目录

二叉树的遍历
概念介绍
二叉树的遍历分为
- 前序 —— 根 左子树 右子树
- 中序 —— 左子树 根 右子树
- 后序 —— 右子树 左子树 根
- 层序 —— 一层一层往下遍历
我们在看二叉树时应该这样看:
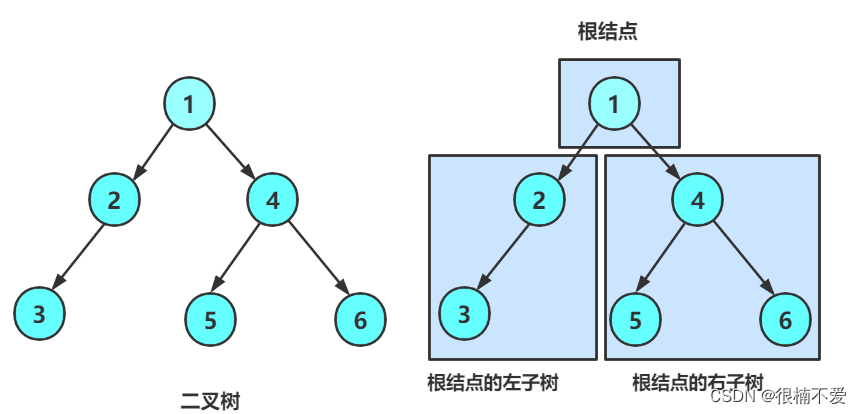
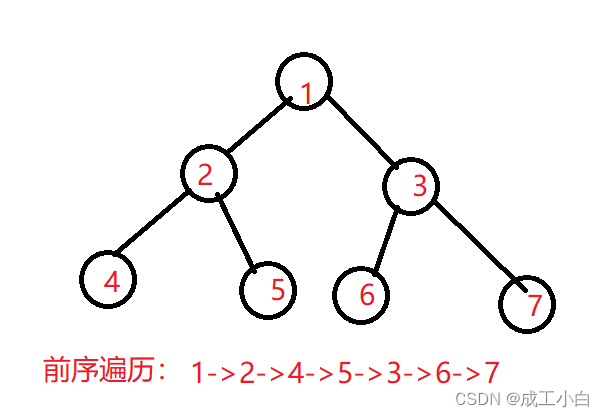
如下这是一棵二叉树

最上面的节点是根,下面是两大棵树,左节点以下的是左子树,右边的则是右子树
接下来假设我们先遍历左,那么我们就该这么看:

这一个整个左子树里面接着分成——根、左子树、右子树
再往下分:
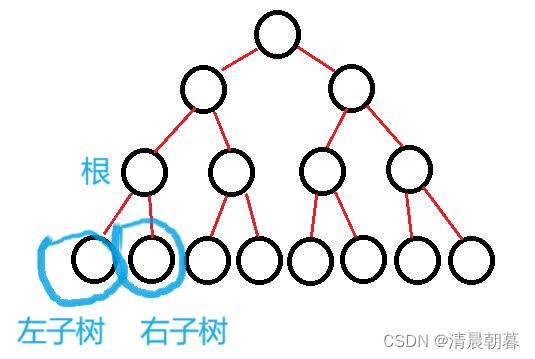
根、左子树、右子树
如果还要再往下分的话,左子树和右子树都为空,如果遍历二叉树的话,到这里就该结束了
前序遍历递归实现 PreOrder
通常在遍历二叉树的时候,都会采用递归遍历
这里我们以 前序遍历 为例
前序遍历,就是遍历 根 -> 左子树 -> 右子树 ,然后现在我们需要遍历一下如下这棵树:
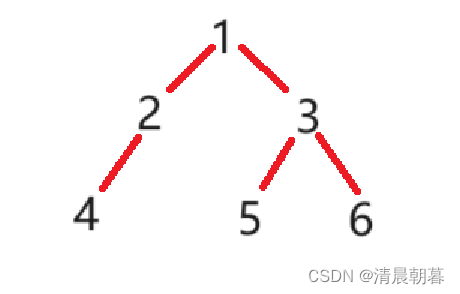
我们先遍历根,现在根是 1,就先找到 1。然后左子树,但是左子树不是单一一个节点,所以我们需要将左子树当成一棵完整的树,再来遍历一遍 根、左子树、右子树:

先找根,所以在 1 之后,第二个找到的是 2
沿着这个思路继续,2 之后是 4,4 的左右为空,我们就用 N 来代替 ——> 以 4 为根的树找到的就是 4、N、N。目前找到的是 1、2、4、N、N
接下来递归回去:以 4 为根的左子树找完了,就意味着 2 的左子树找完了,接下来就是 2 的右子树,为空,记为 N
2 的找完了。就意味着 1 的左子树找完了,接下来就是找 1 的右子树,但右子树也不止一个节点,所以还是按上述操作,再次执行一遍:
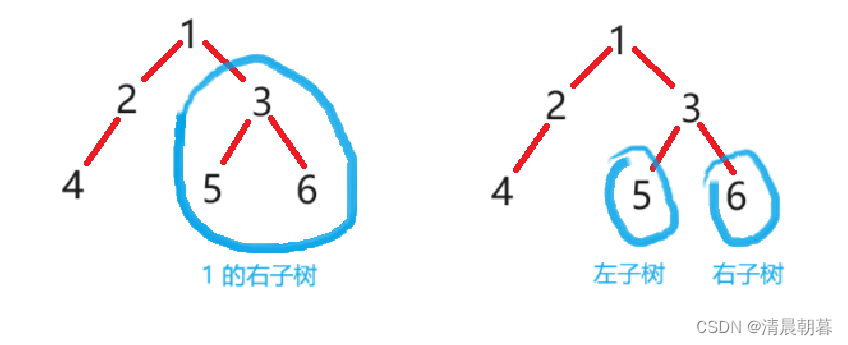
如上,因为还是前序遍历,所以我们还是按 根、左子树、右子树 的顺序,先找到 3,随后是 5、N、N、6、N、N
综上,这一整棵树前序遍历的结果就是:
1、2、4、N、N、N、3、5、N、N、6、N、N
但如果要递归实现的话,我们就需要考虑一下:递归条件是什么?
递归,简单点说就是将大问题拆分成小问题,小问题再拆分成小问题,当不满足某个条件或满足某个条件时,递归就要往回走了
