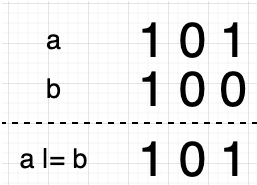day28上
集合框架
标绿已经学习底层,深入底层主要是研究实现类底层

手撕HashMap底层源码
JDK1.7版本的HashMap为例(注意实验代码时进行版本切换)
代码注释参考理解
//day27初识
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>{
//默认初始化容量 -- 必须是2的幂
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//空内容的数组
static final Entry<?,?>[] EMPTY_TABLE = {};
//hash数组/hash表
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;//new Entry[16];
//元素个数
transient int size;//4
//阈值(数组长度*负载因子)
int threshold;//12
//负载因子
final float loadFactor;//0.75f
//外部操作数(记录添加、删除的次数)
transient int modCount;//4
//hash种子数
transient int hashSeed = 0;//0
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
//initialCapacity - 16
//loadFactor - 0.75f
public HashMap(int initialCapacity, float loadFactor) {
//判断数组初始化容量如果小于0,就报错
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//判断数组容量大于最大容量,就把最大容量赋值给初始化容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//判断负载因子如果小于等于0 或者 判断负载因子不是一个数字,就报错
if (loadFactor <= 0 || Float.isNaN(loadFactor))//NaN - Not a Number
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();//作用:让子类去重写(LinkedHashMap),子类做初始化功能
}
void init() {
}
//day28上:添加过程代码底层
//key - null
//value - "bbb"
public V put(K key, V value) {
//第一添加时,进入的判断
if (table == EMPTY_TABLE) {
//1.计算出阈值 -- 12
//2.初始化hash数组 -- new Entry[16]
//3.初始化hashSeed(Hash种子数)
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
//通过key获取hash值 -- 20
int hash = hash(key);
//利用key的hash值计算在数组中的下标 -- 4
int i = indexFor(hash, table.length);
//判断当前下标上是否有元素 -- 进入到该循环就说明hash碰撞了
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//判断key和Entry中的key是否相同(hash && == || equals)
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//oldValue - 玩游戏
V oldValue = e.value;
//e.value - 写代码
e.value = value;
e.recordAccess(this);
return oldValue;//返回被替换的值
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
//value - "bbb"
private V putForNullKey(V value) {
//判断下标为0的位置上是否有元素 -- 进入到该循环就说明hash碰撞了
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
//判断Entry里的key是否为空,说明下标为0的位置上可能会存储其他key不为空的Entry对象
if (e.key == null) {
//oldValue - aaa
V oldValue = e.value;
//e.value - bbb
e.value = value;
e.recordAccess(this);
return oldValue;//返回被替换的值
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
//子类的挂钩:让子类(LinkedHashMap)重写的方法
void recordAccess(HashMap<K,V> m) {
}
//hash -
//key -
//value -
//bucketIndex -
void addEntry(int hash, K key, V value, int bucketIndex) {
//判断元素个数大于等于阈值并且当前下标的元素不为null,就扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容 -- 原来数组长度的2倍
resize(2 * table.length);
//通过key重新计算hash值
hash = (null != key) ? hash(key) : 0;
//通过hash值重新计算在数组中的下标
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
//newCapacity - 32
void resize(int newCapacity) {
//获取table
Entry[] oldTable = table;
//oldCapacity - 16
int oldCapacity = oldTable.length;
