并查集的概念
并查集是一种简单的集合表示,它支持以下三种操作
1. make_set(x),建立一个新集合,唯一的元素是x
2. find_set(x),返回一个指针,该指针指向包含x的唯一集合的代表,也就是x的根节点
3. union_set(x,y),将包含x和y的两个集合合并成一个新的集合
并查集的存储结构
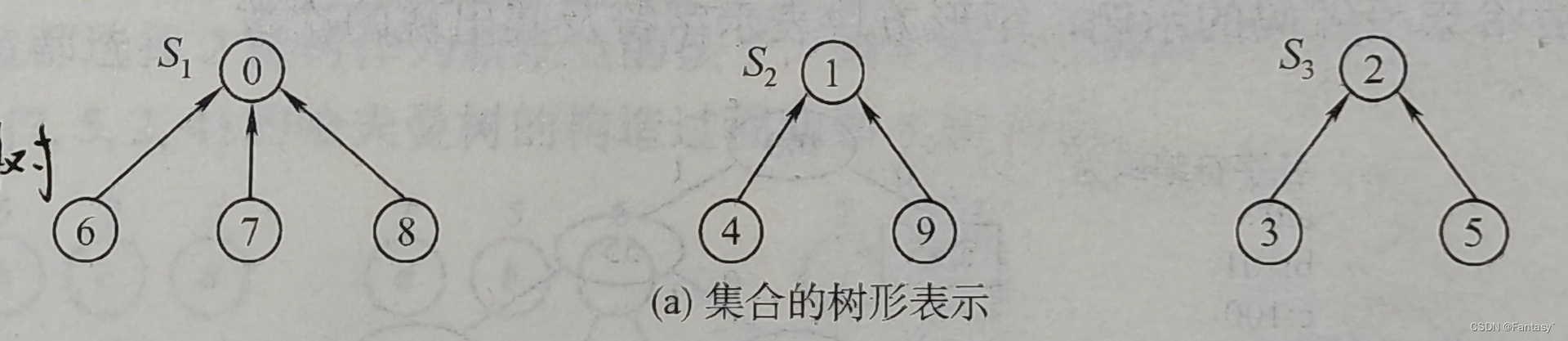
通常用树的双亲表示作为并查集的存储结构,每个子集合以一棵树表示。某节点的根节点代表了该结点所属的集合。所有表示子集合的树,构成表示全集合的森林。

经过union_set(0,6),union_set(6,7),union_set(0,8)后形成S1
经过union_set(1,4),union_set(4,9)后形成S2
经过union_set(2,5),union_set(2,3)后形成S3
并查集的基本实现
存储结构定义
使用树的双亲表示法(链式存储)。当然也可以顺序存储实现,顺序存储实现我放在了最下面的例题中。
using ElemType = int;
struct DisjointSetNode
{
ElemType data;//数据
struct DisjointSetNode* parent;//指向父节点
};make_set(x)
新建一个集合,集合中唯一的元素是x,此时x是根节点,x的父节点指针指向自己。
void make_set(DisjointSetNode* node)
{
if(node != nullptr)
{
node->parent = node;
