每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

- I-JEPA:基于Yann LeCun愿景的首个更人性化AI模型
- 庆祝FAIR十周年:通过开放研究推动技术前沿的十年
- 图灵奖颁给了Yann LeCun、Geoffrey Hinton和Yoshua Bengio
今天,我们向大家公开发布视频联合嵌入预测架构(V-JEPA)模型,这是推进机器智能并加深对世界理解的关键一步。作为一个早期的物理世界模型示例,V-JEPA擅长检测和理解对象间的高度详细互动。遵循负责任的开放科学精神,我们决定以创意共享非商业许可发布此模型,供研究人员进一步探索。
作为人类,我们通过观察学习到关于周围世界的许多知识——尤其是在生命早期阶段。就像牛顿的第三运动定律:即使是婴儿(或猫)在多次推落桌上物品并观察结果后也能直观地理解,凡是上升的都必须下落。你不需要几小时的指导或阅读成千上万本书就能得出这个结果。你的内在世界模型——基于世界的心理模型的上下文理解——为你预测了这些后果,而且非常高效。
“V-JEPA是朝着更深入理解世界迈出的一步,以便机器能够实现更广泛的推理和规划,”Meta的副总裁兼首席AI科学家Yann LeCun说道,他在2022年提出了最初的联合嵌入预测架构(JEPA)。“我们的目标是构建高级机器智能,能像人类一样学习,形成对周围世界的内部模型,以便高效地学习、适应并制定计划以完成复杂任务。”
聚焦视频JEPA
V-JEPA是一个非生成模型,通过预测视频中缺失或遮蔽部分的抽象表示空间学习。这类似于我们的图像联合嵌入预测架构(I-JEPA)如何比较图像的抽象表示(而不是直接比较像素本身)。与试图填补每个缺失像素的生成方法不同,V-JEPA具有丢弃不可预测信息的灵活性,这导致训练和样本效率提高了1.5到6倍。
