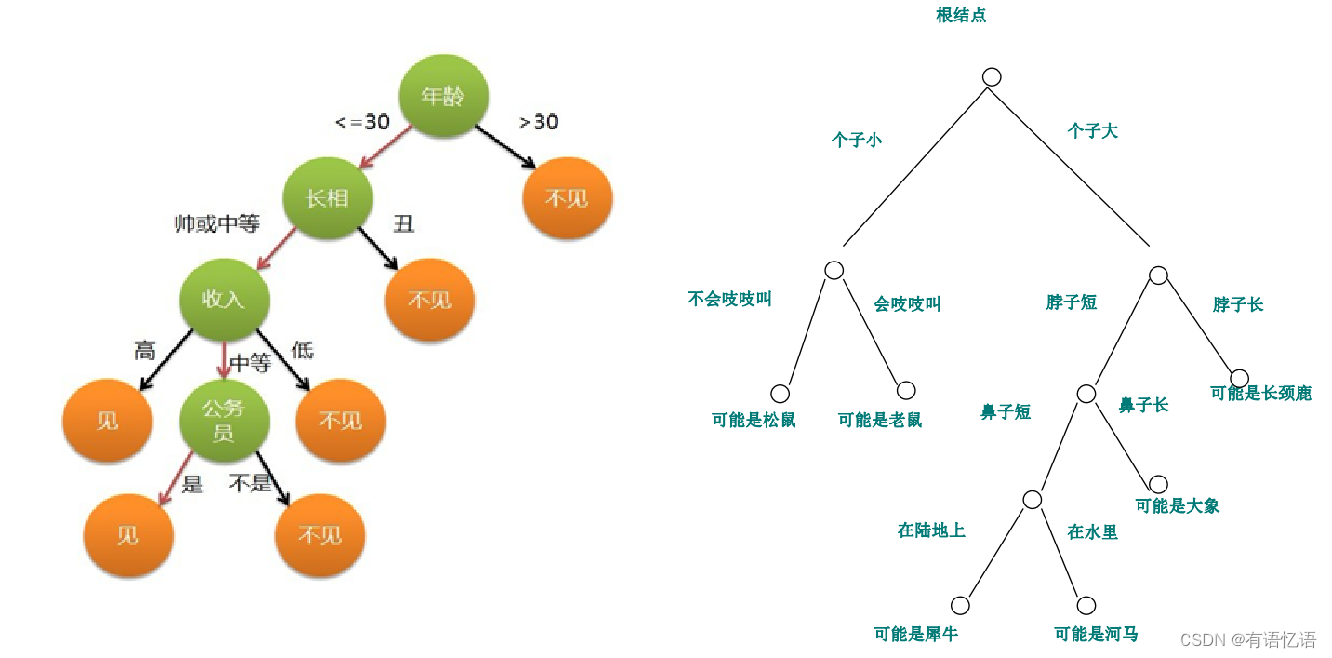
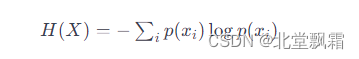观前提示:这是本人机器学习决策树内容的第三篇博客,沿用了之前相关的代码,包括信息增益计算函数、结点类、预测函数和分类精度计算函数
完整代码指路
DrawPixel/decisionTree.ipynb at main · ndsoi/DrawPixel (github.com)
前两篇博客详见“机器学习”专栏
使用方法:
方法一:一口气连接——执行是不会报错的
方法二:针对本节内容的代码块
notebook中我做了目录划分
与本节内容相关的代码块如下图:
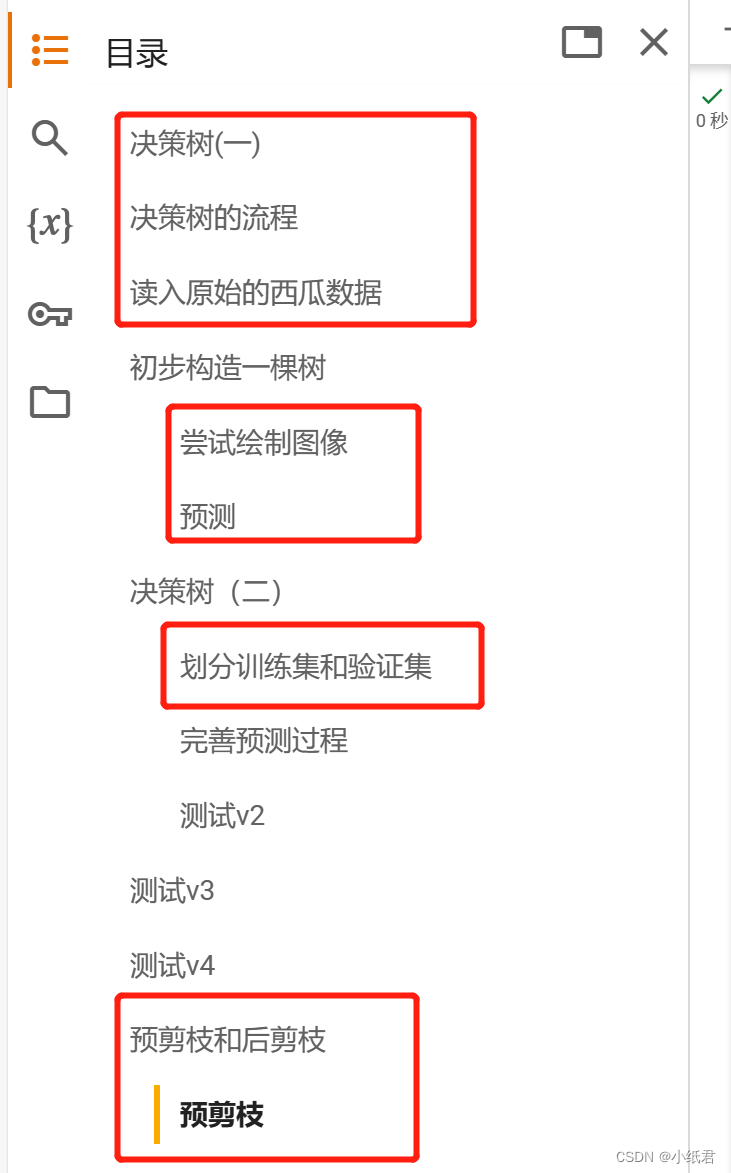
本节没有用到的是 dotree函数和TreeGenerate函数,所以预剪枝的主要是替换了TreeGenerate的逻辑
1、含义
预剪枝:
剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点
作用:提高构建决策树的效率、防止过拟合、提高模型的鲁棒性
2、实现流程
算法流程:
- 划分好训练集和验证集;
- 初始化根节点,标记为叶结点,用验证集计算精度,对当然结点进行划分,再用验证集计算精度,如果精度提升,则对当前结点进行划分,若精度无提升则不划分。
用一个队列(名为waitcheck)维护要考虑划分的结点。
step1:初始化根结点,将根结点投入到waitcheck中;
step2:从waitcheck中取出一个结点:
①当前结点是一个叶结点,计算验证集的分类精度a
②考虑当前结点能否在划分:
若该结点可以划分,则找出它划分的最优属性,进行划分,再计算划分后的验证集预测效果b
比较a和b的大小:
如果b比a小,则不划分,将该结点标记为叶结点,继续考虑waitcheck
如果b比a大,则将该结点标记为非叶结点,新生成的子结点加入waitcheck
不行则考虑下一结点
step3:重复step2,直到waitcheck为空
3、编程实现
1、划分训练集和验证集
按照西瓜书的数据划分:

dataSet = [
# 1
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
