![]() 个人主页: SueWakeup
个人主页: SueWakeup
![]() 系列专栏:学习技术栈
系列专栏:学习技术栈
![]() 个性签名:保留赤子之心也许是种幸运吧
个性签名:保留赤子之心也许是种幸运吧


目录
注:手机端浏览本文章可能会出现 “目录”无法有效展示的情况,请谅解,点击侧栏目录进行跳转
本栏传送门
1. Redis 中的事务
概念:Redis事务中的所有命令都会序列化、按顺序的执行。
事务在执行的过程中不会被其他客户端发送来的命令请求所打断。
主要作用:串联多个命令防止别的命令插队
特点:
- Redis事务没有隔离级别的概念
- 所有的命令在事务中,没有被直接执行,只有发起执行命令的时候才会执行
- Redis单条命令保存原子性,但是事务不保证原子性
常用命令:
- multi:标记一个事务的开始
- exec:执行所有事务块内的命令
- discard:取消事务,放弃执行事务块内的所有命令
- watch key:监视一个或多个key,如果在事务执行之前这些key被其他命令所改动,那么事务将被打断。
- unwatch:取消watch命令对所有key的监视
为什么添加事务?
- 悲观锁:每次在拿取数据的时候都会上锁,其他请求想获取这个数据就会block直到它拿到锁。传统的关系型数据库里就用到了很多这种锁机制,比如行锁、表锁、读锁、写锁等,都是在操作之前先上锁
- 乐观锁: 每次在拿取数据的时候不会上锁,但是在更新的时候会判断一下在此期间别人有没有更新数据;适用于多读的应用类型,可以提高吞吐量。Redis 就是利用这种 check-and-set 机制实现事务的。
2. Redis 持久化
Redis是内存数据库,一旦服务器进程退出,服务器中的数据库状态也会消失,所以需要Redis持久化
持久化过程:
- RDB:将当前数据状态进行保存,快照形式存储数据结果,存储格式简单,关注点在数据
- AOF:将数据的操作过程进行保存,日志形式存储操作过程,关注点在数据库的操作过程
2.1 RDB 方式
2.1.1 RDB手动
命令:save
作用:手动执行一次保存操作
配置:
- dbfilename dump.rdb
说明:设置本地数据库文件名,默认值为dump.rdb
经验:通常设置为 dump-端口号.rdb
- dir
说明:设置存储.rdb文件的路径
经验:通常设置成存储空间较大的没目录中,目录名称为data
- rdbcompression yes
说明:设置存储至本地数据库时是否压缩数据,默认为yes,采用LZF算法压缩
经验:通常默认为开启状态,如果设置为no,可以节省cpu运行时间,但会使存储的空间变大
- rdbchecksum yes
说明:设置是否进行CRC64算法RDB文件格式校验,该校验过程在写文件和读文件过程均进行
经验:通常默认为开启状态,如果设置为no,可以节约读写性过程约10%时间消耗,但是存在一定的数据损害风险
save指令工作原理(单线程任务执行序列)
客户端1 127.0.0.1:6379>set key1 value1
客户端2 127.0.0.1:6379>set key2 value2
客户端3 127.0.0.1:6379>save
客户端4 127.0.0.1:6379>get key
对redis数据库执行4此指令顺序===> set set save get
注意:save指令的执行会阻塞当前Redis服务器,直到当前RDB过程完成为止,有可能会造成长时间阻 塞,线上环境不建议使用
- bgsave指令
命令 :bgsave
作用 :手动启动后台保存操作,但不是立即执行
注意: bgsave命令是针对save阻塞问题做的优化。Redis内部所有涉及到RDB操作都采用bgsave的方 式,save命令可以放弃使用
- fork
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
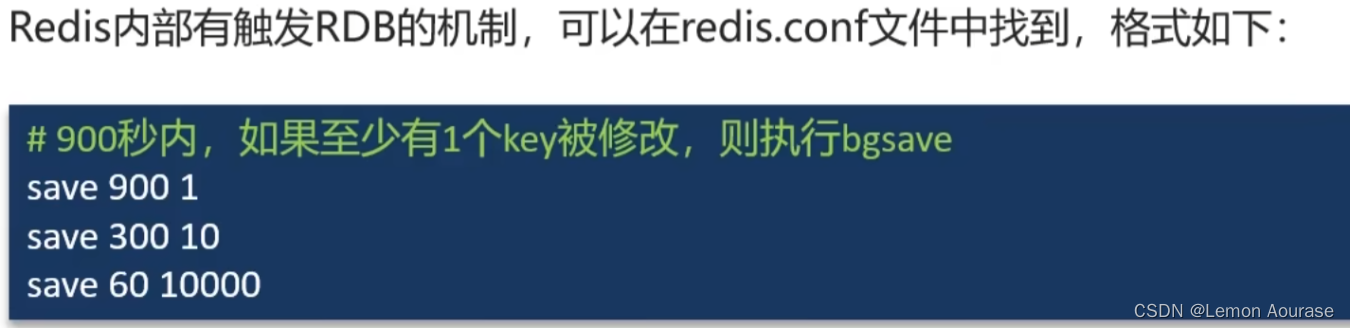
2.1.2 RDB自动
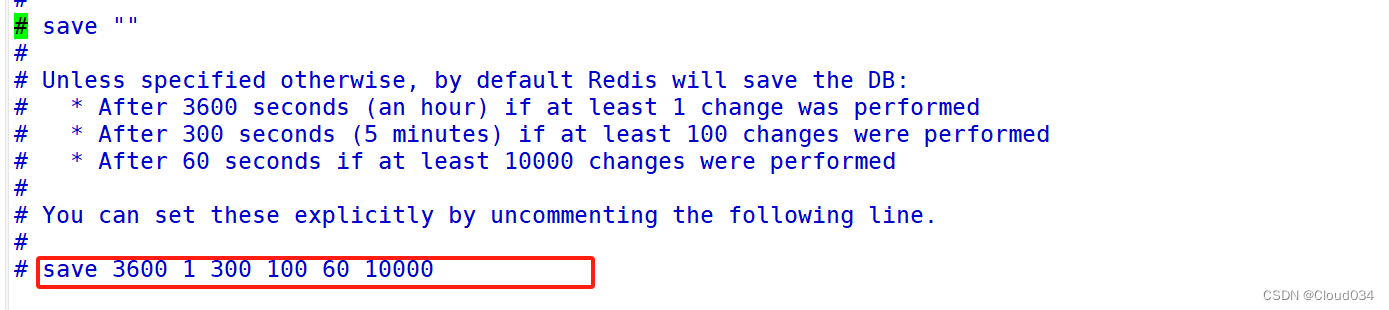
配置 :save second changes
作用 : 满足限定时间范围内key的变化数量达到指定数量即进行持久化
参数 :
second:监控时间范围
changes:监控key的变化量
位置 : 在conf文件中进行配置
注意:
- save配置要根据实际业务情况进行设置,频度过高或过低都会出现性能问题,结果可能是灾难性的
- save配置中对于second与changes设置通常具有互补对应关系,尽量不要设置成包含性关系
- save配置启动后执行的是bgsave操作
优点:
- 紧凑压缩的二进制文件,存储效率高,节省磁盘空间,恢复数据速度比AOF快
- 内部存储redis在某个时间点的数据快照,适合用于数据备份
