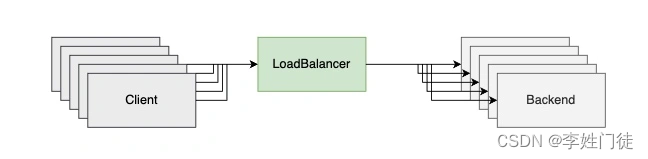
import numpy as np
from keras.models import Sequential, Model
from keras.layers import Dense, LeakyReLU, BatchNormalization, Reshape
from keras.layers import Input, Embedding, Flatten, multiply, Dropout
from keras.datasets import mnist
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import matplotlib
# 条件对抗生成网络
class CGAN():
def __init__(self):
# 写入输入维度
self.img_rows = 28 # 行
self.img_cols = 28 # 列
self.img_channel = 1 # 通道数
self.img_shape = (self.img_rows, self.img_cols, self.img_channel) # 尺寸
self.num_classes = 10 # 类别数
self.latent_dim = 100 # 噪声大小
optimizer = Adam(0.0002, 0.5) # 优化器,学习率0.0002
self.generator = self.build_generator() # 构建生成器
self.discriminator = self.build_discriminator() # 构建判别器
# 判别器训练的配置
self.discriminator.compile(loss=['binary_crossentropy'], # 二进制交叉熵损失函数
optimizer=optimizer,
metrics=['accuracy'])
# 联合训练,固定判别器
self.discriminator.trainable = False
noise = Input(shape=(100,))
label = Input(shape=(1,))
img = self.generator([noise, label]) # 生成的图像
valid = self.discriminator([img, label]) # 判别生成的图像
self.combined = Model([noise, label], valid)
self.combined.compile(loss=['binary_crossentropy'], # 二进制交叉熵损失函数
optimizer=optimizer,
metrics=['accuracy'])
# 生成器
def build_generator(self):
model = Sequential() # 定义网络层
# 第一层
model.add(Dense(256, input_dim=self.latent_dim)) # 全连接层,256个神经元,输入维度100
model.add(LeakyReLU(alpha=0.2)) # 激活层
model.add(BatchNormalization(momentum=0.8)) # BN层,动量0.8
# 第二层
model.add(Dense(512)) # 全连接层
model.add(LeakyReLU(alpha=0.2)) # 激活层
model.add(BatchNormalization(momentum=0.8)) # BN层,动量0.8
# 第三层
model.add(Dense(1024)) # 全连接层
model.add(LeakyReLU(alpha=0.2)) # 激活层
model.add(BatchNormalization(momentum=0.8)) # BN层,动量0.8
# 输出层
model.add(Dense(np.prod(self.img_shape), activation='tanh')) # 计算图像尺寸,激活函数tanh
model.add(Reshape(self.img_shape)) # Reshape层,输入的是噪声,需要的是图像,转换为图像
model.summary() # 记录参数情况
# 定义输入
noise = Input(shape=(self.latent_dim,)) # 生成器的输入维度
label = Input(shape=(1,), dtype='int32') # 生成器的标签维度,1维,类型int
# 使输入Y和X的维度一致。将10个种类的label映射到latent_dim维度
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label)) # 输入维度,输出维度,转换的变量label
# Flatten() 将100维转化为(None, 100),这里None会随着batch而改变
# 合并噪声和类别
model_input = multiply([noise, label_embedding]) # 合并方法:对应位置相乘
# 预测模型输出
img = model(model_input) # 生成图片
return Model([noise, label], img) # [输入],输出。输入按noise和label,合并由内部完成
# 判别器
def build_discriminator(self):
model = Sequential() # 定义网络层
# 第一层
model.add(Dense(512, input_dim=np.prod(self.img_shape))) # 全连接层,512个神经元,输入维度784
model.add(LeakyReLU(alpha=0.2)) # 激活层
# 第二层
model.add(Dense(512)) # 全连接层
model.add(LeakyReLU(alpha=0.2)) # 激活层
model.add(Dropout(0.4)) # Dropout层,防止过拟合,提高泛化性
# 第三层
model.add(Dense(512)) # 全连接层
model.add(LeakyReLU(alpha=0.2)) # 激活层
model.add(Dropout(0.4)) # Dropout层,防止过拟合,提高泛化性
# 输出层
model.add(Dense(1, activation='sigmoid'))
model.summary() # 记录参数情况
# 定义输入
img = Input(shape=self.img_shape) # 输入图片
label = Input(shape=(1,), dtype='int32') # 输入标签