# 2
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
# 3
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
# 4
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
# 5
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
# 6
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
# 7
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
# 8
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
# ----------------------------------------------------
# 9
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
# 10
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
# 11
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
# 12
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
# 13
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
# 14
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
# 15
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
# 16
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
# 17
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
]
Attr = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
# 硬编码类别
class_dict = {'坏瓜':0,'好瓜':1}
# 将数据合并格式
D = []
for i in range(len(dataSet)):
d = {}
for j in range(len(Attr)):
d[Attr[j]] = dataSet[i][j]
d['Class'] = class_dict[dataSet[i][-1]]
D.append(d)
print(D)2、批量验证函数
# 精度计算
def calAccuracy(pred,data):
n = len(data)
re = 0
for i in range(n):
if pred[i] == data[i]['Class']:
re+=1
return re/n
# 返回预测结果和精度
def predict_v4(root_4,val_data):
re = []
for i in range(len(val_data)):
re.append(predict_v2(val_data[i],root_v4))
return re,calAccuracy(re,val_data)
3、结点是否能继续划分
# 若是否有划分的资格
def CanDivide(node_v4):
if node_v4.isSameClass() == True:
return False,[]
boolre,Attr = node_v4.isNoAttr()
if boolre == False:
return True,Attr
return False,[]4、初始数据集生成根结点、初始化waitcheck
import queue
# 找出初始数据集的最多类
max,cal_class = calMaxClass(train_data,class_num)
# 构造训练集的根结点
root_v4 = Node(train_data,Attr,max,cal_class,class_num)
# 标记根结点位叶结点
root_v4.label = 1