由于采用自监督学习方法,V-JEPA完全使用未标记数据进行预训练。标签仅用于预训练后将模型适配到特定任务。与之前的模型相比,这种架构在所需标记示例数量和学习即使是未标记数据所需的总体努力方面更为高效。通过V-JEPA,我们在这两方面都看到了效率提升。
我们通过遮蔽视频的大部分内容,仅向模型展示一小部分上下文。然后我们让预测器填补缺失的部分——不是以实际像素的形式,而是作为这个表示空间中的更抽象的描述。
V-JEPA通过预测学习到的潜在空间中遮蔽的时空区域来训练视觉编码器。
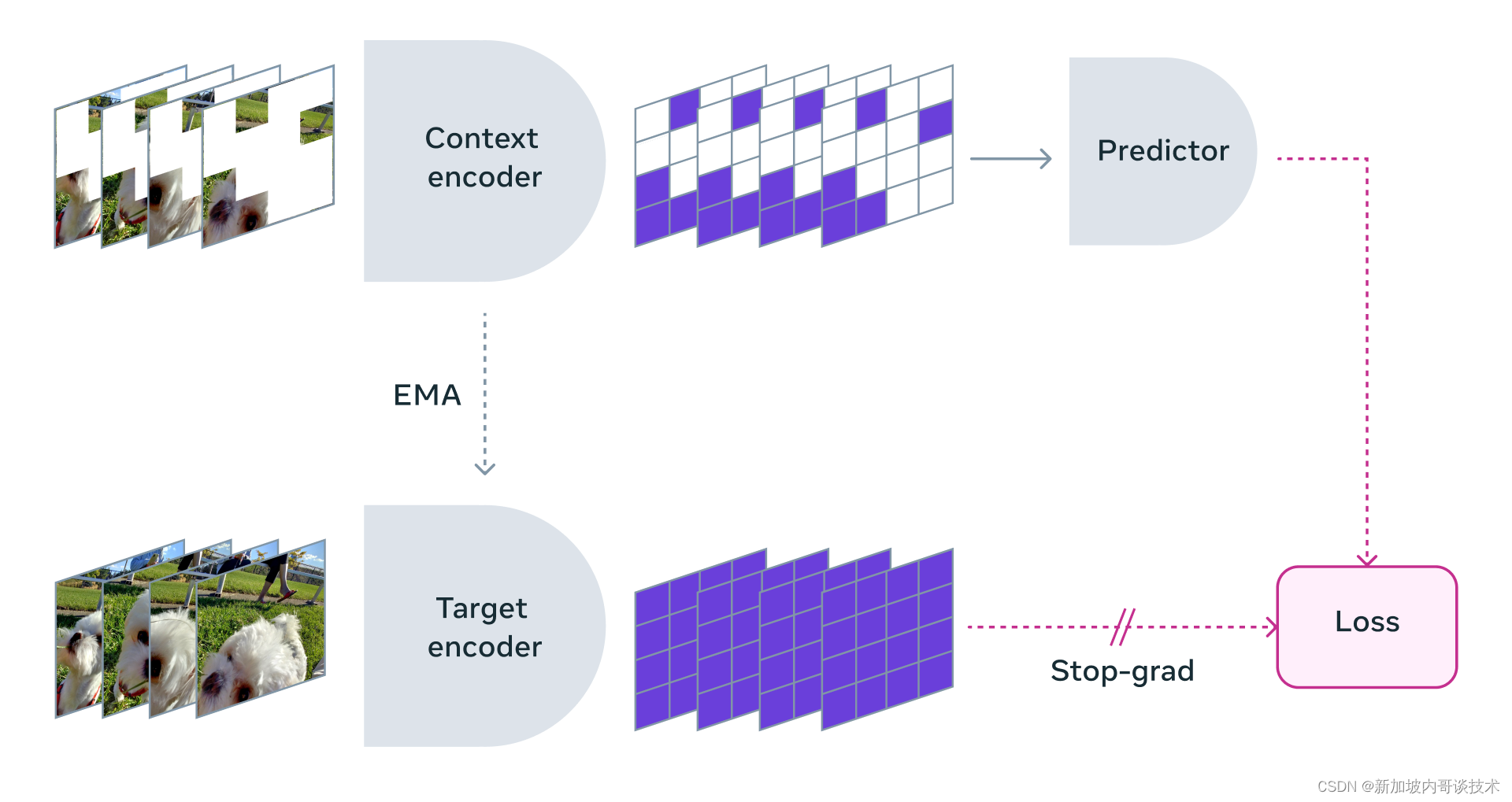
遮蔽方法论
V-JEPA的训练并不是为了理解一种特定类型的行动。相反,它使用自监督训练在一系列视频上学习,并了解了世界运作方式的许多方面。团队还仔细考虑了遮蔽策略——如果你不遮蔽视频的大部分区域,而是在这里那里随机采样补丁,这会使任务变得太简单,你的模型就不会学到世界上特别复杂的任何事情。
同样重要的是要注意,在大多数视频中,事物随时间缓慢演变。如果你遮蔽视频的一部分,但只在特定瞬间,并且模型可以看到紧接之前和/或之后的情况,这也会使事情变得太简单,模型几乎肯定不会学到任何有趣的东西。因此,团队采用了一种在空间和时间上都遮蔽视频部分的方法,这迫使模型学习并发展对场景的理解。
高效预测
在抽象表示空间进行这些预测很重要,因为它允许模型专注于视频包含的高级概念信息,而不必担心那些对下游任务通常不重要的细节。毕竟,如果视频显示了一棵树,你可能不会关心每片单独叶子的微小运动。
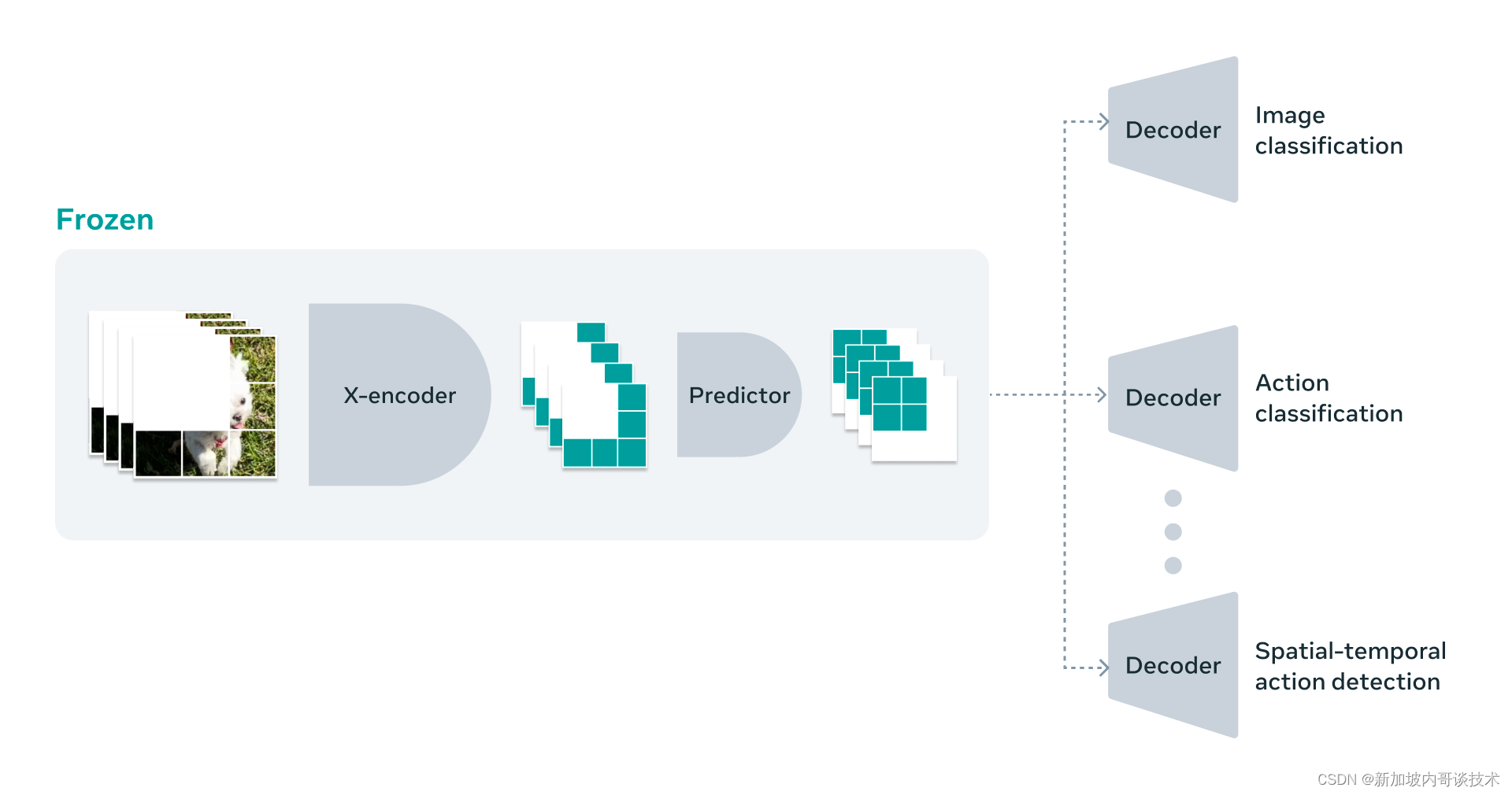
我们对这一方向感到兴奋的原因之一是,V-JEPA是第一个擅长“冻结评估”的视频模型,这意味着我们在编码器和预测器上完成了所有自监督预训练,然后我们不再触碰模型的这
