作者:UltralyticsLLC公司
代码:https://github.com/ultralytics/yolov5
YOLO系列其他文章:
文章目录
1、算法概述
YOLOv5和YOLOv4都是在2020年发布,不同的是YOLOv5没有论文,是以工程的方式发布的,至今在工业界都还有很多应用,且模型泛化性能非常不错,代码中的很多细节处理值得我们学习。且作者也有在持续改进优化代码,现在已经更新到7.0版本了。先看代码结构:
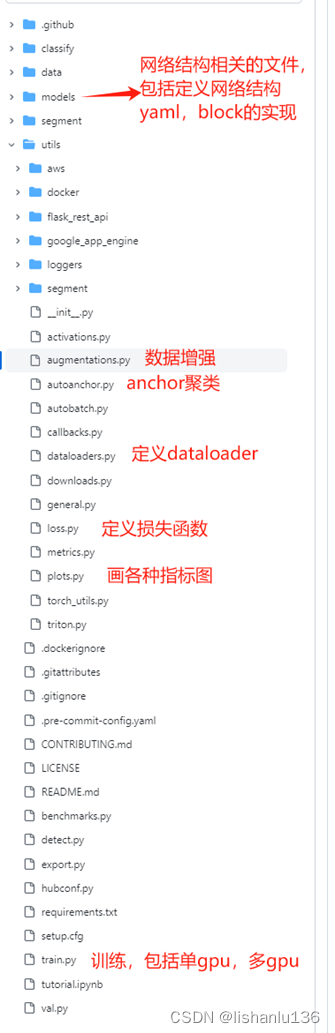
代码结构非常清晰,且文件命名一目了然,通过文件名就知道该文件大致起什么作用。从代码来看,模型结构以YAML文件定义,结构清晰明了。
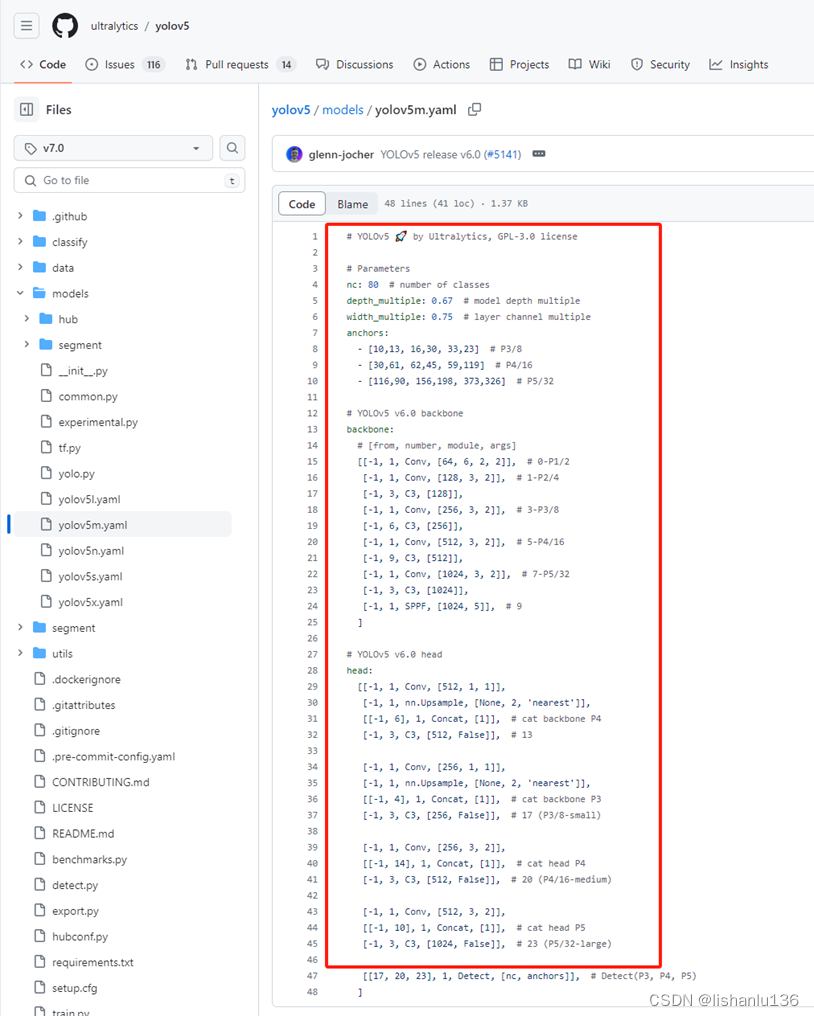
通过yolo.py里的parse_model解析yaml文件加载模型结构:
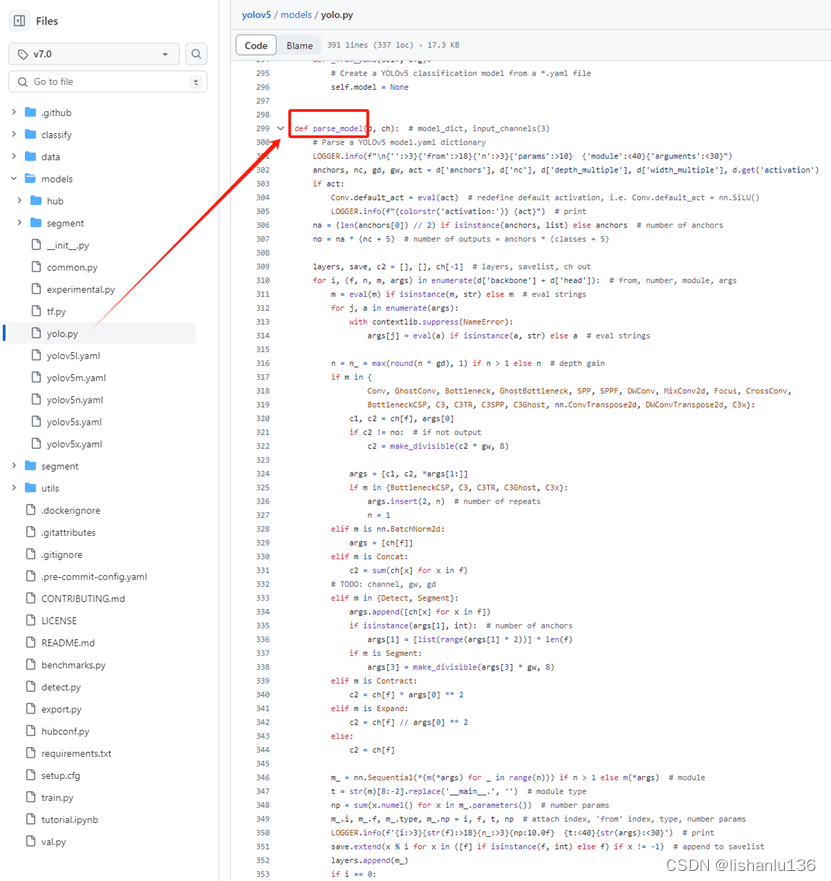
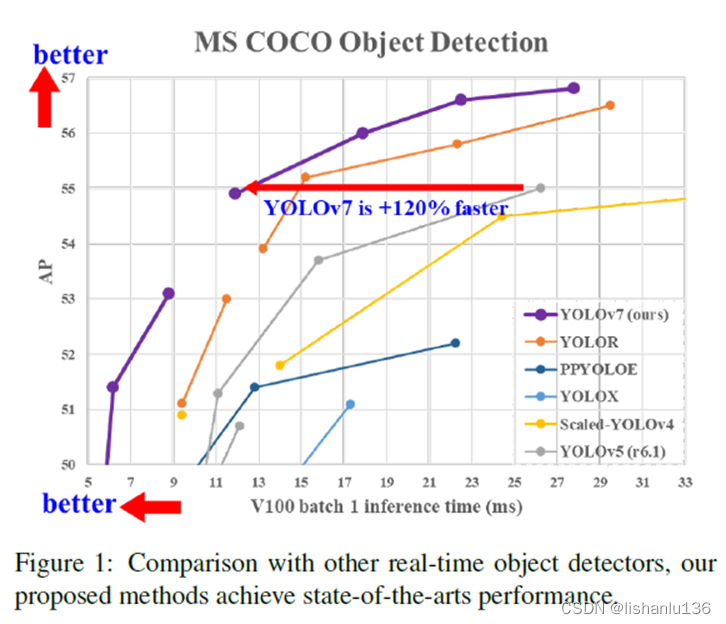
