写在最前:
有些网页采用了异步加载的方式,将部分内容放在了其他的URL地址中,导致我们通过审查元素可以在相应的标签找到该内容,但在检查源代码的时候发现没有该内容,自然通过当前的url爬取不到目标数据。
解决方法
找到加载过程中加载的需要动态异步加载的json文件,获取它的URL地址。
以某网站(巨潮资讯网)为例:
网址:
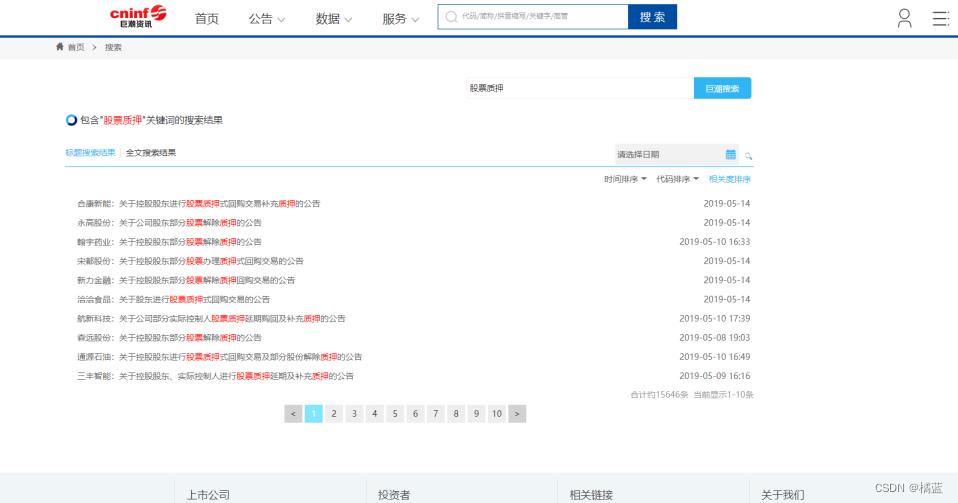
这里我们尝试去爬取搜索结果,发现放置“搜索结果”的这部分网页源代码中看不到。
如何抓取被隐藏的数据?
我们在搜索结果页右键点击检查,进入审查页 ——> 再点击Network选项卡 ——> 点击XHR选项 ——> 然后刷新一下网页。如下图所示:

异步加载的数据在这里,我们点进去看看,切换到perview选项卡,如下图所示:
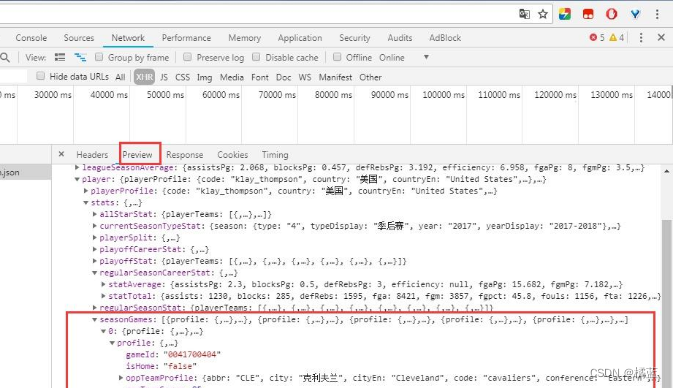
发现在这里能够找到我们所需要的数据。
找到目标网页了,接下来我们切换到headers选项卡,如图所示:
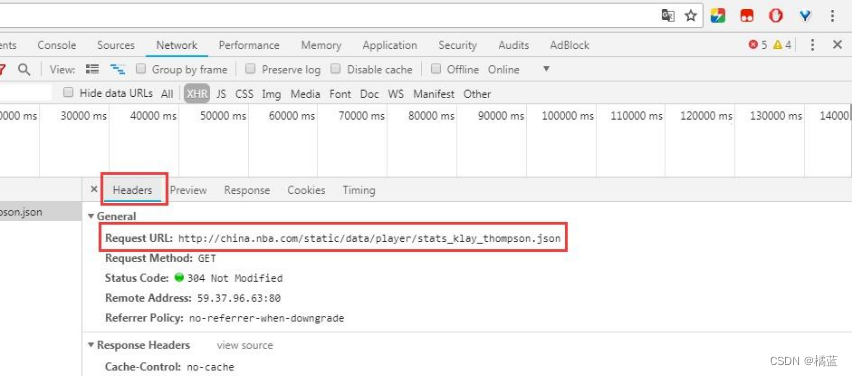
这里的URL才是我们想要的数据的目标地址。你可以复制一下该地址在浏览器中访问一下便可以看到想要的数据在这个地址中。
接下来通过该URL及相应的头文件、cookie信息我们就可以爬取到该内容了。
import requests
url = 'http://china.nba.com/static/data/player/stats_klay_thompson.json'
headers = {
"Cookie": "ssxmod_itna=YqUxgDnie4U7rN/qDWPu5HiDD==; ssxmod_itna2=YqUxgDnief8a00178741cfdf0b1e5e5b62fb156cd2b",
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.232.400 QQBrowser/12.3.5582.400',
}
r = requests.get(url,headers)
print(r.text)
























![[云原生] Prometheus自动服务发现部署](https://img-blog.csdnimg.cn/direct/34f9095d0e91454f90372c485cdf5106.png)