文章目录
论文: Study of 3D Finger Vein Biometrics on Imaging Device Design and Multi-view Verification
三维指静脉生物识别成像设备设计和多视图验证研究
总结
这是一个基于深度学习的指静脉识别方法。从任务类型上来说是分类任务。具体来说是多视角方法。
整体结构的组件来说,相比EIFNet,加入了Transformer编码器。思路上来说和多视角方法HCAN相似,将特征分为全局特征和局部特征两类,全局特征更多指视角间特征,局部特征更多指视角内特征。最后特征是两类特征的聚合。全局特征即将所有视角图片看作整体,研究其属性,比如视角间的关系。而局部特征是单张图片内的纹理等特征,选出评分最高的两个特征作为代表性的特征信息。然后和全局特征进行聚合。那么问题在于,整体特征包含局部特征,整体包含局部,那么为什么不会引起冗余?或许局部主导特征提取器更多承担了局部特征提取的任务,可以使得全局特征提取器相对更关注于视角间信息,又或者这种人为划分特征属性本身有些中途半端,不如在Transformer中完成整个流程。
问题
从直觉来说,如果网络能够很好的学习到整体信息,或者说从整体而来的信息,自然也能学习到例如选择更好视角的能力,那么为什么还需要下面的视角选择器来增强这部分特征?如果上面的全局特征提取器是CNN这种结构,能否学习到选择视角或者特征的能力呢?举例如果在不同类别中其中一个视角始终更适合,那么即使这些视角共用一个CNN参数,也会朝着利于这个视角特征提取的方向发展,但是问题在于,并不一定存在一个始终更适合的视角,虽然消融结果显示90度和270度是最佳角度,但不排除有具体某一类由于数据采集等问题产生不同,因此如果是一个CNN,不会有根据输入数据更对应地得出最佳视角,最多是惯性认为某一个视角最佳,简单来说,CNN参数不存在数据依赖性,即判断标准是固定的,不会和输入有交互,因此注意力机制解决了这个问题,而本文的全局特征提取器正是Transformer编码器,因此应当有根据输入更好选择视角的能力。而文中描述局部特征与视角解耦,因此局部特征提取器虽然可能倾向于从最佳视角中选取特征,但两者还是有所不同,毕竟聚合的单位是单个特征而不是视角。既然视角解耦,本身就隐含“全局”的含义,因为与视角无关,因此全局特征指视角间的空间位置,视角间的联系,即视角间的特征,而局部特征表示视角内的特征。所以局部主导特征提取器的主导特征标准应该是大多数类别的标准,是”最大公约数“,因其无法做到参数的数据依赖,所以不可能是“全部”的标准。数据不依赖的如卷积的方法认为只有一个最优的卷积核,而数据依赖的方法如动态卷积认为有多个可用的卷积核,根据输入数据不同动态选择。
摘要
单视角指静脉识别受到受到有限特征,手指旋转平移敏感和2D映射造成的模糊性影响,阻碍了系统表现的提升。为了解决这些问题增强指静脉识别表现。我们应用了多视角指静脉图片,可以提供一个3D指静脉的更丰富特征。我们设计了一种新的低造价全视角指静脉成像设备。我们提出里一个多视角指静脉特征编码和选择网络(MFV-FESNet),基于Transformer编码器可以学习到不同视角间的依赖。通过融合提取到的全局内容特征和局部主导特征,网络可以生成高维特征描述子。
介绍
凭借2D图像处理网络的优势,基于视角的方法在3D目标识别展示了优异的表现。然而,在多视角指静脉识别的3D指静脉生物识别研究还不充分,现存的方法在视角间一致地提取特征而忽略视角间显著信息的差别。现存的多视角指静脉数据集稀缺难以获取。在这边文章中,我们设计了一个新颖的低成本全视角指静脉成像设备并且建立了多视角指静脉数据集。除此之外,我们提出里一个多视角指静脉识别网络,称为多视角指静脉特征编码和选择网络,可以有效提取3D血管特征并且增强识别表现通过融合局部主导特征和全局内容特征。我们的贡献总结如下:
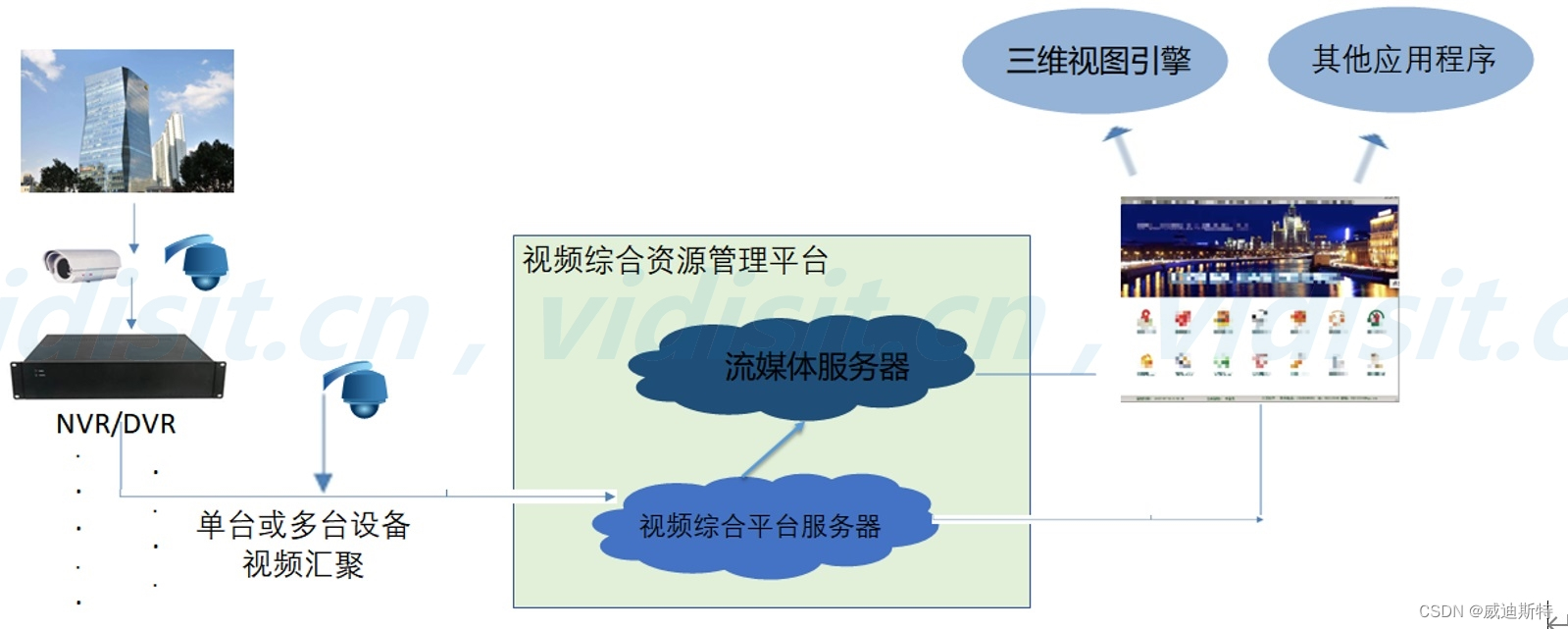
- 一个新颖的低成本全视角指静脉成像设备
- 多视角指静脉数据集
- 多视角指静脉特征编码和选择网络
- 提出的方法取得优秀的表现
多视角指静脉识别
模型结构