}
else
{
throw std::invalid_argument("make_set error: node must not be nullptr!");
}
}
find_set(x)
返回一个指针,该指针指向包含x的唯一集合的代表,也就是x的根节点。根节点的判断条件:node->parent == node。只需递归地寻找父结点,直到node->parent == node。
时间复杂度与树的高度相关,最坏时间复杂度为O(n)
DisjointSetNode* find_set(DisjointSetNode* node)
{
if(node == nullptr)
{
throw std::invalid_argument("make_set error: node must not be nullptr!");
}
if(node->parent != node)
{
node = find_set(node->parent);
}
return node;
}union_set(x,y)
将包含x和y的两个集合合并成一个新的集合,我的代码实现是将y并入x。单只是合并,时间复杂度为O(1)。算上两次find_set的时间复杂度为O(n)。
void link_set(DisjointSetNode* rootX, DisjointSetNode* rootY)
{//集合X的根节点为rootX,集合Y的根节点为rootY,将集合X与集合Y合并
if(rootX == nullptr || rootY == nullptr)
{
throw std::invalid_argument("make_set error: node must not be nullptr!");
}
rootY->parent = rootX;
}
void union_set(DisjointSetNode* nodeX, DisjointSetNode* nodeY)
{
DisjointSetNode* rootX = find_set(nodeX);
DisjointSetNode* rootY = find_set(nodeY);
if(rootX == rootY)
{//如果nodeX和nodeY是同一个集合的元素,则不能合并
return;
}
link_set(rootX, rootY);
}按秩合并和路径压缩
上面提到,并和查的时间开销主要在“查”上,而查的时间复杂度与树的高度相关,是O(h)。
那么只要降低树的高度,就能大幅降低时间开销。
降低树高度有两种方法,一是按秩合并,二是路径压缩。
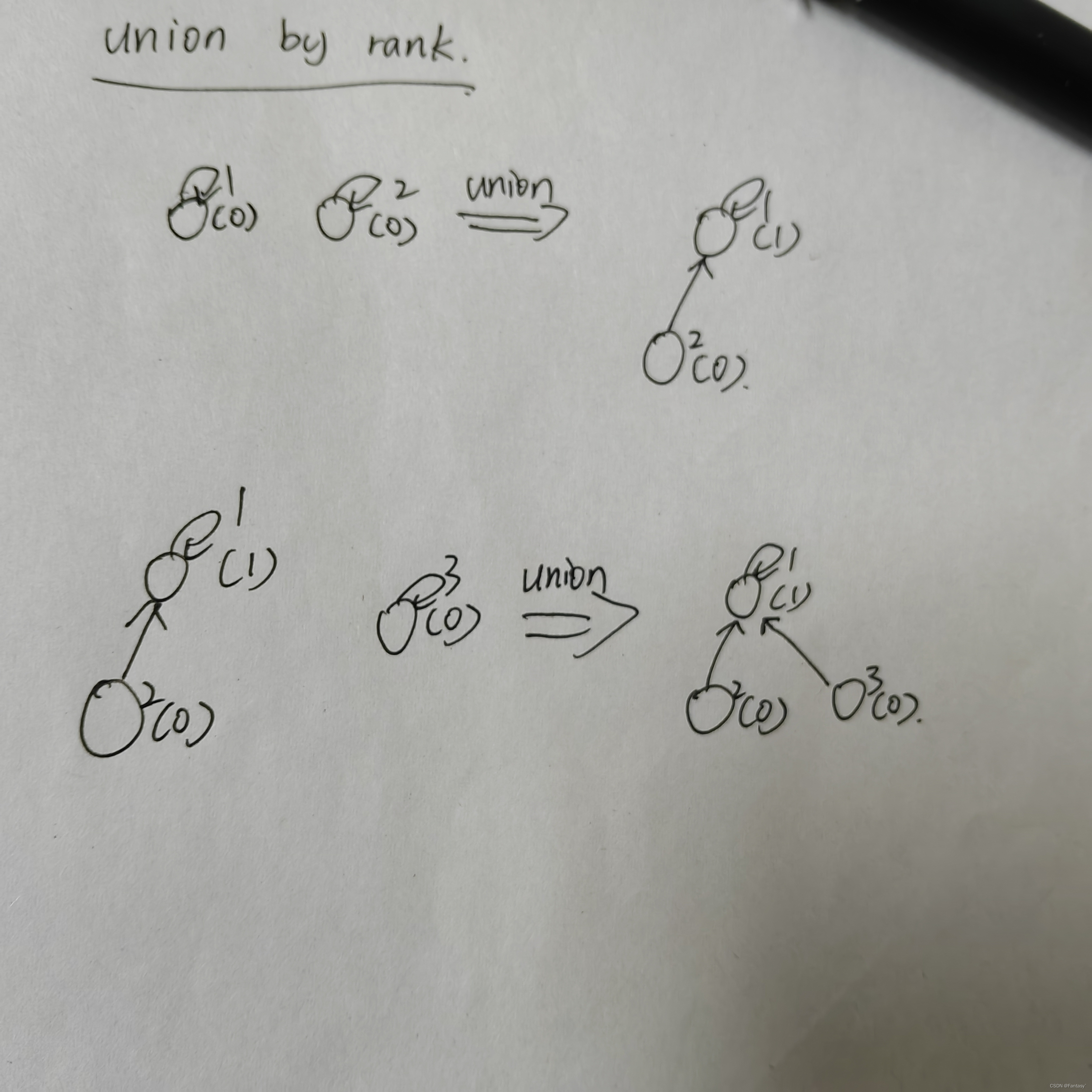
按秩合并
每个结点x维持一个整数值属性rank,它代表了x的高度(x的叶结点到x的最长路径长度)。在按秩合并的union操作中,我们让具有较小秩的根指向具有较大秩的根
路径压缩
在`find_set`操作中,使查找路径中的每个结点直接指向树根
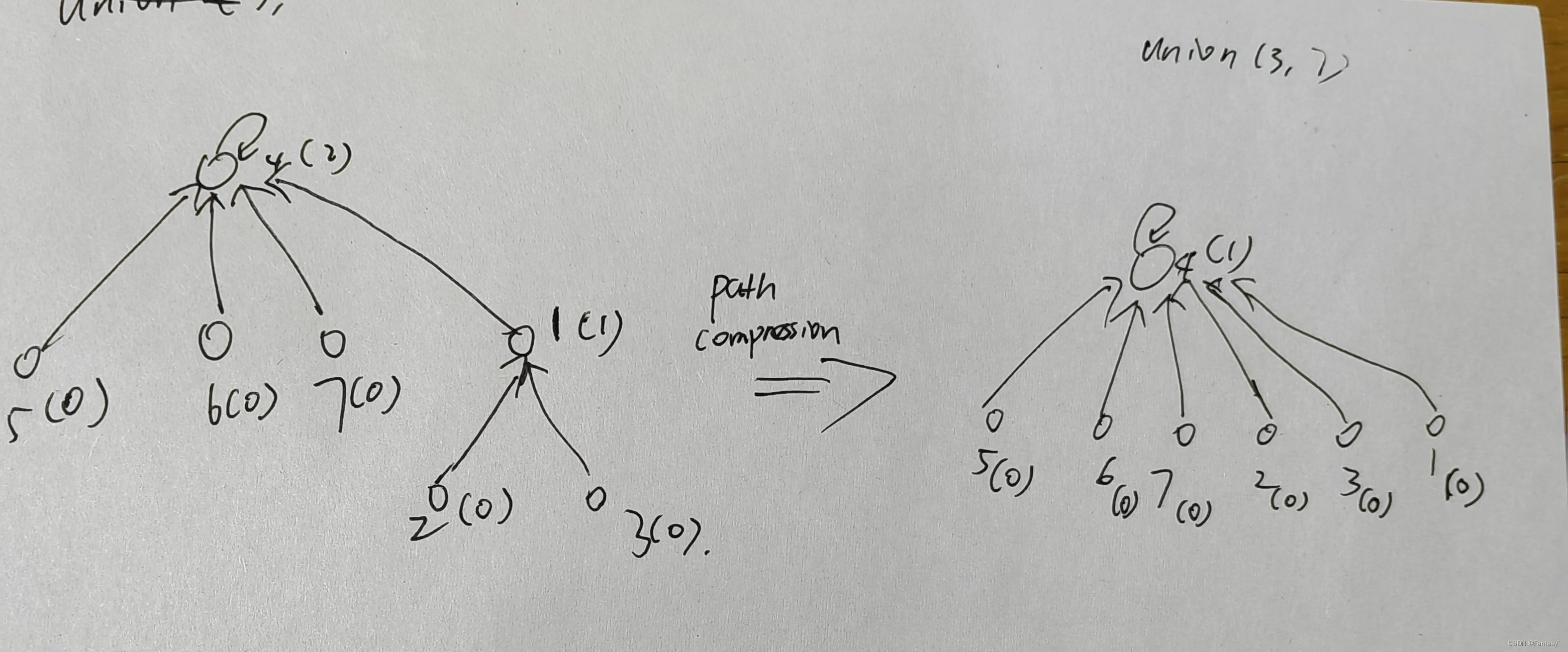
最终代码
链式存储实现
//
// Created by user on 2024/3/16.