这里我们的条件是:当遍历到空节点,就是最下面了的时候,停止遍历
然后打印当前节点(根)所带的值(这里我们以前序为例),然后再调用一次函数,将根节点的左孩子节点放入函数中,接着是右孩子节点
代码如下:
//前序遍历
void PreOrder(TN* root)
{
if (root == NULL)
{
printf("N ");
return;
}
printf("%d ", root->val);
PreOrder(root->left);
PreOrder(root->right);
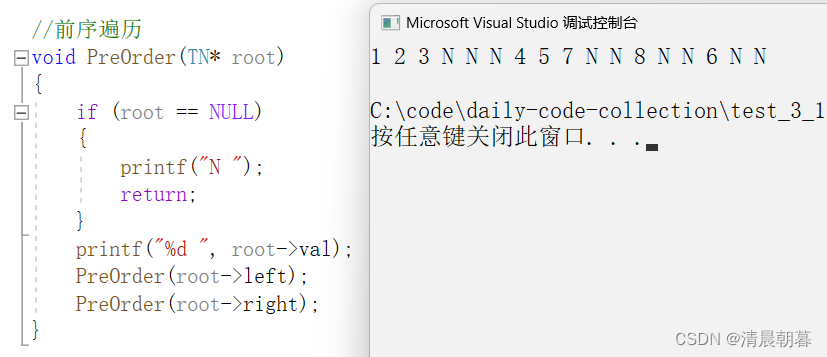
}我们来分析一下这个递归展开图
我们现在遍历这棵树:
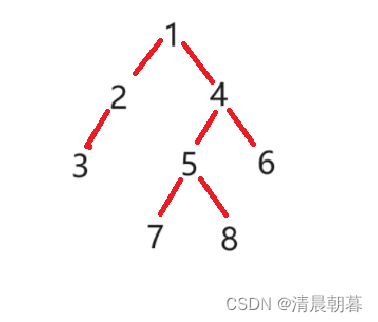
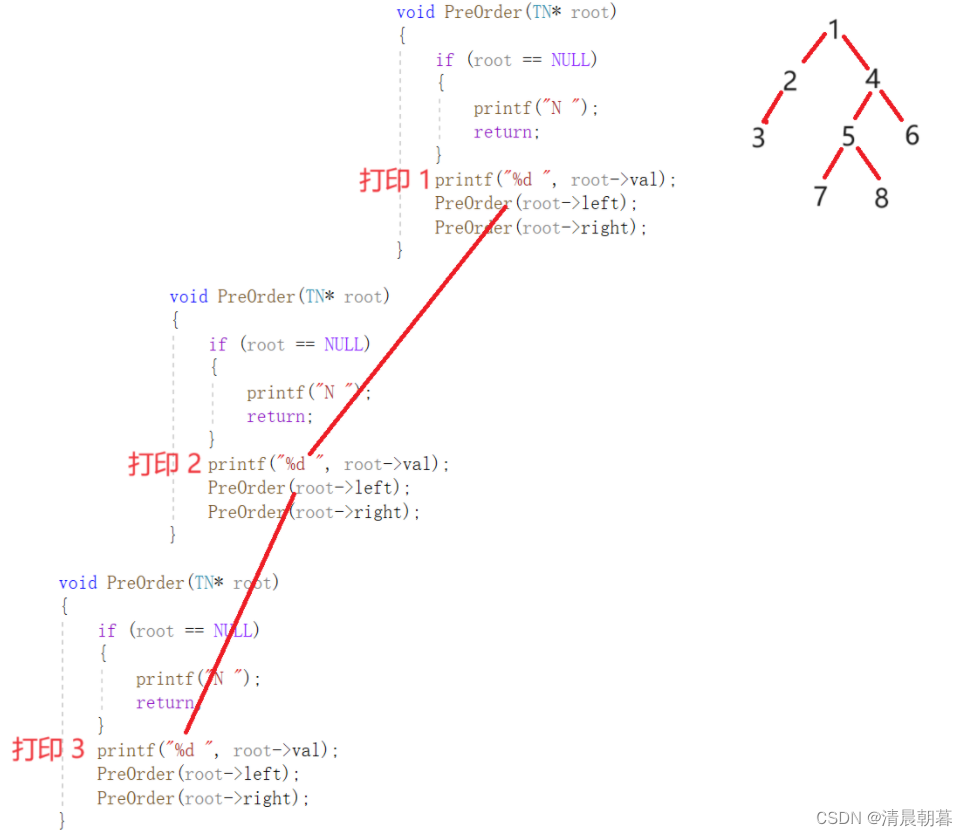
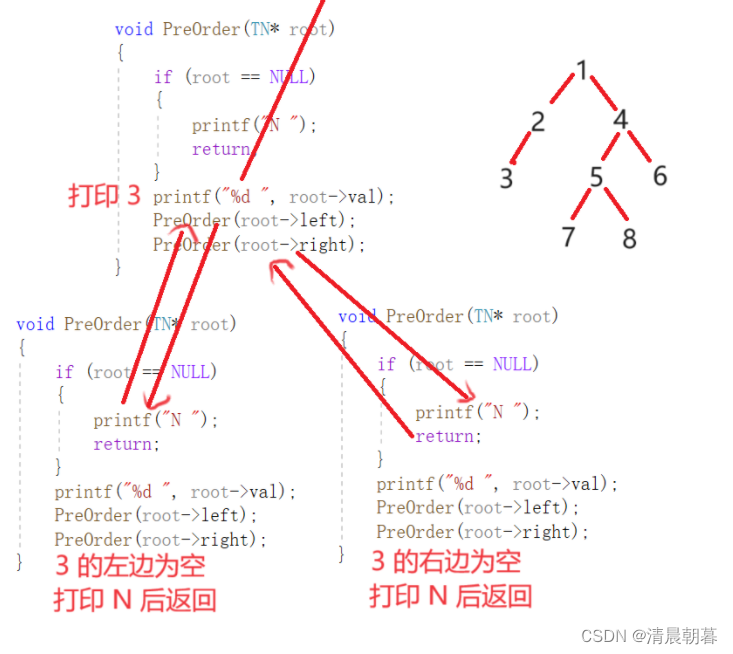
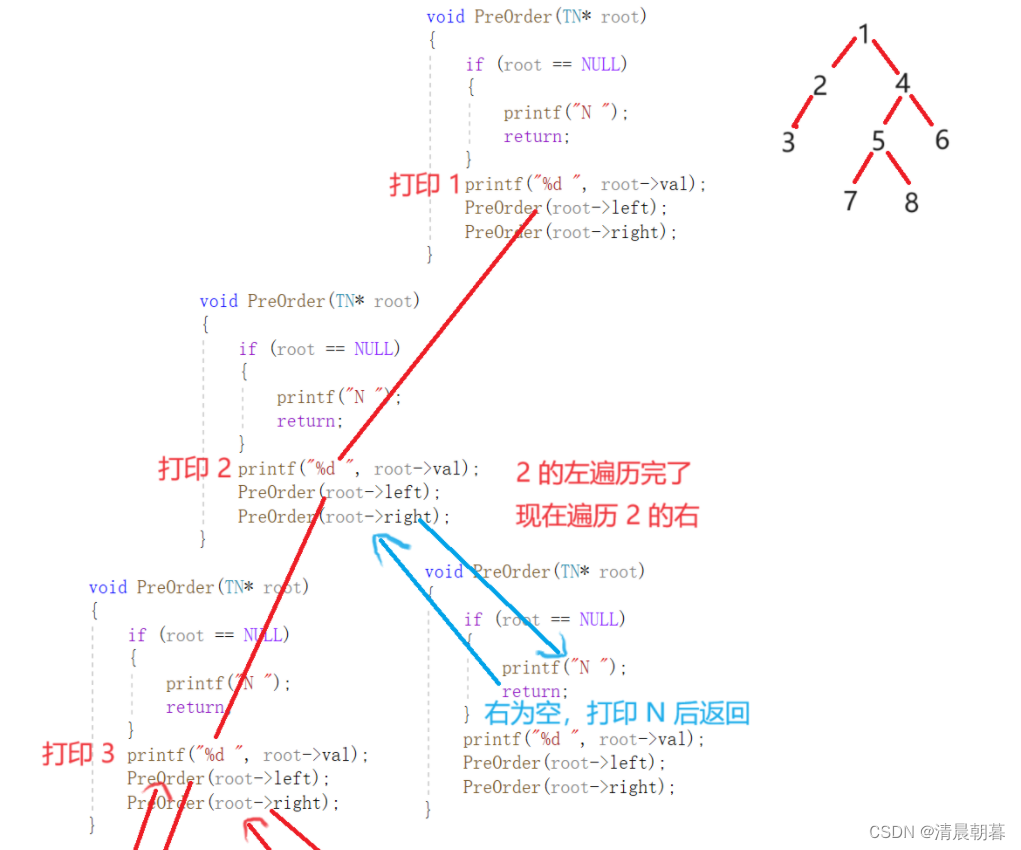