分析完整代码,作者使用了mosaic,图片缩放,focus,CSP,GIoU,FPN+PAN,放缩的网络结构,放缩的网络结构让模型更加灵活,一共有四个版本,s,m,l,x,遗传算法搜超参,自适应的anchor,ema。非常建议大家去深度研读yolov5的代码。
2、YOLOv5细节
先看我自己画的网络结构图
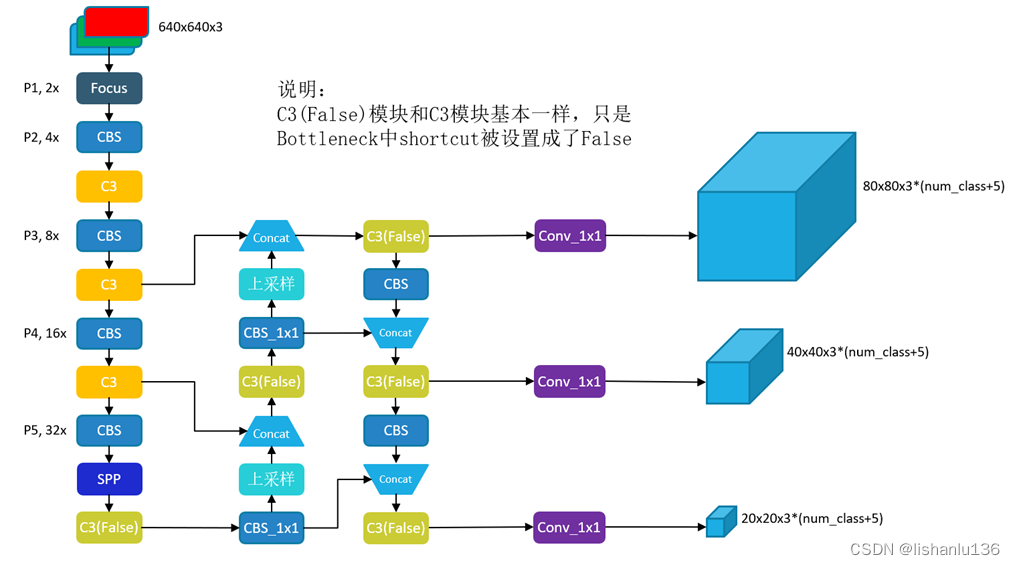
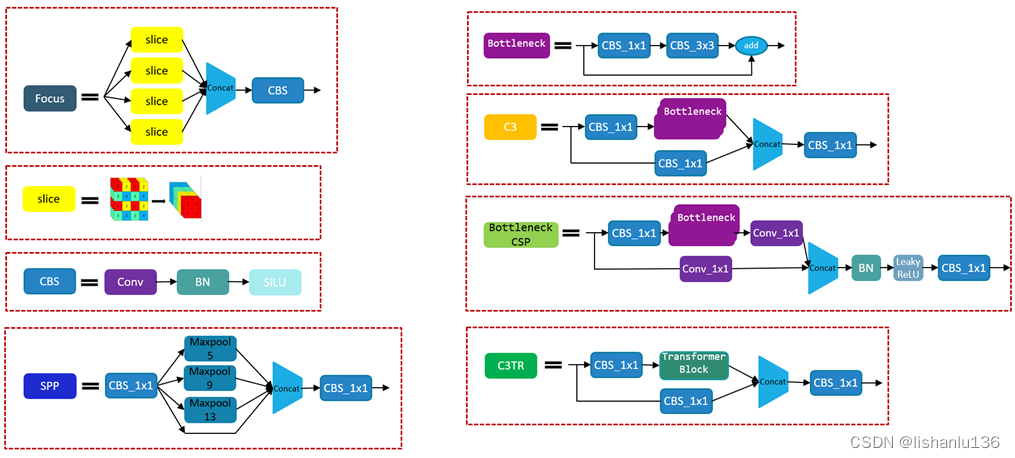
涉及到的子模块结构如下:
2.1 YOLOv5损失函数
yoloV5损失函数包括:
- Classification loss,分类损失
- Localization loss,定位损失(预测边界框与GroundTruth之间的误差)
- Confidence loss,目标置信度损失(框的目标性,objectness of the box)
总的损失函数:classification loss + localization loss + confidence loss
yoloV5使用二元交叉熵损失函数计算类别概率和目标置信度得分的损失。
yoloV5使用CIOU Loss作为bounding box回归的损失。
2.2 YOLOv5边框回归