些部分。当我们想要将它们适配学习新技能时,我们只需在其上训练一个小型轻量级的专门层或小网络,这非常高效且快速。
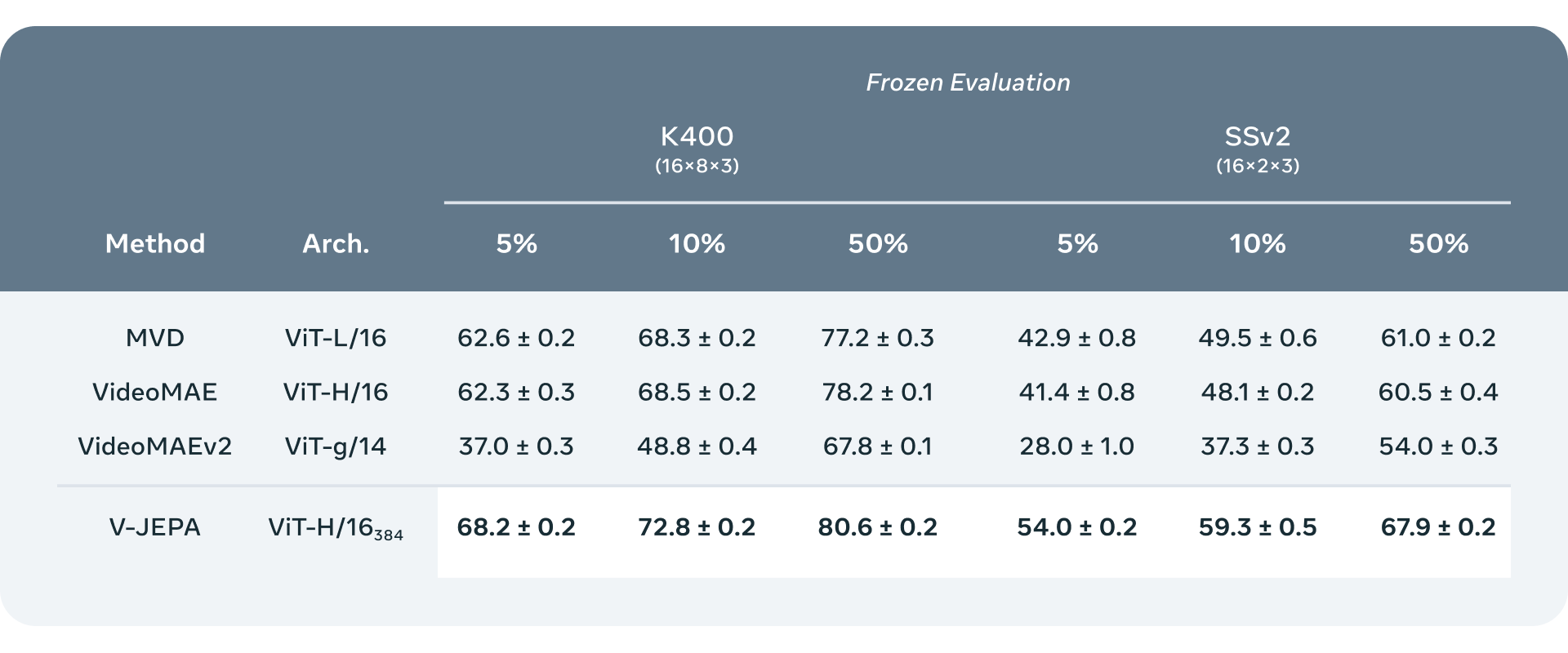
低样本冻结评估:将V-JEPA与其他视频模型在Kinetics-400和Something-Something-v2上的冻结评估进行比较,我们变化了每个数据集可用于训练注意力探针的标记示例百分比。我们在几个低样本设置中训练探针:使用训练集的5%、10%或50%,并在每个设置中进行三次随机分割,以获得更稳健的指标,每个模型进行九次不同的评估实验。我们报告了K400和SSv2官方验证集上的平均值和标准偏差。V-JEPA比其他模型更节省标签——具体来说,减少每个类别可用的标记示例数量会增加V-JEPA与基准之间的性能差距。
以前的工作需要进行完全的微调,这意味着在预训练模型之后,当你希望模型在进行微调以承担该任务时真正擅长细粒度动作识别时,你必须更新模型中的参数或权重。然后那个模型总体上变得擅长执行那个任务,而不再适用于其他任何事情。如果你想教模型一个不同的任务,你必须使用不同的数据,并且必须为这个其他任务专门定制整个模型。如我们在这项工作中所展示的,通过V-JEPA,我们可以一次性预训练模型而不需要任何标记数据,固定它,然后重用模型的同一部分来完成几个不同的任务,如动作分类、精细物体交互识别和活动定位。
V-JEPA是一种自监督方法,用于从视频中学习表示,可以应用于各种下游图像和视频任务,而无需调整模型参数。V-JEPA在冻结评估中的图像分类、动作分类和时空动作检测任务上优于之前的视频表示学习方法。
未来研究的途径...
虽然“V”在V-JEPA中代表“视频”,但到目前为止它只考虑了视频的视觉内容。下一步显然是采取更多模态方法,所以我们正在仔细考虑如何将音频与视觉结合起来。