如上是这一段的递归示意图,最终的结果应该是:
1、2、3、N、N、N、4、5、7、N、N、8、N、N、6、N、N
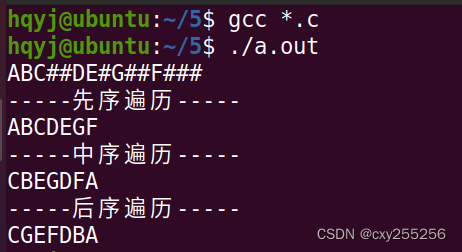
运行一下程序看结果:
中序遍历递归实现 InOrder
中序遍历就是遍历 左子树、根、右子树
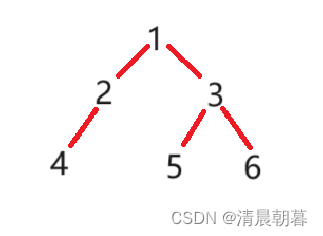
如果要中序遍历这棵树的话,那么结果就是:N、4、N、2、N、1、N、5、N、3、N、6、N
这里和前序最大的区别就是,先根还是先左子树,所以我们只需要将根的打印和寻找左子树的代码换个顺序,就实现了中序遍历
代码如下:
//中序遍历
void InOrder(TN* root)
{
if (root == NULL)
{
printf("N ");
return;
}
PreOrder(root->left);
printf("%d ", root->val);
PreOrder(root->right);
}后序遍历递归实现 PostOrder
后序遍历的逻辑和上述并无太大差别,这里就直接给代码了:
//后序遍历
void PostOrder(TN* root)
{
if (root == NULL)
{
printf("N ");
return;
}
PreOrder(root->left);
PreOrder(root->right);
printf("%d ", root->val);
}二叉树节点总个数 TreeSize
我们如果要计算总个数的话,就相当于是 左子树内的所有节点个数 + 右子树内的所有节点 + 1(当前节点)
当我们当前节点为空时,就返回 0
代码如下:
//节点个数
int TreeSize(TN* root)
{
return root == NULL ? 0 :
TreeSize(root->left) + TreeSize(root->right) + 1;
//上述代码是放一行的,这里放两行只是因为太长了,并无错误
}我们来递归展开一下该代码:
节点 1 的左边

