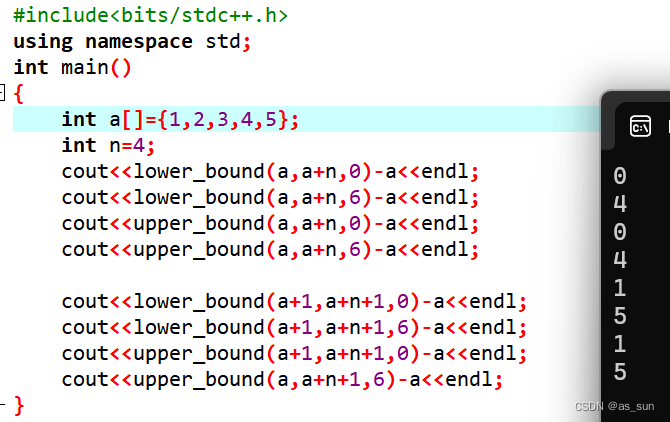
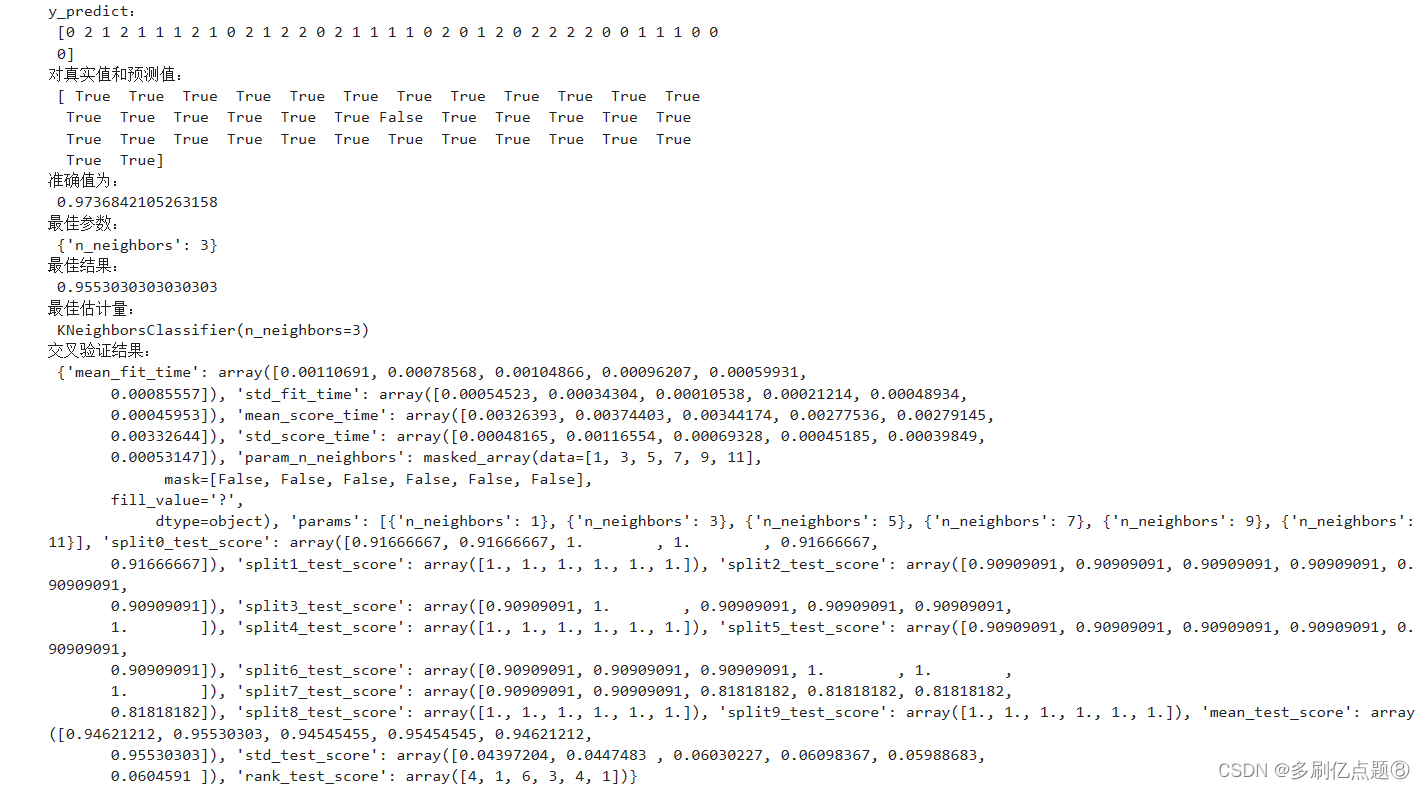
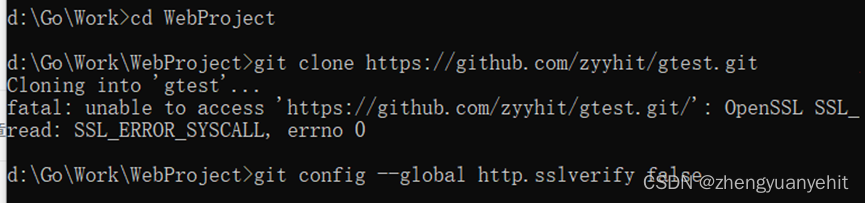
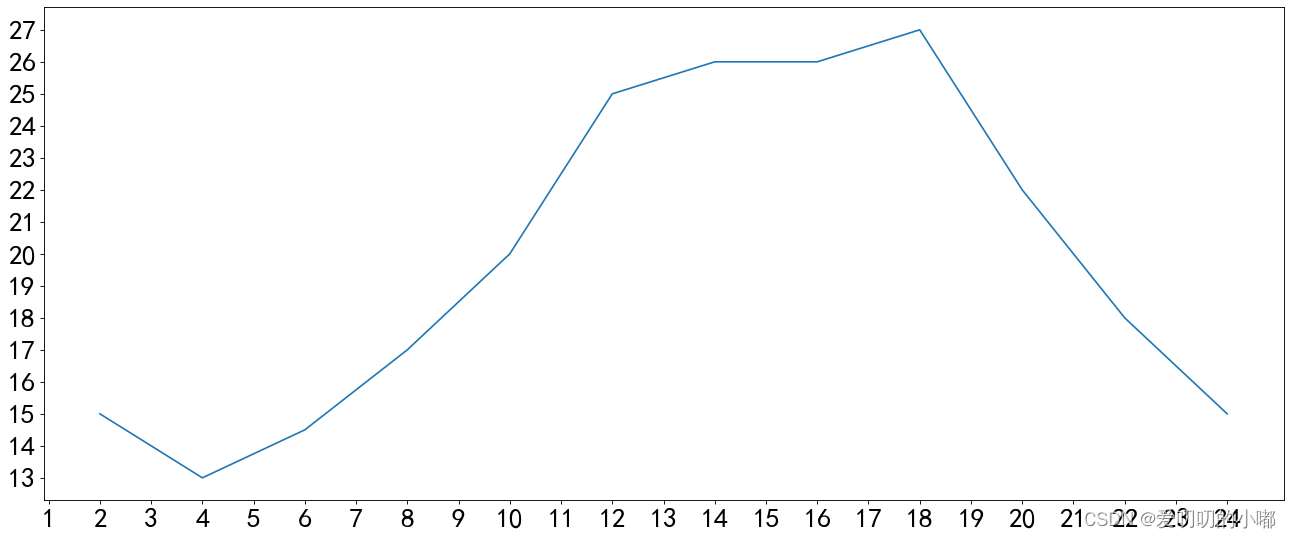
########################################################
/usr/local/lib/python3.10/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
787 raise ValueError(“You have to specify either input_ids or inputs_embeds”)
788
–> 789 batch_size, seq_length = input_shape
790 device = input_ids.device if input_ids is not None else inputs_embeds.device
791
ValueError: too many values to unpack (expected 2)
There are a few possible ways to fix the problem, depending on the desired input format and output shape. Here are some suggestions:
- If the input_ids are supposed to be a single sequence of tokens, then they should have a shape of (batch_size, seq_length), where batch_size is 1 for a single example. In this case, the input_ids should be squeezed or flattened before passing to the model, e.g.:
input_ids = input_ids.squeeze(0) # remove the first dimension if it is 1
# or
input_ids = input_ids.view(-1) # flatten the tensor to a single dimension
- If the input_ids are supposed to be a pair of sequences of tokens, then they should have a shape of (batch_size, 2, seq_length), where batch_size is 1 for a single example and 2 indicates the two sequences. In this case, the input_ids should be split into two tensors along the second dimension and passed as separate arguments to the model, e.g.:
input_ids_1, input_ids_2 = input_ids.split(2, dim=1) # split the tensor into two along the second dimension
input_ids_1 = input_ids_1.squeeze(1) # remove the second dimension if it is 1
input_ids_2 = input_ids_2.squeeze(1) # remove the second dimension if it is 1
# pass the two tensors as separate arguments to the model
output = model(input_ids_1, input_ids_2, ...)
- If the input_ids are supposed to be a batch of sequences of tokens, then they should have a shape of (batch_size, seq_length), where batch_size is the number of examples in the batch. In this case, the input_ids should be passed directly to the model without any modification, e.g.:
output = model(input_ids, ...)