思路参考:【CCF-CSP2020-12期末预测之安全指数 期末预测之最佳阈值】https://www.bilibili.com/video/BV1oH4y1e7da?vd_source=6cf99eba2f23bd7c11379ac940e0bdfb
一.题目分析

1.题目和样例解释
看完题目描述和样例解释,我们不难看出,在每个用例中,其最佳阈值都是y值的集合,我们要做的就是在所有的y值中,找到预测正确次数最多的y;
2.如何计算预测正确的次数
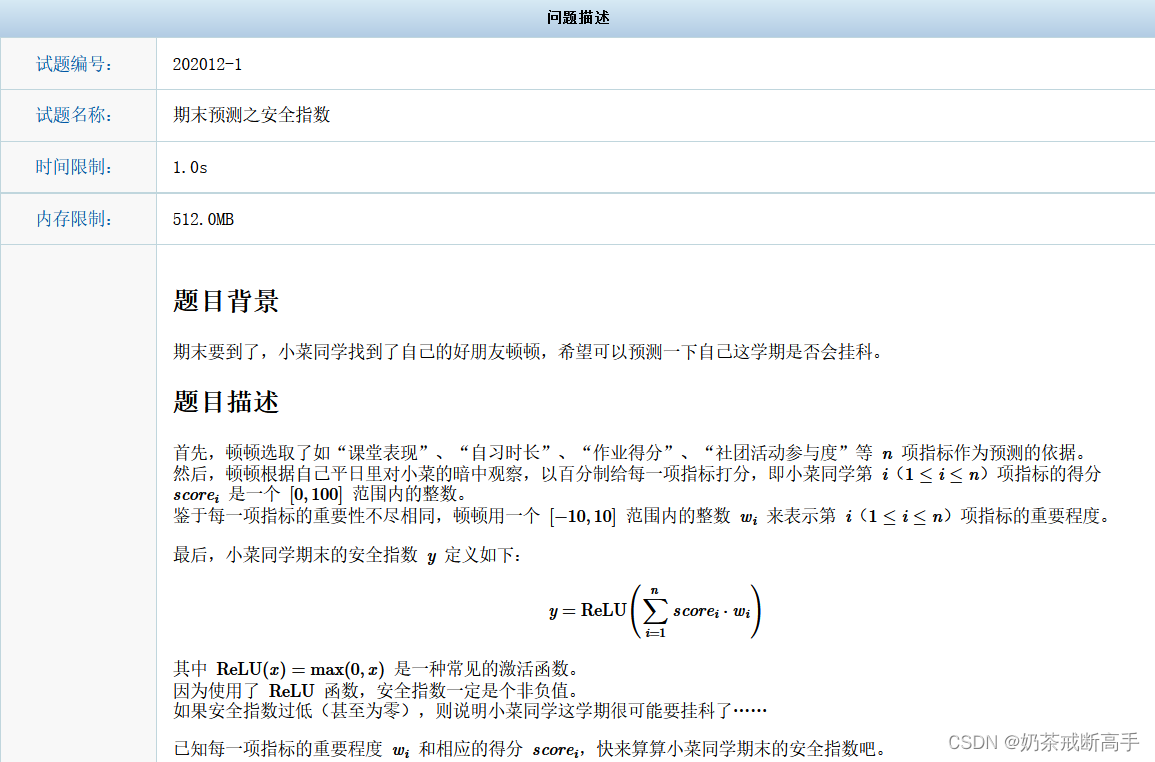
题目中有这样一段话:
即:当y值比阈值大或者相等的时候,result=1;当y值比阈值小的时候,result=0。
3.如何得到最佳阈值

规则有两条:
(1)选择result最大时对应的y;
(2)当出现重复的max(result)时,选y值最大的。
二.代码分析
方法一:100%通过率
1.存储
由于y和result之间是一一对应的,具有捆绑效果,所以我们使用结构体及结构体数组来存储每一次的输入值。
struct stu
{
int y;
int result;
};struct stu* student = new struct stu[m];
for (int i = 0; i < m; i++)
scanf("%d%d", &student[i].y, &student[i].result);2.排序
为什么我们要排序?(这一点我感觉好多博客其实没有说清楚)
一定程度上提高了效率,但这不是排序的本质。这是由我们的算法决定的。请看第三点
3.遍历方法
第一个组数据很特殊,需要全部遍历;
而后的数据,以第三组数据为例,我们其实不需要重新遍历,因为我们是降序排列,所以第三组以上的y值全比第三组的y大或相等,第三组以下的y值全比第三组小或相等。我们先忽略相等的情况,根据“比他小的全是0,比他大的全是1”,我们只需要判断自身是否符合条件就可以(排除第一组,第一组前面没有数据),因为“前人栽树,后人乘凉”,第二组已经替我们判断了它之前的数据是否符合条件,它自身是否符合条件,以及它之后的数据是否符合条件,所以我们只需要判断一下自己就可以了。(换言之:比第二组y值大的,一定比第三组y值大,比第二组数据小的,去除第三组,一定比第三组y值小,所以我们需要判断一下自身就可以)这也变相解释了为什么我们需要排序的问题。
4.统计结果最佳阈值
不难理解:当有重复的y值出现时,我们要取最小的result值。
所以我们不能有一个y值就更新一次count[]数组,(count[]数组是用来统计每个学生y作为阈值时的正确个数)这就是统计时需要注意的。
100%通过率完整代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<iostream>
#include<algorithm>
using namespace std;
struct stu
{
int y;
int result;
};
bool compare(struct stu student1, struct stu student2)
{
return student1.y > student2.y;
}
int main()
{
int m = 0;
scanf("%d", &m);
struct stu* student = new struct stu[m];
for (int i = 0; i < m; i++)
scanf("%d%d", &student[i].y, &student[i].result);
sort(student, student + m, compare);
int* count = new int[m];
//统计每个学生y作为阈值时的正确个数
int out_count = 0;//最佳次数
int out = 0;//最佳阈值
for (int i = 0; i < m; i++)
{
count[i] = 0;
if (i == 0)
{
for (int j = 0; j < m; j++)//判断第一个数据
{
if (student[j].y == student[i].y && student[j].result == 1)
count[i]++;
else if (student[j].y < student[i].y && student[j].result == 0)
count[i]++;
//比它小的全是0,比它大的全是1
}
}
else
{
if (student[i].result == 0)
count[i] = count[i - 1] - 1;
else if (student[i].result == 1)
count[i] = count[i - 1] + 1;
}
if (student[i].y != student[i - 1].y && i != 0 && count[i - 1] > out_count)
{
out_count = count[i - 1];
out = student[i - 1].y;
}
if (i == m - 1 && count[i] > out_count)
{
out_count = count[i];
out = student[i].y;
}
}
printf("%d\n", out);
return 0;
}70%通过率代码:
双层循环全部遍历就可以了
#include<stdio.h>
int main(){
int m,i ,j,max,sum=0;
long int y[200],thta,sumi=0;
int r[200],p=0;
scanf("%d",&m);
while(i<m){
scanf("%ld %d",&y[i],&r[i]);
i++;
}
for (i=0;i<m;i++){
max=0;
thta=y[i];
for(j=0;j<m;j++){
if(y[j]<thta){
p=0;
}else{
p=1;
}
if(r[j]==p){
max ++;
}
}
if(max>sum||max==sum){
sum=max;
sumi=thta;
}
}
printf("%ld", sumi);
return 0;
}