节点 1 的右边

综上,我们得出的结果就是 6,答案正确
二叉树的高度 TreeHight
二叉树的高度,实际上就是这个二叉树最大有几层

如上这棵二叉树的高度就是 3
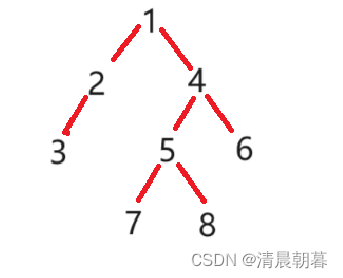
这棵二叉树的高度就是 4
那我们该怎么找到这个高度呢?
试想一下:一个学校的校长想了解两个专业里面哪个学生最高,他应该问一问两个院长对吧,院长会去问主任,主任问辅导员,辅导员问班长
班长对比完之后上报,辅导员、主任和院长也是,校长比了一下两个院长给上来的数据之后,对比了一下,得出了哪个学生最高
如上,我们如果要知道二叉树的高度,我们是不是应该比对一下:左子树和右子树哪边更高?
左子树又分下去,右子树也是,不断将大问题转换成小问题,最后结束的条件就是:找到空了,返回 0
如果不返回 0 的话(中间节点),我们就使用三目操作符,得出左右子树中高的那一个 return 回去
由于我们这里要返回整数(int),所以我们在递归使用函数的时候,需要拿一个整形变量来接收,最后整形变量来参与三目操作符的比较
代码如下:
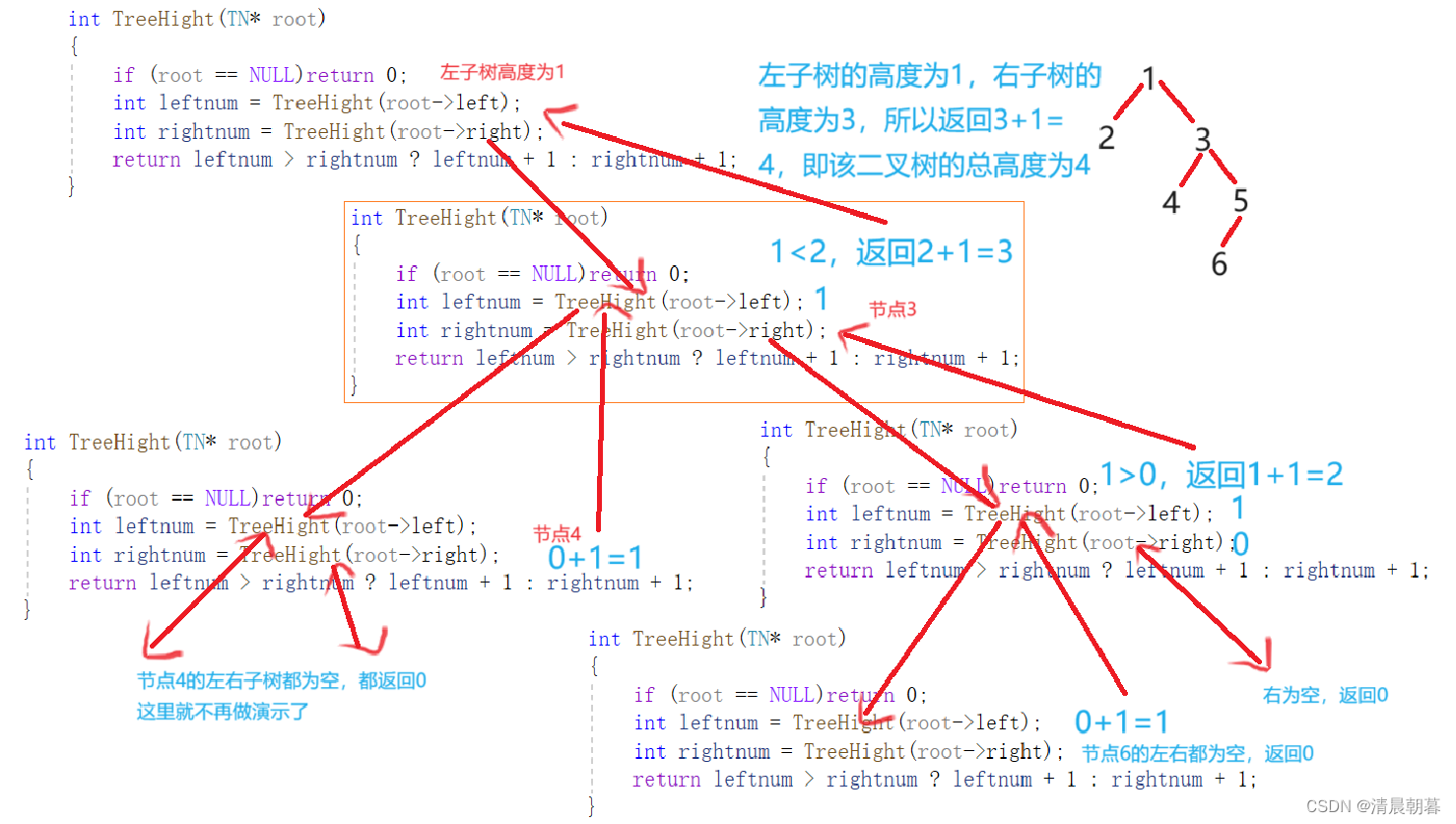
//树的高度
int TreeHight(TN* root)
{
if (root == NULL)return 0;
int leftnum = TreeHight(root->left);
int rightnum = TreeHight(root->right);
return leftnum > rightnum ? leftnum + 1 : rightnum + 1;
}我们来分析一下这个代码的递归展开图(以下图的二叉树为例)