# 初始化waitcheck队列
waitcheck = queue.Queue()
waitcheck.put(root_v4)5、预剪枝过程(核心)
def train_v4(waitcheck,root_v4):
node_v4 = waitcheck.get()
# 用验证集算一下精度
res_o,acc_o = predict_v4(root_v4,val_data)
divide,Attr_Div = CanDivide(node_v4)
if divide == False:
# 考虑下一个结点
print("考虑下一个结点")
return
else:
# 先将当前结点的label改为0
node_v4.label = 0
# 尝试划分结点
# 选取最优属性
attr,info = node_v4.bestAttr()
# 获取划分好的数据集
SubDataSets = info[attr]['Dv']
SubInfo = info[attr]['Dv_info']
# 生成子node
# 保持子node
savesubnode = []
Attr = copy.deepcopy(Attr_Div)
Attr.remove(attr)
st = 0
for value,subds in SubDataSets.items():
# 因为假设是离散属性,所以新的self.attr必然要去掉已经选出的attr
subnodeAttr = copy.deepcopy(Attr)
# 获取已经算好的Dv的max和cal_class
submax = SubInfo[st][0]
subcal_class = SubInfo[st][1]
st+=1
# 生成新结点
subnode = Node(subds,subnodeAttr,submax,subcal_class,class_num)
subnode.setflag(attr)
# 假设新结点都是叶子结点
subnode.label = 1
# 暂存取得的新结点,若确定要划分,才加入讨论队列
savesubnode.append(subnode)
# 父结点记录子结点的指引
node_v4.addsubDs(subnode,value)
