一、算子列表
| 编号 |
名称 |
| 19 |
repartitionAndSortWithinPartitions算子 |
| 20 |
sortBy算子 |
| 21 |
sortByKey算子 |
| 22 |
reparation算子 |
| 23 |
coalesce算子 |
| 24 |
cogroup算子 |
| 25 |
join算子 |
| 26 |
leftOuterJoin算子 |
| 27 |
rightOuterJoin算子 |
| 28 |
fullOuterJoin算子 |
| 29 |
intersection算子 |
| 30 |
subtract算子 |
| 31 |
cartesian算子 |
二、代码示例
package sparkCore
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object basic_transform_03 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("transform").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
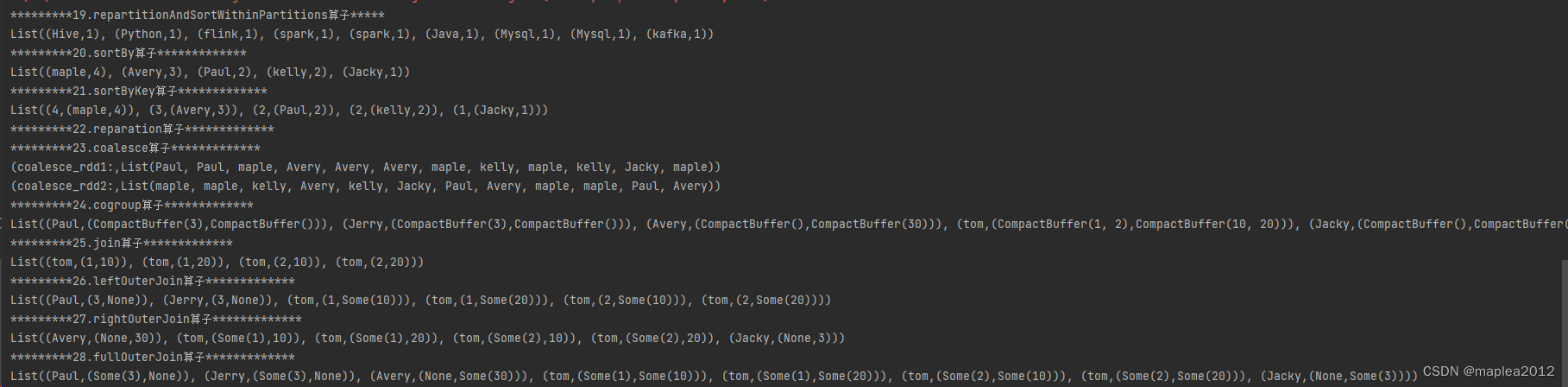
//19.repartitionAndSortWithinPartitions:按照值的分区器进行分区,并且将数据按照指定的规则在分区内排序,底层使用的是ShuffledRDD,设置
// 了指定的分区器和排序规则
println("*********19.repartitionAndSortWithinPartitions算子*****")
val lst1: List[(String, Int)] = List(
("spark", 1), ("spark", 1), ("Hive", 1),
("Mysql", 1), ("Java", 1), ("Python", 1),
("Mysql", 1), ("kafka", 1), ("flink", 1)
)
val rdd19: RDD[(String, Int)] = sc.parallelize(lst1, 4)
val partitioner: HashPartitioner = new HashPartitioner(rdd19.partitions.length)
// rdd19按照指定的分区器进行分区,并且每个分区内的结果按照key(spark,hive等)的字母的字典顺序进行排序
val ReSortwithinPatitioner_rdd: RDD[(String, Int)] = rdd19.repartitionAndSortWithinPartitions(partitioner)
println(ReSortwithinPatitioner_rdd.collect().toList)
//20.sortBy
println("*********20.sortBy算子*************")
val lst2: List[String] = List(
"maple", "maple", "kelly", "Avery",
"kelly", "Jacky", "Paul", "Avery",
"maple", "maple", "Paul", "Avery"
)
val rdd20: RDD[String] = sc.parallelize(lst2)
val words: RDD[String] = rdd20.flatMap(_.split(" "))
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))
val reduced: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
// 根据单词出现的次数,从高到低排序
val sorted_rdd: RDD[(String, Int)] = reduced.sortBy(_._2, false)
println(sorted_rdd.collect().toList)
//21.sortByKey
println("*********21.sortByKey算子*************")
val sortedByKey_rdd: RDD[(Int, (String, Int))] = reduced.map(t => (t._2, t)).sortByKey(false)
println(sortedByKey_rdd.collect().toList)
//22.reparation:功能是重新分区,⼀定会shuffle,即将数据打散.