Yolo格式的txt标记文件格式是归一化后的中心点坐标(x,y)及矩形宽高:


Anchor给出了目标宽高的初始值,需要回归的是目标真实宽高与初始宽高的偏移量;预测边界框中心点相对于对应cell左上角位置的相对偏移量,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,使得预测值在(0,1)范围内,根据边界框预测的4个offset tx,ty,tw,th,可以按照公式计算出边界框的真实预测值。
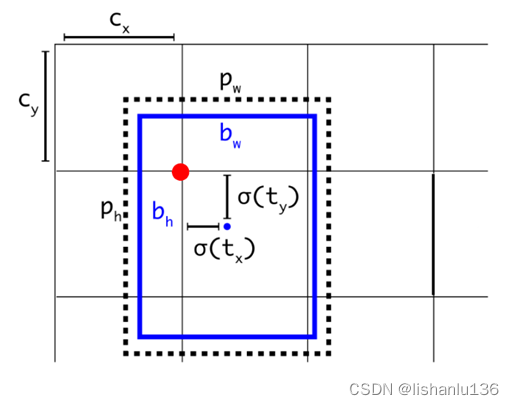
YOLOv2/v3/v4采用相同的方式:
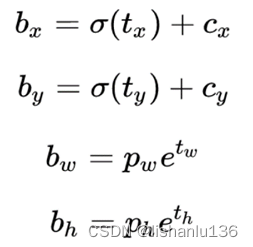
YOLOv5采用跨领域网格匹配策略,一个gt框可以同时在多个尺度特征图上匹配anchor,从而得到更多的正样本anchor,它改进了回归方式:
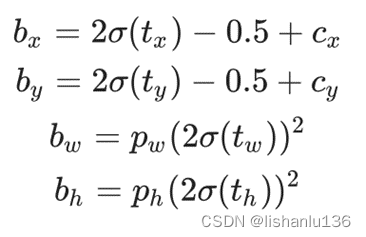
这么改进的原因:
原始的yolo框方程式存在严重缺陷。宽度和高度完全不受限制,因为它们只是out=exp(in),这很危险,因为它可能导致梯度失控、不稳定、NaN损失并最终完全失去训练。