//如果数组长度已经达到数组的最大值(1<<30)
//就将int类型的最大值赋值给阈值,并且结束当前方法
//目的:以后大概率不会再次调用resize()
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//newTable = new Entry[32];
Entry[] newTable = new Entry[newCapacity];
//1.initHashSeedAsNeeded(newCapacity) --重新计算hash种子数
//2.将table的Entry数据赋值给newTable
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//将newTable的内存地址赋值给table
table = newTable;
//重新计算阈值:threshold-24
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//newTable - new Entry[32];
void transfer(Entry[] newTable, boolean rehash) {
//newCapacity - 32
int newCapacity = newTable.length;
//遍历hash数组
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
//hash - 0
//key - null
//value - "aaa"
//bucketIndex - 0
void createEntry(int hash, K key, V value, int bucketIndex) {
//e - null
Entry<K,V> e = table[bucketIndex];
//JDK1.7版本的HashMap是头插法
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
//h - 20
//length - 16
static int indexFor(int h, int length) {
//20 -- 0001,0100
//15 -- 0000,1111
// 0000,0100
// 20 & (16-1)
return h & (length-1);
}
//k - new Student("小小", '男', 23, "2401", "001")
final int hash(Object k) {
//获取hash种子数
int h = hashSeed;
//判断种子数不等于0 并且 k的类型为String
if (0 != h && k instanceof String) {
//利用stringHash32()计算字符串的hash值(目的:减少hash碰撞)
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//toSize - 16
private void inflateTable(int toSize) {
// 2的幂的数字的特点:在二进制表示中只有一位为1,其余全是0
//toSize-16,返回16
//toSize-19,返回32
//toSize-30,返回32
// capacity - 16
int capacity = roundUpToPowerOf2(toSize);
//threshold - 12
//threshold = (int) Math.min(16 * 0.75f, (1<<30) + 1);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//初始化hash数组 -- new Entry[16];
table = new Entry[capacity];
//初始化hash种子数
initHashSeedAsNeeded(capacity);
}
final boolean initHashSeedAsNeeded(int capacity) {
boolean currentAltHashing = hashSeed != 0;
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
//number - 16
private static int roundUpToPowerOf2(int number) {
// 保留二进制中最高位的1,其余变成0
// Integer.highestOneBit((number) << 1)
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
//映射关系类/节点类
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; --------- key
V value; ------------- value
Entry<K,V> next; ----- 下一个节点的地址
int hash; ------------ key的hash值
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
}
场景:
HashMap<Student, String> map = new HashMap<>();
map.put(new Student("小小", '男', 23, "2401", "001"), "拍电影");
map.put(new Student("大大", '男', 20, "2401", "002"), "打篮球");
map.put(new Student("奇男子", '男', 21, "2401", "003"), "玩游戏");
map.put(new Student("奇男子", '男', 21, "2401", "003"), "写代码");
map.put(null, "aaa");
map.put(null, "bbb");
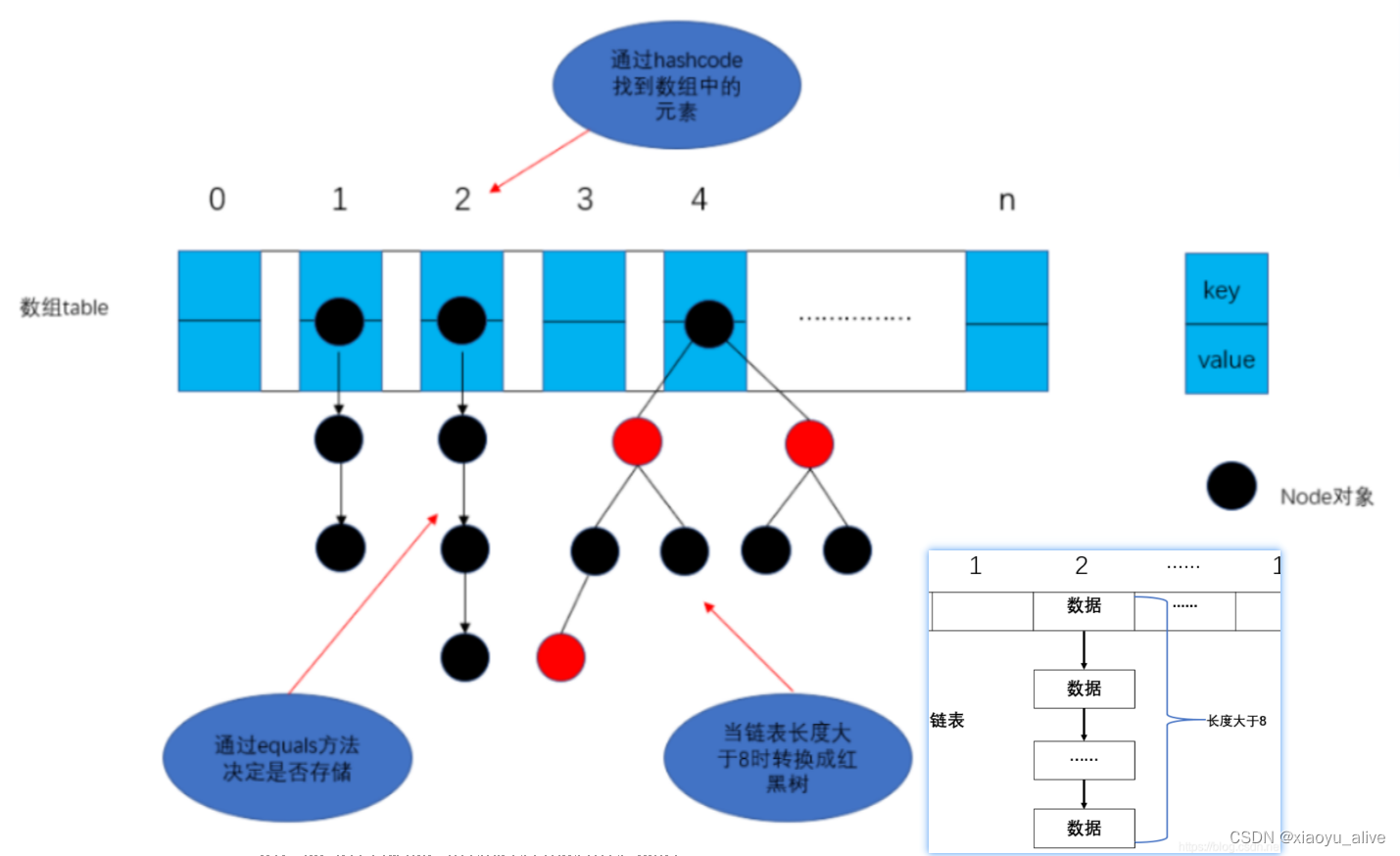
HashMap理解图

init();的作用
让子类去重写(LinkedHashMap),子类做初始化功能
伪代码理解:LinkedHashMap调用父类的有参构造,int()返过来调用子类LinkedHashMap中重写的int();

面试题
JDK1.7版本的HashMap是什么数据结构?
