模型融合(Ensemble):尝试将多个模型的预测结果进行融合,可以通过投票、加权平均等方式。这通常可以提高模型的鲁棒性和性能。
自适应学习率调整:使用自适应学习率调整方法,如AdamW中的自适应学习率,可以帮助模型更好地收敛到最优解。
早停策略:在验证集上监控模型性能,当模型性能不再提升时,及早停止训练,以避免过拟合。
模型正则化:在损失函数中加入正则化项,如L1或L2正则化,以减少模型的复杂度,防止过拟合。
更多的训练数据:尝试增加训练数据的数量,可以通过数据增强技术或者收集更多的数据来实现。更多的数据通常可以提高模型的泛化能力。
超参数搜索:使用自动化的超参数搜索工具,如Grid Search或Random Search,来搜索最佳的超参数组合。
模型微调:尝试微调预训练模型,如BERT或GPT,以适应特定任务的需求。
注意力机制:引入注意力机制,如自注意力机制(Self-Attention),以帮助模型更好地捕捉文本序列中的重要信息。
多任务学习:考虑使用多任务学习(Multi-Task Learning)的方法,同时训练多个相关任务,以提高模型的泛化能力。
错误分析:对模型在验证集或测试集上的错误进行分析,找出常见的错误模式,并针对性地调整模型或数据。
迁移学习:考虑使用预训练模型进行迁移学习,将模型在大规模数据上学到的知识迁移到当前任务上,可以有效提高模型性能。
交叉验证:使用交叉验证技术来评估模型的稳定性和泛化能力,确保模型的性能指标可靠。
正负样本均衡:确保训练集中不同类别的样本数量均衡,避免模型对某一类别过度偏向。
特征工程:根据任务的特点,设计更有效的特征表示。对于文本分类任务,可以尝试使用词嵌入技术,并考虑不同的词嵌入模型及其参数设置。


![[集成学习]基于python<span style='color:red;'>的</span>Stacking<span style='color:red;'>分类</span><span style='color:red;'>模型</span><span style='color:red;'>的</span>客户购买意愿<span style='color:red;'>分类</span><span style='color:red;'>预测</span>](https://i-blog.csdnimg.cn/direct/fbdfd8f871f54e8fad2f0f1499b28838.png)























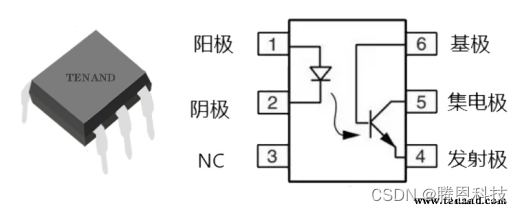






![【洛谷 P8637】[蓝桥杯 2016 省 B] 交换瓶子 题解(贪心算法)](https://img-blog.csdnimg.cn/direct/0d483dc55e1c4327a76cd72b45fe8637.png)