对于yolov5,确保通过sigmoid所有模型输出来修补此错误,同时还要确保中心点保持不变1 = fcn(0),因此模型的标称零输出将导致使用标称锚框大小。当前的方程式将锚点的倍数从最小0限制为最大4,并且锚点-目标匹配也已更新为基于宽度-高度倍数,标称上限阈值超参数为4.0。
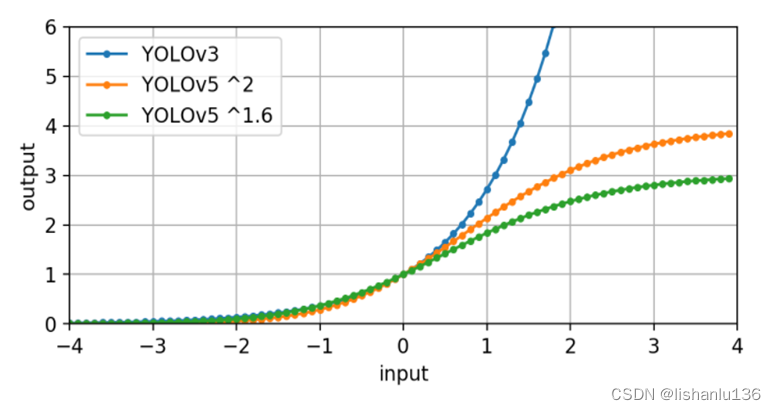
有些groundtruth由于和anchor的匹配度不高,不会参与训练,代码中在数据增强部分有异常标签过滤设置。
2.3 用YOLOv5训练自己的数据
步骤:
- 创建自己的dataset.yaml。
- 创建自己的labels,用labelImg工具,选择yolo格式标注,一张图片保存一个txt文件。背景图片,没有txt文件。
- 改变图片和对应label存放方式;yoloV5是将图片路径中/images/替换成/labels/,自动找图片对应的txt文件的。
- 选择模型,移动端建议选择yoloV5s,yoloV5m;服务器端建议选择yoloV5l,yoloV5x。
- 训练,可以通过指定weights参数加载预训练模型微调。
- 可视化,wandb,Tensorboard,本地训练日志。
2.4 训练技巧