# 使输入Y和X的维度一致。Flatten() 将100维转化为(None, 784),这里None会随着batch而改变
label_embedding = Flatten()(Embedding(self.num_classes, np.prod(self.img_shape))(label)) # 输入维度,输出维度,转换的变量label
flat_img = Flatten()(img)
# 将图片和类别合并
model_input = multiply([flat_img, label_embedding]) # 合并方法:对应位置相乘
# 模型输出结果
validity = model(model_input) # 获取输出概率结果
return Model([img, label], validity) # [输入],输出
# 训练
def train(self, epochs, batch_size=128, sample_interval=50):
# 获取数据集
(X_train, Y_train,), (_, _) = mnist.load_data() # 下载数据集,空的表示不要测试集
# 将获取的图像转化为-1到1
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3) # 扩展维度,在第三维扩展。将60000*28*28的图片扩展为60000*28*28*1
# 将标签大小变为60000*1
Y_train = Y_train.reshape(-1, 1) # -1自动计算第0维的维度空间数
# 写入 真实输出 与 虚假输出
valid = np.ones((batch_size, 1)) # 每行为一张图片
fake = np.zeros((batch_size, 1)) # 每行为一张图片
# imgs shape(batch_size, 28, 281)
# labels shape(32, 1)
for epoch in range(epochs):
# 训练判别器
# 从0~60000随机获取batch_size个索引数
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs, labels = X_train[idx], Y_train[idx] # 获取图像和对应标签
noise = np.random.normal(0, 1, (batch_size, self.latent_dim)) # 产生随机噪声
gen_imgs = self.generator.predict([noise, labels]) # 生成虚假图片
# 损失
d_loss_real = self.discriminator.train_on_batch([imgs, labels], valid)
d_loss_fake = self.discriminator.train_on_batch([gen_imgs, labels], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 训练生成器
sample_label = np.random.randint(0, 10, batch_size).reshape(-1, 1) # 随机生成样本标签
# 固定判别器,训练生成器——在联合模型中
g_loss = self.combined.train_on_batch([noise, sample_label], valid) # 生成器随机生成的图像和随机产生的标签,骗过判别器
# 绘制进度图
print("%d [D loss: %f, acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], d_loss[1] * 100, g_loss[0]))
# 每50次保存图像
if (epoch + 1) % sample_interval == 0:
self.sample_images(epoch)
# 每训练5000次保存模型
if (epoch + 1) % 5000 == 0:
self.save_models(epoch)
def sample_images(self, epoch):
r, c = 2, 5 # 输出 2行5列的10张指定图像
noise = np.random.normal(0, 1, (r * c, 100))
sampled_labels = np.arange(0, 10).reshape(-1, 1)
gen_imgs = self.generator.predict([noise, sampled_labels])
# Rescale images -1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].set_title("Digit: %d" % sampled_labels[cnt])
axs[i, j].axis('off')
cnt += 1
fig.savefig(f"images/sd{epoch+1}.png") # 文件路径和代码文件同目录
plt.close()
def save_models(self, epoch):
self.generator.save(f"models/generator_epoch_{epoch+1}.h5")
self.discriminator.save(f"models/discriminator_epoch_{epoch+1}.h5")
self.combined.save(f"models/combined_epoch_{epoch+1}.h5")
if __name__ == '__main__':
matplotlib.use('TkAgg') # 设置后端为TkAgg
cgan = CGAN()
# 训练轮数20000,一次处理32张图片,每200保存一次生成的已知标签的生成图像
cgan.train(epochs=20000, batch_size=32, sample_interval=200)







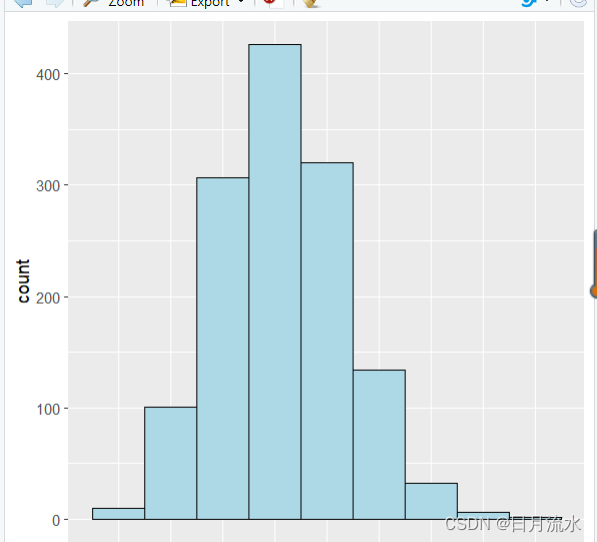
![[足式机器人]Part2 Dr. <span style='color:red;'>CAN</span>学习笔记-<span style='color:red;'>数学</span>基础Ch<span style='color:red;'>0</span>-<span style='color:red;'>9</span>阈值选取-机器视觉中应用正态分布和6-sigma](https://img-blog.csdnimg.cn/direct/da2a8181ad354a1696e704018be21fc4.png#pic_center)