一个浅层网络保存更多的底层图片信息,当网络变深时,可以提取到丰富的语义信息。因此我们采用一个千层全卷积神经网络(FCN)来提取原始描述子并通过一个CNN来生成视角描述子。FCN部分包含ResNet-18的最上面5层,CNN则包含了ResNet18剩余的层。给定一组多视角指静脉图片,每个视角通过FCN和CNN并顺序获取它们相应的视角描述子。之后,视角描述子和原始描述子被送入到内容特征编码Transformer(CFET)中和主导特征选择模块(DFSM)来获取对应全局内容特征和局部主导特征。最后,这两个特征融合生成最后的描述子。
内容特征编码Transformer(CFET)
为了学习到不同视角间的关系并且提取全局信息,我们设计了CFET来进一步处理生成的视角描述子 V = { v 1 , v 2 , . . . , v 3 } , v i ∈ R 1 × D 0 V = \{v_1,v_2,...,v_3\},v_i\in \mathbb{R}^{1\times D_0} V={v1,v2,...,v3},vi∈R1×D0。最后我们将视角描述子映射到D维,并初始化可学习的全局类token v c l a s s ∈ R 1 × D v_{class} \in \mathbb{R}^{1\times D} vclass∈R1×D到序列的头部。 E p o s ∈ R ( N + 1 ) × D E_{pos}\in{\mathbb{R}^{(N+1)\times D}} Epos∈R(N+1)×D被添加到序列来获取每个角度的位置信息。
Z 0 = [ v c l a s s ; v 1 E ; v 2 E ; . . . ; v N E ] + E p o s Z 0 ∈ R ( N + 1 ) × D , E ∈ R D 0 × D Z_0 = [v_{class};v_1E;v_2E;...;v_NE]+E_{pos} \\ Z_0 \in{\mathbb{R}^{(N+1)\times D}},E\in{\mathbb{R}^{D_0 \times D}} Z0=[vclass;v1E;v2E;...;vNE]+EposZ0∈R(N+1)×D,E∈RD0×D
在transformer编码器中有四种操作,层归一化,多头注意力,多层感知机和残差连接。长程交互可以通过自注意力捕捉,在这个模型,可以进一步探索不同视角间的关系。多头注意力使模型可以联合关注一个位置不同表达子空间的信息,因此在视角间提取并创建多种联系。
Z ^ 0 = L N ( Z 0 ) , Z ^ 0 ∈ R ( N + 1 ) × D Z 1 = M S A ( Z ^ 0 ) + Z 0 , Z ^ 1 ∈ R ( N + 1 ) × D \hat{Z}_0 = LN(Z_0),\hat{Z}_0 \in{\mathbb{R}^{(N+1)\times D}}\\ Z_1 = MSA(\hat{Z}_0)+Z_0,\hat{Z}_1 \in{\mathbb{R}^{(N+1)\times D}} Z^0=LN(Z0),Z^0∈R(N+1)×DZ1=MSA(Z^0)+Z0,Z^1∈R(N+1)×D
MLP帮助增强模型的泛化表现,更好适应复杂的过程。因此, Z 1 Z_1 Z1在 L N LN LN后被送入 M L P MLP MLP层获取 Z ^ 1 \hat{Z}_1 Z^1。 M L P MLP MLP包含两个线性层并且应用GELU激活函数
Z ^ 1 = M L P ( L N ( Z 1 ) ) + Z 1 , Z ^ 1 ∈ R ( N + 1 ) × D \hat{Z}_1 = MLP(LN(Z_1))+Z_1,\hat{Z}_1 \in{\mathbb{R}^{(N+1)\times D}} Z^1=MLP(LN(Z1))+Z1,Z^1∈R(N+1)×D
Z ^ 1 \hat{Z}_1 Z^1包含全视角图片的全局类别token z ^ c l a s s \hat{z}_{class} z^class和不同视角的局部信息 { z ^ 1 , z ^ 2 , z ^ 3 , . . . z ^ N } \{\hat{z}_1,\hat{z}_2,\hat{z}_3,...\hat{z}_N \} {z^1,z^2,z^3,...z^N},我们通过平均池化聚合来得到紧凑的描述子,我们可以获取有易理解3D指静脉特征的全局上下文描述子。
Y c = A v g [ z ^ 1 , z ^ 2 , . . . , z ^ N ] Y_c = Avg[\hat{z}_1,\hat{z}_2,...,\hat{z}_N] Yc=Avg[z^1,z^2,...,z^N]
主导特征选择模块(DFSM)