数据库:
- 每个类别的图片数大于1.5K
- 每个类别的标注实例大于10K
- 图片多样性,必须和实际部署环境一致
- 标注一致并准确,图片中有的类别必须标注
- 加入背景图片,可减少FP,建议加入0~10%的背景图片
训练参数设置:
- 第一次训练,建议都采样默认参数,建立一个基准,后面再尝试调整参数对比效果
- Epochs,默认参数300,如果出现过拟合,就减小该值,如果没有出现,可以增大大600甚至更大
- Image size,如果数据库中有更多的小目标,建议使用较大的分辨率训练
- Batch size,尽可能设大一点
- 超参数,建议使用默认值;更大的图像增强参数,会减少过拟合,但会增加训练难度,往往也会得到更好的mAP,减少损失分量权重参数,可以减少该损失分量过拟合机率
参考自:https://docs.ultralytics.com/tutorials/training-tips-best-results/
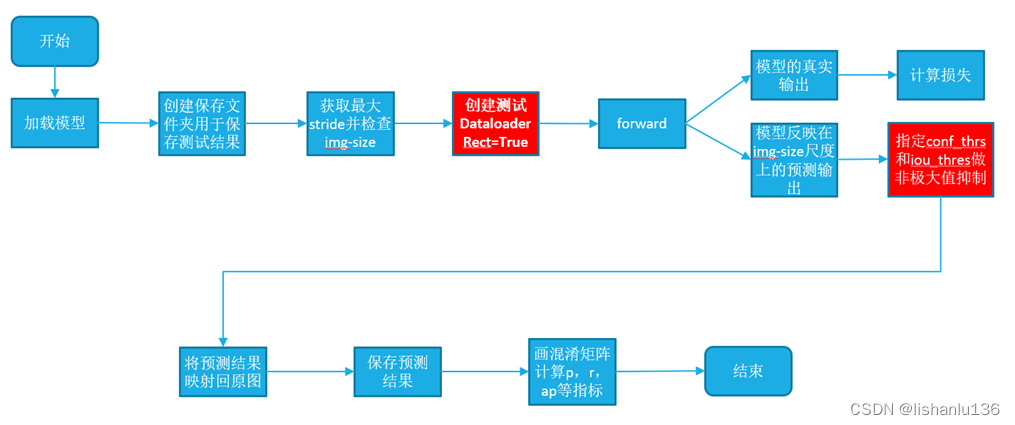
2.5 YOLOv5训练流程
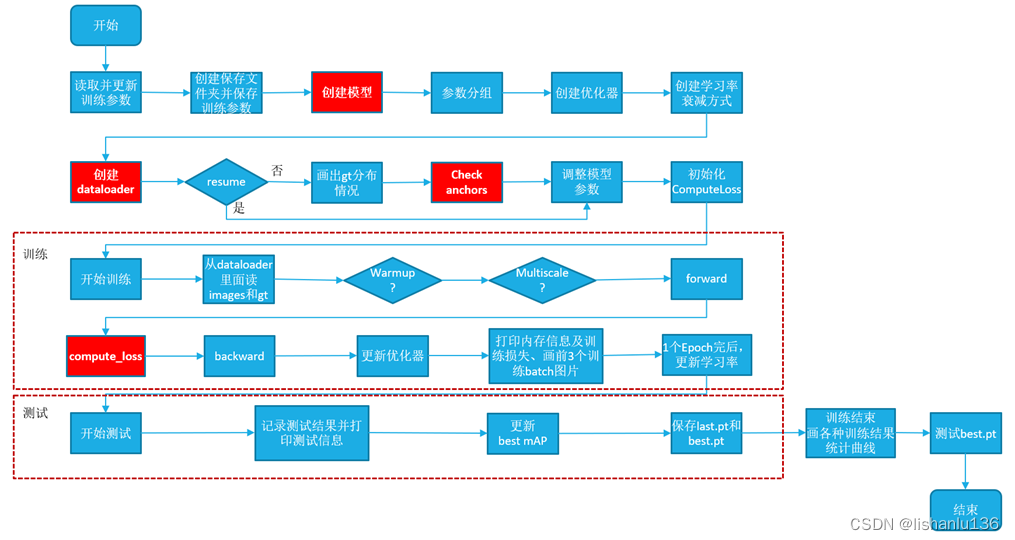
2.6 YOLOv5测试流程