println("*********22.reparation算子*************")
val rdd22: RDD[String] = sc.parallelize(lst2, 3)
//reparation方法一定会shuffle
// 无论将分区数量变多、变少或不变,都会shuffle
// reparation的底层调⽤的是coalesce,shuffle = true
val rep_rdd: RDD[String] = rdd22.repartition(3)
//23.coalesce:可以shuffle,也可以不shuffle,如果将分区数量减少,并且shuffle = false,就是将分区进⾏合并
println("*********23.coalesce算子*************")
val rdd23: RDD[String] = sc.parallelize(lst2,4)
// 与reparation一样,必然会shuffle和重新分区
val coalesce_rdd1: RDD[String] = rdd23.coalesce(4, true)
println("coalesce_rdd1:",coalesce_rdd1.collect().toList)
//分区减少,且shuffle为false,并不会分区
val coalesce_rdd2: RDD[String] = rdd23.coalesce(2, false)
println("coalesce_rdd2:",coalesce_rdd2.collect().toList)
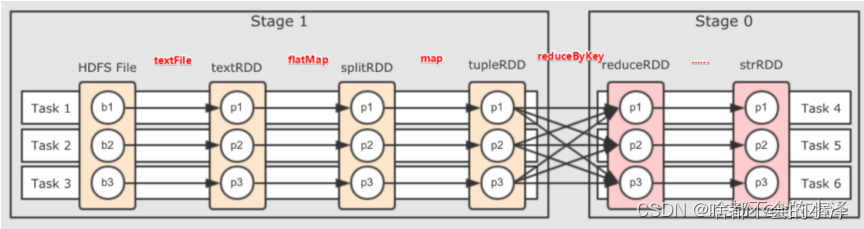
//24.cogroup:使⽤相同的分区器(HashPartitioner),将来⾃多个RDD中的key相同的数据通过⽹络传⼊到同⼀台机器的同⼀个分区中
//注意:两个RDD中对应的数据都必须是对偶元组类型,并且key类型⼀定相同
println("*********24.cogroup算子*************")
val rdd24_1: RDD[(String, Int)] = sc.parallelize(List(("tom", 1), ("tom", 2), ("Jerry", 3), ("Paul", 3)))
val rdd24_2: RDD[(String, Int)] = sc.parallelize(List(("tom", 10), ("tom", 20), ("Jacky", 3), ("Avery", 30)))
val cogroup_rdd: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd24_1.cogroup(rdd24_2)
println(cogroup_rdd.collect().toList)
//25.join:相当于SQL中的内关联join
println("*********25.join算子*************")
val rdd25_1: RDD[(String, Int)] = sc.parallelize(List(("tom", 1), ("tom", 2), ("Jerry", 3), ("Paul", 3)))
val rdd25_2: RDD[(String, Int)] = sc.parallelize(List(("tom", 10), ("tom", 20), ("Jacky", 3), ("Avery", 30)))
val join_rdd: RDD[(String, (Int, Int))] = rdd25_1.join(rdd25_2)
println(join_rdd.collect().toList)
//26.leftOuterJoin:相当于SQL中的左外关联
println("*********26.leftOuterJoin算子*************")
val rdd26_1: RDD[(String, Int)] = sc.parallelize(List(("tom", 1), ("tom", 2), ("Jerry", 3), ("Paul", 3)))
val rdd26_2: RDD[(String, Int)] = sc.parallelize(List(("tom", 10), ("tom", 20), ("Jacky", 3), ("Avery", 30)))
val leftJoin_rdd: RDD[(String, (Int, Option[Int]))] = rdd26_1.leftOuterJoin(rdd26_2)
println(leftJoin_rdd.collect().toList)
//27.rightOuterJoin:相当于SQL中的右外关联
println("*********27.rightOuterJoin算子*************")
val rdd27_1: RDD[(String, Int)] = sc.parallelize(List(("tom", 1), ("tom", 2), ("Jerry", 3), ("Paul", 3)))
val rdd27_2: RDD[(String, Int)] = sc.parallelize(List(("tom", 10), ("tom", 20), ("Jacky", 3), ("Avery", 30)))
