文本搜索工具grep
作用
- grep是linux中一种强大的文件搜索过滤工具,可以按照正则表达式检索文件内容,并把匹配的结果显示到屏幕上(匹配的内容会标红)
格式
[root@server ~]
参数
| 参数 |
功能 |
| -i |
忽略大小写 |
| -c |
统计匹配的行数 |
| -v |
取反,不显示匹配的行 |
| -w |
匹配整个单词,精确匹配 |
| -E |
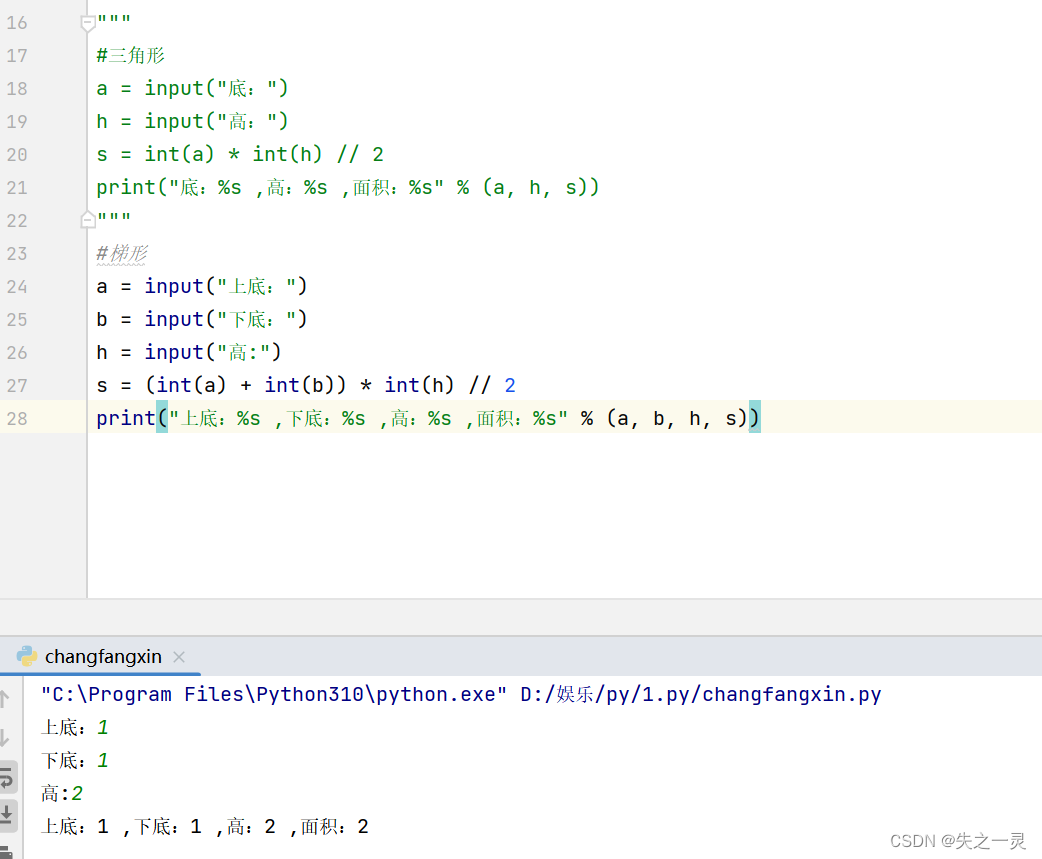
等价于egrep,即启用扩展正则表达式 |
| -n |
显示行号 |
| -rl |
将指定目录内的文件打印 |
| -A数字 |
匹配行及以下n行 |
| -C数字 |
匹配行及上下n行 |
| -B数字 |
匹配行及以上n行 |
| -q |
静默模式,没有任何内容输出,使用$?来判断是否执行成功 |
| -o |
只显示匹配的内容 |
注意
- 工作方式:grep可以在一个或多个文件中检索,如果条件中包含了空格,需要使用双引号引起
- 工作结果:如果搜索成功则返回0状态码,否则为1状态码
示例
- 操作对象文件:/etc/passwd
- 作用:记录账户的信息,共分为7段,使用冒号分割
- 意义:账户名:密码代号x:UID:GID:注释:家目录:登录的Shell
- 注意:最后一段/sbin/nologin表述不允许登录
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
12
[root@server ~]
12
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
正则表达式
概念
- 在进行程序设计的过程中,用户会不可避免地遇到处理某些文本的情况。有的时候,用户还需要查找符合某些比较复杂规则的字符串。对于这些情况,如果单纯依靠程序设计语言本身,则往往会使得用户通过复杂的代码来实现。但是,如果使用正则表达式,则会以非常简短的代码来完成
- 正则表达式是通过一些特殊字符的排列,用以查找、替换、删除一行或多行文字字符串,简单的说,正则表达式就是用在字符串的处理上面的一项表示式。由于正则表达式语法简练,功能强大,得到了许多程序设计语言的支持,包括Java、C++、Perl以及Shell等
基本正则表达式
- 基本正则表达式(Basic Regular Expression,BRE),又称为标准正则表达式,是最早制订的正则表达式规范,仅支持最基本的元字符集。基本正则表达式是POSIX规范制订的两种正则表达式语法标准之一,另外一种语法标准称为扩展正则表达式
常见元字符
| 元字符 |
说明 |
| ^ |
以某个字符开头或行首 |
| $ |
以某个字符结尾或结尾 |
| . |
匹配任意字符 |
| * |
对前一项进行0次或多次重复匹配 |
| {m,n} |
将前一项字符重复m-n次,{m,}{,n}{m,n} |
| [] |
对方括号内的单字符进行匹配 |
| [^] |
对方括号内的范围取反 |
|
匹配以某个字符开头的行 |
| () |
定义一个子表达式 |
| 词首【\<或\b】和词尾锚定【\>或者\b】 |
其后面的任意字符必须作为单词首部出现;其前面的任意字符必须作为单词尾部出现 |