一维数组+单向链表
什么是Hash桶?
hash数组里的单向链表
什么是hash碰撞/hash冲突?
key的hash值一致,在数组中的下标上有重复的元素
HashMap里的hash碰撞是如何优化的?
根据需求重写hashCode(),尽可能保证hash值不相同,减少hash碰撞的次数
HashMap默认数组长度是多少?
长度是1<<4,就是16的长度
HashMap数组的长度为什么必须是2的幂?
2的幂的数字的特点为二进制中只有1位为1,其余为0(16–0001,0000)
2的幂的数字-1的特点为二进制中原来为1的位置变为0,后续的位置全变成1(15–0000,1111)
计算key在数组中的下标的算法:hash值 & 长度-1
如果数组长度不是2的幂会导致散列不均匀
HashMap数组的最大容量是多少?
1<<30
HashMap数组的最大容量为什么是1<<30?
最大容量为int类型,int类型的最大值是2的31次方-1
因为HashMap数组必须是2的幂,1<<30是int取值范围内最大的2的幂的数字
所以HashMap数组最大容量是1<<30
HashMap默认负载因子是多少?
0.75f
HashMap的负载因子的作用是什么?
数组长度*负载因子 等于 阈值,阈值是控制何时扩容
HashMap数组默认的负载因子为什么是0.75f?
取得了空间和时间的平衡
如果负载因子过大(1),会导致数组全部装满后,再扩容。利用了空间,浪费了时间
如果负载因子过小(0.2),会导致数组装了一点点元素,就扩容。利用了时间,浪费了空间
HashMap何时扩容?
元素个数大于等于阈值并且当前下标的元素不为null,就扩容
HashMap扩容机制是什么?
原来长度的2倍
HashMap存放null键的位置在哪?
hash数组下标为0的位置
HashMap的hash回环/死循环是何时发生的?
在多线程的情况下,一个线程不断的添加数据,导致扩容,链表地址发生回环。一个线程不断的遍历数据。
如果发生hash回环应该是程序员负的责任,因为HashMap明确表示该实现不是一个线程安全的,多线程下应该使用ConcurrentHashMap
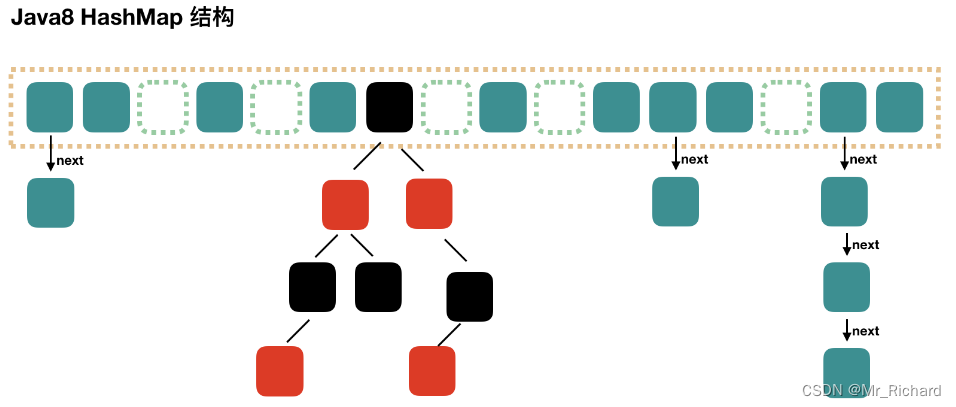
JDK1.7的HashMap和JDK1.8的HashMap有什么区别:
区别1 - 获取key的hash值:
JDK1.7 – 调用key的hashCode() + 位运算
JDK1.8 – 将key的hash值(int-32)分为高16位和低16位,两者进行异或的位运算,比之前更简洁
区别2 - 插入链表的法则:
JDK1.7 – 头插法
JDK1.8 – 尾插法
区别3 - 数据结构:
JDK1.7 – 一维数组 + 单向链表
JDK1.8 – 一维数组 + 单向链表 + 红黑树(目的:加上红黑树提高查询效率)
JDK1.8版本的HashMap数据结构是如何切换的?
初始数据结构为一维数组 + 单向链表
当一维数组长度大于64并且单向链表长度大于8时 --> 一维数组 + 红黑树
当链表长度小于6时 --> 一维数组 + 红黑树 转换为一维数组 + 单向链表
JDK1.8的HashMap为什么链表长度大于8会将单向链表转换为红黑树?
为了提高查询效率,大于8是因为泊松分布
总结:
注重面试题