val rightJoin_rdd: RDD[(String, (Option[Int], Int))] = rdd27_1.rightOuterJoin(rdd27_2)
println(rightJoin_rdd.collect().toList)
//28.fullOuterJoin:相当于SQL中的全关联
println("*********28.fullOuterJoin算子*************")
val rdd28_1: RDD[(String, Int)] = sc.parallelize(List(("tom", 1), ("tom", 2), ("Jerry", 3), ("Paul", 3)))
val rdd28_2: RDD[(String, Int)] = sc.parallelize(List(("tom", 10), ("tom", 20), ("Jacky", 3), ("Avery", 30)))
val fullOutJoin_rdd: RDD[(String, (Option[Int], Option[Int]))] = rdd28_1.fullOuterJoin(rdd28_2)
println(fullOutJoin_rdd.collect().toList)
//29.intersection:求交集
println("*********29.intersection算子*************")
val rdd29_1: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val rdd29_2: RDD[Int] = sc.parallelize(List(3, 4, 5,6,7))
val rdd29_inter: RDD[Int] = rdd29_1.intersection(rdd29_2)
println("rdd29_inter:", rdd29_inter.collect().toList)
//底层实现使用的是cogroup
val rdd29_11: RDD[(Int, Null)] = rdd29_1.map((_, null))
val rdd29_22: RDD[(Int, Null)] = rdd29_2.map((_, null))
val rdd29_co: RDD[(Int, (Iterable[Null], Iterable[Null]))] = rdd29_11.cogroup(rdd29_22)
//List((1,(CompactBuffer(null),CompactBuffer())), (2,(CompactBuffer(null),CompactBuffer())), (3,(CompactBuffer(null),CompactBuffer(null))), (4,(CompactBuffer(null),CompactBuffer(null))), (5,(CompactBuffer(null),CompactBuffer(null))), (6,(CompactBuffer(),CompactBuffer(null))), (7,(CompactBuffer(),CompactBuffer(null))))
println("rdd29_co:",rdd29_co.collect().toList)
val rdd29_co_inter = rdd29_co.filter(it => it._2._1.nonEmpty & it._2._2.nonEmpty).keys
print("rdd29_co_inter", rdd29_co_inter.collect().toList)
//30.subtract:两个RDD的差集,将第⼀个RDD中的数据,如果在第⼆个RDD中出现了,就从第⼀个RDD中移除
println("*********30.subtract算子*************")
val rdd30_1: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val rdd30_2: RDD[Int] = sc.parallelize(List(3, 4, 5,6,7))
val substract_rdd: RDD[Int] = rdd30_1.subtract(rdd30_2)
println(substract_rdd.collect().toList)
//31.cartesian:笛卡尔积
println("*********31.cartesian算子*************")
val rdd31_1: RDD[String] = sc.parallelize(List("Maple", "Kelly", "Avery"))
val rdd31_2: RDD[String] = sc.parallelize(List("Jerry", "Maple", "Tom"))
val cartesian_rdd: RDD[(String, String)] = rdd31_1.cartesian(rdd31_2)
println(cartesian_rdd.collect().toList)
}
}
 三、部分算子示意图
三、部分算子示意图
1、coalesce算子shuffle参数设置成false

2、cogroup