和上面整体结构中的DFSM对比,可以看到下图所谓的特征生成就是上图的CNN,而主导评估就是上图的主导评分部分中的FCN,FC。而特征选择对应上面的特征选择及之后的聚合。
DFSM旨在扫描两个表达视角并解耦在一组多视角指静脉图片中的主导特征。因为CFET生成的特征关注于表达3D指静脉的全局特征和不同视角间的关系,融合DFSM产生的主导特征可以增强最终描述子的可分辨性。
DFSM的结构如图三所示。FCN收集原始描述子的频道特征通过FC层获取每个视角的初始值,表示为 { x 1 ^ , x 2 ^ , . . . x N ^ } \{\hat{x_1}, \hat{x_2},...\hat{x_N}\} {x1^,x2^,...xN^}。下面的测度用来计算每个视角的主导分数,定义为:
S c o r e ( x i ) = s i g m o i d ( l o g ( a b s ( x i ) ) ) Score(x_i)=sigmoid(log(abs(x_i))) Score(xi)=sigmoid(log(abs(xi)))
我们选择最高两个分数的视角描述子并把它们相加来获取3D指静脉的局部主导特征。值得注意的是这里同一模块的不同视角的CNN是共用参数的。
实验和结果
数据集
THU-MVFV数据集,一根手指静脉的8个不同视角,照相机每旋转45度拍摄一张图片。总共75个对象,拍摄中指和食指,因此共有75 x 2 x 2 = 300类别。两期间隔一到三个月。共有24000张图片,分辨率1280 x 960。
实施细节
使用EER进行结果评估,介绍见上篇文章。
视角研究
我们评估了不同视角在单视角方案上的验证表现,除此之外,我们也融合了不同数量的视角来进行特征提取来研究视角数量的影响。实验结果如图1所示。确保验证公平性,我们采用了ResNet-18来进行单视角验证,用MVCNN来进行多视角验证。

如图一所示,不同视角的验证表现相差较大,手指的正上方正下方效果最好,表明这两个视角保存了更多的信息。左右两个方向导致了最高的ERR,因为这些视角血管的稀疏性。在多视角验证中,我们选择2, 4, 8 角度相同的视角。表明了多视角的优越性。
池化层的作用

我们比较了平均池化和最大池化。可以看到平均池化表现更好,因为平均池化保存了不同视角的整体信息
消融实验
我们对每个模块的有效性做了验证。结果显示在表三。CFET设计用来学习不同视角间的关系并且提取3D指静脉的全局上下文特征,而DFSM用来通过一组图片中的主导特征选择视角。CEFT表现比DFSM好。
和SOTA方法比较

所有方法除HCAN外都采用ResNet18作为backbone。View-GCN基于图神经网络结构,GVCNN基于CNN,OVPT基于TransFormer。