二叉树第K层的节点个数 TreeKLevel
如果我们要知道第K层有多少个节点的话,我们就需要有一个变量能控制递归,即:当到了第K层的时候,递归就应该结束并返回 1 了
另外,如果在遍历的途中,碰到节点为空的情况,就直接 return 0
要递归,我们需要将大问题分解成一个个的小问题:
假设我们的问题是:第 3 层的节点有多少个
那么对第一层来说,第三层是第下下层
对第二层来说,第三层是下一层
对第三层来说,就是这一层
所以我们可以在函数递归的时候,将 K-1 传过去,而当 K 等于 1 时,就代表是这一层节点,return 1 即可
代码如下:
//第K层的节点数
int TreeKLevel(TN* root, int k)
{
if (root == NULL)return 0;
if (k == 1)return 1;
return TreeKLevel(root->left, k - 1) + TreeKLevel(root->right, k - 1);
}我们来递归展开一下(遇到空的情况就直接简写了):

二叉树的节点查找 TreeFind
我们如果要查找一个节点的话,比如我要找数节点内放着 3 的节点,如果找到了,那我就返回这个节点的地址,如果找到空指针了(找到空指针就意味着前面的节点都找过了,没有符合条件的节点),就返回 NULL
但是我们的递归是有返回值的,所以我们递归的时候需要有变量接收
这时,接收的变量只会有两个结果,要么是找到了,返回的是那个节点的指针;要么是没找到,返回的是 NULL
所以我们在判断完之后,还是需要将值传回去的,如果传过来的值不为空,就 return 回去,如果为空,就 return NULL
代码如下:
TN* TreeFind(TN* root, int x)
{
if (root == NULL)return NULL;
if (root->val == x)return root;
TN* NodeLeft = TreeFind(root->left, x);
if (NodeLeft)return NodeLeft;
TN* NodeRight = TreeFind(root->right, x);
if (NodeRight)return NodeRight;
return NULL;
}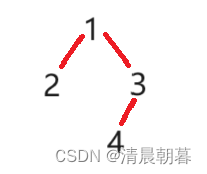
假如我们现在要在这样一棵树里面找到 4 这个节点,我们来递归展开分析一下:

二叉树的叶子节点个数 BinaryTreeLeafSize
这里的主要思想是:如果当前节点为空,返回 0
如果该节点的左子树和右子树同时为空,则返回 1
由于这个函数需要返回数据,所以我们需要拿变量来接收,最后返回的是两个变量之和
递归就是将大问题转换成小问题:我们的叶子节点,就是左子树的叶子节点+右子树的叶子节点
代码如下:
int BinaryTreeLeafSize(TN* root)
{
if (root == NULL)return 0;
if (root->left == NULL && root->right == NULL)return 1;
int a1 = BinaryTreeLeafSize(root->left);
int a2 = BinaryTreeLeafSize(root->right);
return a1 + a2;
}该函数就不画递归展开图了,前面的递归展开图理解了的话,再来看这个会有不一样的感受
或者可以尝试画简图,如下:

手撕一棵树,检测代码
TN* BuyBTNode(int val)
{
TN* newnode = (TN*)malloc(sizeof(TN));
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
newnode->val = val;
newnode->left = NULL;
newnode->right = NULL;
return newnode;
}
// 手搓一棵树
TN* CreateTree()
{
TN* n1 = BuyBTNode(1);
TN* n2 = BuyBTNode(2);
TN* n3 = BuyBTNode(3);
TN* n4 = BuyBTNode(4);
TN* n5 = BuyBTNode(5);
TN* n6 = BuyBTNode(6);
TN* n7 = BuyBTNode(7);
TN* n8 = BuyBTNode(8);
n1->left = n2;
n1->right = n4;
n2->left = n3;
n4->left = n5;
n4->right = n6;
n5->left = n7;
n5->right = n8;
return n1;
}
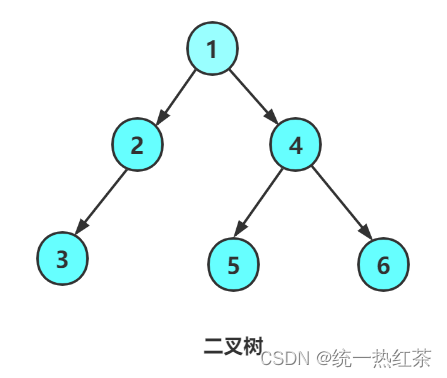
如上,我们粗暴地将一棵树给造了出来
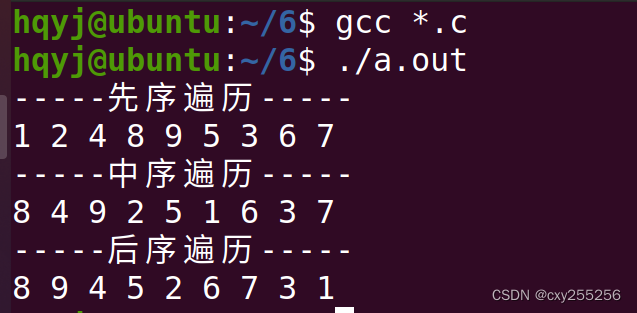
接下来我们将在 main 函数内将我们上述的代码都检测一遍
另,我们造出来的这棵树是长这样的:

int main()
{
TN* root = CreateTree();
PreOrder(root);
printf("\n");
printf("%d\n", TreeSize(root));
TN* tmp = TreeFind(root, 5);
printf("%d\n", tmp->val);
printf("%d\n", TreeKLevel(root, 3));
printf("%d\n", BinaryTreeLeafSize(root));
return 0;
}
总代码 & gitee
如果有需要今天所讲内容的代码的同学,可以点击下方链接
结语
这篇写完之后,估计就破万了
曾经跟你说过,如果你被风吹傻了的话,变成傻瓜了,那我也会把你带在身边
但是,你好像跑丢了,找不到了
跟你说过的,18篇之内会破万,算是完成了这个承诺
拜拜咯,记得照顾好自己
致一个坚强的、傻乐傻乐的女孩