| \ |
转义字符,让一些特殊符号失效 |
posix字符类
- POSIX字符类是一个形如
[:...:]的特殊元序列(meta sequence),他可以用于匹配特定的字符范围
| 正则表达式 |
描述 |
示例 |
| [:alnum:] |
匹配任意一个字母或数字字符 |
[[:alnum:]]+ |
| [:alpha:] |
匹配任意一个字母字符(包括大小写字母) |
[[:alpha:]] |
| [:blank:] |
空格与制表符(横向和纵向) |
[[:blank:]]* |
| [:digit:] |
匹配任意一个数字字符 |
[[:digit:]]? |
| [:lower:] |
匹配小写字母 |
[[:lower:]] |
| [:upper:] |
匹配大写字母 |
([[:upper:]]+)? |
| [:punct:] |
匹配标点符号 |
[[:punct:]] |
| [:space:] |
匹配一个包括换行符、回车等在内的所有空白符 |
[[:space:]]+ |
| [:graph:] |
匹配任何一个可以看得见的且可以打印的字符 |
[[:graph:]] |
| [:xdigit:] |
任何一个十六进制数(即:0-9,a-f,A-F) |
[[:xdigit:]]+ |
| [:cntrl:] |
任何一个控制字符(ASCII字符集中的前32个字符) |
[[:cntrl:]] |
| [:print:] |
任何一个可以打印的字符 |
[[:print:]] |
示例
- [ab] : 检索包含a或者b的行信息,[]只能包含一个内容
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
- [-]:表示范围,如:[0-9] [a-z] [A-Z] [a-zA-Z]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
扩展正则表达式
概念
- 扩展正则表达式(Extended Regular Expression,ERE)支持比基本正则表达式更多的元字符,但是扩展正则表达式对有些基本正则表达式所支持的元字符并不支持。前面介绍的元字符“^”、“$”、“.”、“*”、“[]”以及“[^]”这6个元字符在扩展正则表达式都得到了支持,并且其意义和用法都完全相同,不再重复介绍。接下来重点介绍一下在扩展正则表达式中新增加的一些元字符。
元字符
| 元字符 |
说明 |
| ? |
将前一项字符进行0次或者1次的重复匹配 |
| + |
将前一项进行1次或者多次的重复匹配 |
| (|) |
匹配|符号左边或者右边的字符,整体精确匹配 |
示例
[root@server ~]
[root@server ~]
[root@server ~]
三种支持扩展正则的方法
[root@server ~]
[root@server ~]
[root@server ~]
注意:grep不支持扩展正则(? + (|)),要想生效,可以使用上述三种方法
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]
[root@server ~]