//
#include <stdexcept>
//并查集 disjoint set
//并查集包括三个操作,1. make_set(x),建立一个新集合,唯一的元素是x
//2. find_set(x),返回一个指针,该指针指向包含x的唯一集合的代表,也就是x的根节点
//3. union_set(x,y),将包含x和y的两个集合合并成一个新的集合
/*
* 这里采用了启发式策略改进运行时间,使用了两种启发式策略:
* - 按秩合并:每个结点x维持一个整数值属性rank,它代表了x的高度(从x到某一后代叶结点的最长简单路径上的结点数目)的一个上界。在按秩合并的union操作中,
* 我们让具有较小秩的根指向具有较大秩的根
* - 路径压缩:在`find_set`操作中,使查找路径中的每个结点直接指向树根
*
* 如果单独采用按秩合并或者路径压缩,它们每一个都能改善不相交集合森林上操作的运行时间;而一起使用这两种启发式策略时,这种改善更大。
* 当同时使用按秩合并和路径压缩时,最坏情况下的运行时间为O(m*alpha*n)),这里alpha(n)是一个增长非常慢的函数。在任何一个可以想得到的不相交集合数据结构的应用中,
* alpha(n)<=4。其中n为结点个数,m为操作次数(运用了摊还分析)
*/
using ElemType = int;
struct DisjointSetNode
{
ElemType data;//数据
struct DisjointSetNode* parent;//指向父节点
int rank;//rank代表结点的高度,即从该节点到叶子节点的最长路径的长度
};
void make_set(DisjointSetNode* node)
{
if(node != nullptr)
{
node->parent = node;
node->rank = 0;
}
else
{
throw std::invalid_argument("make_set error: node must not be nullptr!");
}
}
/*
* 该操作简单沿着指向父节点的指针找到树的根。树的根的特征是:它的父节点就是它本身。
* 若结点不在不相交集合森林中(当结点的父节点指针为空时),则抛出异常。
*
* find_set过程是一个 two_pass method,当它递归时,第一趟沿着查找路径向上直到找到树根;
* 当递归回溯时,第二趟沿着搜索树向下更新每个节点,使其父节点直接指向树根
* find_set 包含“压缩路径”优化
*/
//find_set
DisjointSetNode* find_set(DisjointSetNode* node)
{
if(node == nullptr)
{
throw std::invalid_argument("make_set error: node must not be nullptr!");
}
if(node->parent != node)
{
node->parent = find_set(node->parent);
}
return node->parent;
}
//每个结点x维持一个整数值属性rank,它代表了x的高度
//(从x到某一后代叶结点的最长简单路径上的结点数目)的一个上界。
// 在链接时我们让具有较小秩的根指向具有较大秩的根,这样可以降低树的深度,从而减少find_set的时间消耗
void link_set(DisjointSetNode* rootX, DisjointSetNode* rootY)
{//集合X的根节点为rootX,集合Y的根节点为rootY,将集合X与集合Y合并
if(rootX == nullptr || rootY == nullptr)
{
throw std::invalid_argument("make_set error: node must not be nullptr!");
}
if(rootX->rank > rootY->rank)
{//假如集合X的深度大于集合Y的深度,则要将集合Y的根节点指向集合X的根节点,以尽可能地降低深度
rootY->parent = rootX;
}
else
{
rootX->parent = rootY;
if(rootX->rank == rootY->rank)
{//如果深度一样,此时是将X并入Y,则需要让rootY->rank加一
++rootY->rank;
}
}
}
void union_set(DisjointSetNode* nodeX, DisjointSetNode* nodeY)
{
DisjointSetNode* rootX = find_set(nodeX);
DisjointSetNode* rootY = find_set(nodeY);
if(rootX == rootY)
{//如果nodeX和nodeY是同一个集合的元素,则不能合并
return;
}
link_set(rootX, rootY);
}例题
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
这里用了顺序存储实现并查集,并使用了路径压缩和按秩合并的优化方法。时间复杂度为O(α(n) * n^2),其中α(n)是一个增长极其缓慢的函数,通常α(n)≤4
class Solution {
public:
vector<int> parent;//parent[x]代表x的父节点
vector<int> rank;//rank[x]代表x的秩,也就是x到叶结点的最长路径长度
//并查集的顺序存储方式。
//如何判断结点x是否是树的根节点? parent[x] == x
//如何找到根结点? if(parent[x] != x) {递归调用}
int findCircleNum(vector<vector<int>>& isConnected) {
int province_num = 0;
int size = isConnected.size();
initDisjointSet(parent, rank, size);
for(int i = 0;i < size;++i)
{
for(int j = i+1;j < size;++j)
{
if(isConnected[i][j] == 1)
{//假如i与j相连,则合并i,j所在的集合
union_set(parent, i, j);
}
}
}
for(int i = 0;i < size;++i)
{
if(parent[i] == i)
{
++province_num;
}
}
return province_num;
}
void initDisjointSet(vector<int>& parent, vector<int>& rank, int size)
{
parent.resize(size);
rank.resize(size, 0);//rank的初始值为0
for(int i = 0;i < size;++i)
{//初始化并查集,此时每个元素本身自成一个集合
parent[i] = i;
}
}
/*
* find_set过程是一个 two_pass method,当它递归时,第一趟沿着查找路径向上直到找到树根;
* 当递归回溯时,第二趟沿着搜索树向下更新每个节点,使其父节点直接指向树根
* find_set 包含“压缩路径”优化
*/
int find_set(vector<int>& parent, int x)
{
if(parent[x] != x)
{
parent[x] = find_set(parent, parent[x]);
}
return parent[x];
}
void link_set(vector<int>& parent, int rootA, int rootB)
{
if(rank[rootA] > rank[rootB])
{//假如A的高度比B高,则B的根节点指向A的根节点
parent[rootB] = rootA;
}
else
{
parent[rootA] = rootB;
if(rank[rootA] == rank[rootB])
{
++rank[rootB];
}
}
}
void union_set(vector<int>& parent, int x, int y)
{
int rootA = find_set(parent, x);
int rootB = find_set(parent, y);
if(rootA == rootB)
{
return;
}
link_set(parent, rootA, rootB);
}
};当然更容易想到的是BFS,每次BFS都会遍历一个连通分量,也就是题目中的省份,设置一个计数器,计算执行了多少次BFS就能得出省份数量。时间复杂度为O(n^2)
附BFS代码
class Solution {
public:
vector<bool> isVisited;
queue<int> queue;
int findCircleNum(vector<vector<int>>& isConnected) {
//思路1:使用BFS对图进行遍历,每次BFS的执行都会遍历完一个省份(连通分量),设置一个计数器计算使用了多少次BFS即可。时间复杂度为O(n^2)
return BFS_Traversal(isConnected);
}
int BFS_Traversal(vector<vector<int>>& isConnected)
{
int province_num = 0;
int verNum = isConnected.size();//图顶点的数量
isVisited.resize(verNum, false);
for(int i = 0;i < verNum;++i)
{//从0号顶点开始遍历
if(!isVisited[i])
{
BFS(isConnected, i);
++province_num;
}
}
return province_num;
}
void BFS(vector<vector<int>>& isConnected, int i)
{
int size = isConnected.size();
//visit
isVisited[i] = true;
queue.push(i);
while(!queue.empty())
{
int v = queue.front();
queue.pop();
for(int i = 0;i < size;++i)
{
if(v != i && isConnected[v][i] != 0 && !isVisited[i])
{
//visit
isVisited[i] = true;
queue.push(i);
}
}
}
}
};