缺点:
- Redis在fork时使用了写时拷贝技术,内存中的数据被克隆了一份,数据庞大会消耗性能
- 无法做到实时持久化,较大的可能丢失数据
- 版本不统一,不同版本之间存在兼容问题
2.2 AOF方式
概念: 以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令 达到恢复数据的目的;
主要作用:解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
2.2.1 AOF执行过程
客户端的请求写命令会被append追加到AOF缓冲区内;
AOF缓冲区根据AOF持久化策略将操作同步到磁盘的AOF文件
AOF文件大小超过重写策略或手动重写时,会对AOF文件重写,压缩AOF文件容量
Redis服务重启时,会重新加载AOF文件中的写操作达到数据恢复的目的;
2.2.2 AOF写数据的策略
always每次:每次写入操作均同步到AOF文件中,数据零误差,性能较低
everysec每秒:每秒将缓冲区中的指令同步到AOF文件中,数据准确性较高,性能较高
在系统突然宕机的情况下丢失1秒内的数据
no系统控制:由操作系统控制每次同步到AOF文件的周期,过程不可控
2.2.3 AOF相关配置
配置 :appendonly yes|no
作用 :是否开启AOF持久化功能,默认为不开启状态
配置 :appendfsync always|everysec|no
作用 :AOF写数据策略
配置:appendfilename filename
作用:AOF持久化文件名,默认文件名未appendonly.aof,建议配置为appendonly-端口号.aof
配置:dir
作用 :AOF持久化文件保存路径,与RDB持久化文件保持一致即可
2.2.4 AOF写数据遇到的问题
2.2.5 AOF重写
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入了AOF重写机制压缩文件体积。AOF文件重写是将Redis进程内的数据转化为写命令同步到新AOF文件的过程。
将对同一个数据的若干个条命令执行结果转化成最终结果数据对应的指令进行记录
作用:
- 降低磁盘占用量,降低持久化写时间,降低数据恢复用时
- 提高磁盘利用率,提高持久化效率,提高IO性能,提高数据恢复效率
2.2.6 AOF重写规则
进程内已超时的数据不再写入文件
忽略无效指令,重写时使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令
对同一数据的多条写命令合并为一条命令
为防止数据量过大造成客户端缓冲区溢出,对list、set、hash、zset等类型,每条指令最多写入64个元 素
AOF和RDB同时开启,系统默认取AOF的数据(数据不会存在丢失)
2.2.7 AOF重写方式
手动重写 bgrewriteaof
自动重写
触发机制:何时重写 Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发;重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担 的,因此设定Redis要满足一定条件才会进行重写
auto-aof-rewrite-min-size 设置重写的基准值,最小文件64MB。达到这个值开始重写。
auto-aof-rewrite-percentage 设置重写的基准值,文件达到100%时开始重写(文件是原 来 重写后文件的2倍时触发
2.2.8 RDB 和 AOF 的区别
持久化方式 RDB AOF 占用存储空间
小(数据级:压缩)
大(指令级:重写) 存储速度
慢 快 恢复速度
快
慢 数据安全性
会丢失数据 依据策略决定 资源消耗
重量级 轻量级 启动优先级
低 高






![[<span style='color:red;'>Redis</span>]——<span style='color:red;'>Redis</span><span style='color:red;'>持久</span><span style='color:red;'>化</span><span style='color:red;'>的</span>两种<span style='color:red;'>方式</span>RDB、AOF](https://img-blog.csdnimg.cn/direct/2dcfc522601b482e99eb71bdc5bb06d5.png)



















![Nvidia 的浪潮和护城河 [译]](https://img-blog.csdnimg.cn/direct/b86d59058b804d72ac9731818c8950c4.png)