作为概念验证,当前的V-JEPA模型擅长于细粒度物体交互和区分随时间发生的详细物体对物体交互。例如,如果模型需要能够区分放下笔、捡起笔和假装放下笔但实际上没有放下笔之间的区别,V-JEPA相比之前的方法在这种高级别动作识别任务上做得相当好。然而,这些事情在相对较短的时间尺度上工作。如果你向V-JEPA展示几秒钟到10秒钟的视频剪辑,它在那方面做得很好。因此,我们的另一个重要步骤是考虑规划和模型在更长时间范围内进行预测的能力。
...以及通往AMI的道路
到目前为止,我们与V-JEPA的工作主要关于感知——理解各种视频流的内容,以获得一些关于我们周围世界的上下文。这个联合嵌入预测架构中的预测器充当了一个早期的物理世界模型:你不必看到画面中发生的一切,它可以告诉你那里概念上发生了什么。作为下一步,我们想展示我们如何能够使用这种预测器或世界模型进行规划或序列决策。
我们知道,可以在没有强监督的情况下对JEPA模型进行视频数据训练,它们可以像婴儿那样观看视频——被动地观察世界,学习很多有趣的东西,了解这些视频的上下文,以这样一种方式,仅需少量标记数据,你就可以迅速获得一项新的任务和能力,识别不同的动作。
V-JEPA是一个研究模型,我们正在探索许多未来的应用。例如,我们预期V-JEPA提供的上下文对我们的具身AI工作以及我们构建未来AR眼镜的上下文AI助手的工作将是有用的。我们坚信负责任的开放科学的价值,这就是为什么我们以CC BY-NC许可发布V-JEPA模型,以便其他研究人员可以扩展这项工作。


































![冰岛人[天梯赛]](https://img-blog.csdnimg.cn/direct/65b5d9874f6e4f7ab1d985212a913d2e.png)