# 验证集评估
res_d,acc_d = predict_v4(node_v4,val_data)
print(f"未划分时的分类精度:{acc_o},划分后的分类精度:{acc_d}")
print(f"展示一下划分后的树")
drawTree(root_v4)
if acc_d>acc_o:
# 划分后的精度更高,所以划分
# 将新的子结点加入waitcheck
for i in savesubnode:
# i.label = 0 不用改,取出来还要再令label=1
waitcheck.put(i)
else:
# 划分后验证集的预测结果
print("划分后验证集预测结果")
print(res_d)
# 最终还是不划分
node_v4.label = 16、训练
while waitcheck.empty()==False:
train_v4(waitcheck,root_v4)
drawTree(root_v4)4、结果显示
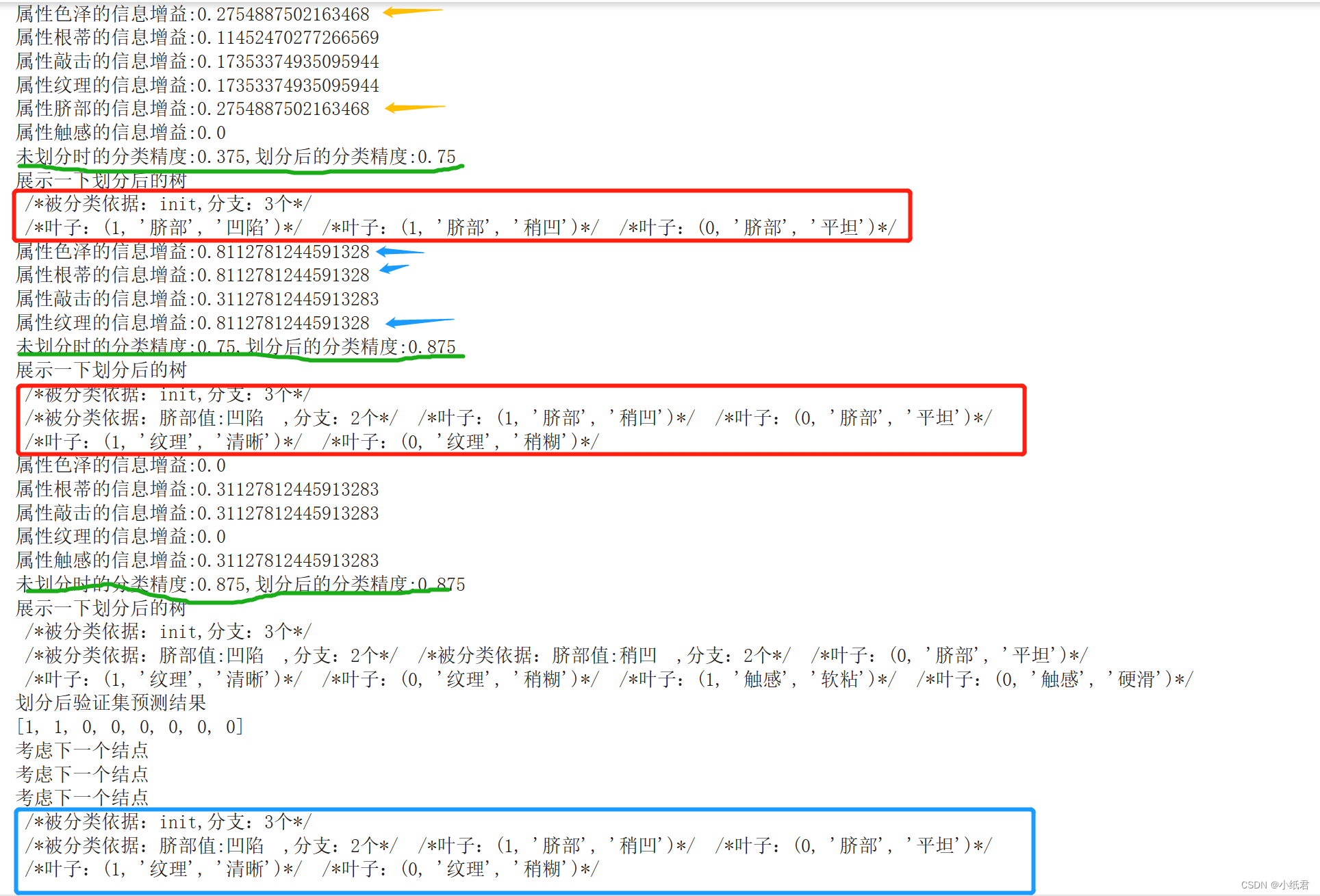
1)对原始数据集考虑划分:可以看到在计算机计算精度内,色泽和脐部属性的信息增益是一样的,但遍历的时候脐部在后,而要求是大于等于最大信息增益的属性就可以替换为最优,所以初次划分的最优属性是脐部
2)按照脐部划分后,验证集评估模型发现划分后的分类精度是0.75,划分前的精度是0.375,所以不剪枝,将新增的子结点加入waitcheck
3)继续考虑新的结点,按照添加顺序应该是“脐部=凹陷”的数据集,该数据集的最优属性划分(看蓝色箭头),在计算机精度内后来者居上最优的属性是“纹理”,然后看下方绿色线,发现按照“纹理”划分,精度又从0.75提升至0.875,因此又保留了“纹理”产生的分支
4)继续考虑waitcheck的数据,发现这些结点再划分都不会使得模型在验证集的精度提升,于是决策树模型完全形成
最终的决策树是:
 5、讨论:
5、讨论:
这个预剪枝的结果与《机器学习》上的并不一致
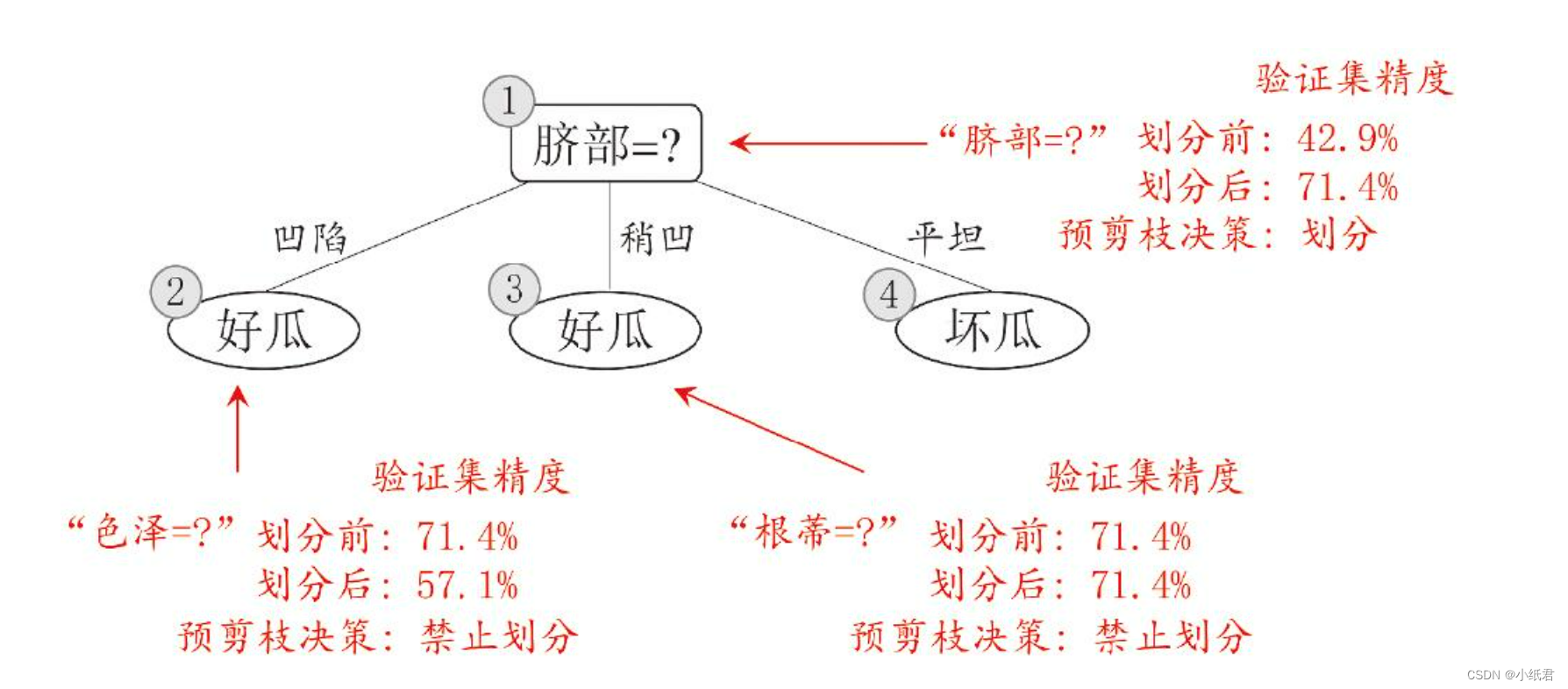
原因:就是在最优属性划分上:同样的信息增益,西瓜书的选择是“色泽”,我的程序选择的是“纹理”,当用验证集验证的时候,“色泽”划分会导致正确性下降,而纹理却能继续提升分类精度