RCNN系列模型(two-stages、基于区域的)主要包括以下几种,按发布时间排序:
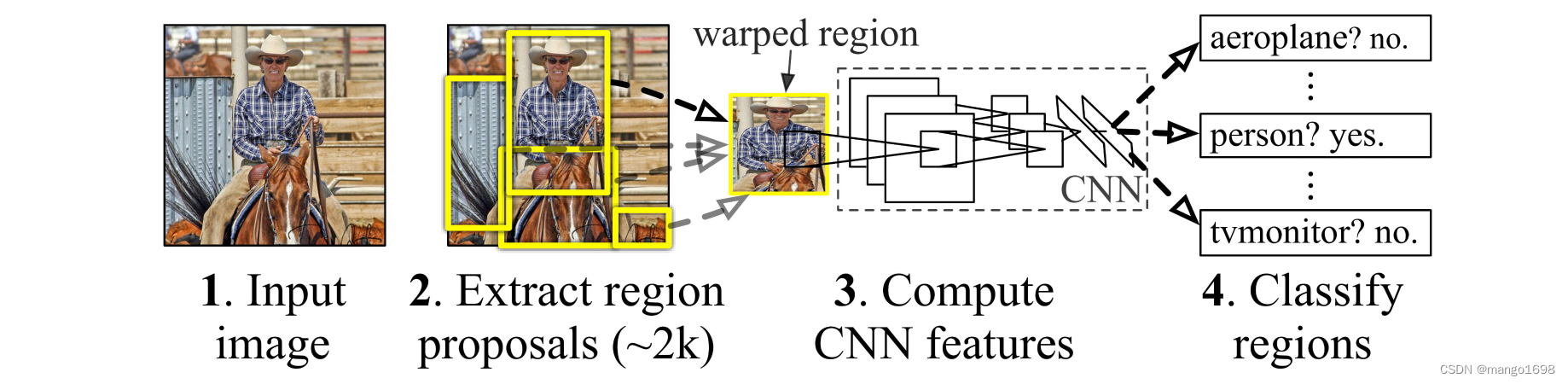
- RCNN(2014年):首次将深度学习应用于目标检测,通过选择性搜索Selective Search提出候选区域,然后使用CNN(AlexNet)进行特征提取,最后通过SVM分类。
- Fast RCNN(2015年):改进了RCNN,引入了ROI Pooling来提取固定大小的区域特征,实现了更快的训练和更高的精度。
- Faster RCNN(2015年末):引入区域提议网络(RPN),使得候选区域的生成也通过深度学习来完成,实现了端到端的训练
- Mask RCNN(2017年):在Faster RCNN的基础上添加了一个并行分支,用于生成高精度的实例分割掩码,同时采用了ROI Align技术提高精度。
RCNN系列框架总结:
- Feature extraction
- Region proposal
- Classification
- Bounding Box Regression

1. RCNN(2014)
1)内容
R-CNN主要分为四个阶段:
- 产生候选区域:对于输入的图片,使用Selective Search方法,选择出2000个候选区域(每个区域大小不一)。
- 特征提取:使用AlexNet对每一个候选区域提取特征,得到2000*4096维的特征向量。
- 候选区域类别判断与NMS:将2000*4096维特征向量送入到21个(20个类别+1个背景)SVM分类器中,需要使用NMS去除冗余的候选框。
- 边界框偏移回归:Bounding Box Regression
2)框架:引入CNN到Feature extraction
- Region proposal (SS)
- Feature extraction (CNN-AlexNet)
- Classification (SVM)
- Bounding Box Regression

3)创新
在文章中,作者认为 R-CNN 较之前的算法,能够取得30%的改进是基于以下两点:
- 使用了CNN来提取候选区域的特征。
- 使用迁移学习,因为目标检测领域的数据相比图像分类任务要少很多,所以使用在图像分类上训练好的模型,经过 fine-tune 可以很好的运用在目标检测上。
4)不足

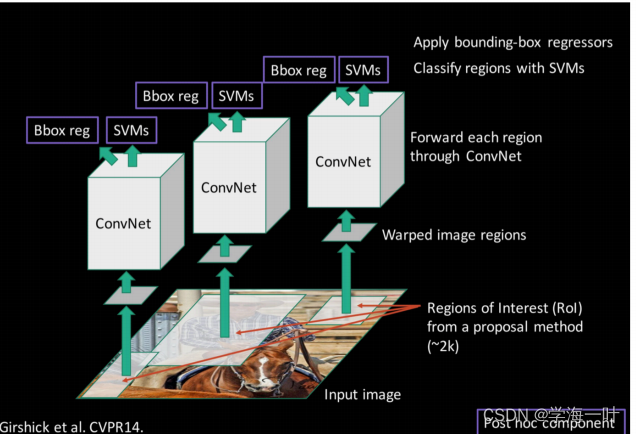
2. Fast R-CNN(2015)
1)内容
Fast R-CNN 主要是在R-CNN和SPPNet的基础上进行改进的,有着以下几个优点:
- 与R-CNN、SPPNet相比,有着更高的准确率。
- 通过使用多任务损失,将模型训练由多阶段转变为单阶段训练。
- 训练时可以一次更新网络的所有层,不再需要分步更新参数。
- 不再需要硬盘来存储CNN提取的特征数据
Fast R-CNN的流程主要分为三步:
- 产生候选框:使用 Selective Search 方法生成2K个图片候选区域proposals;
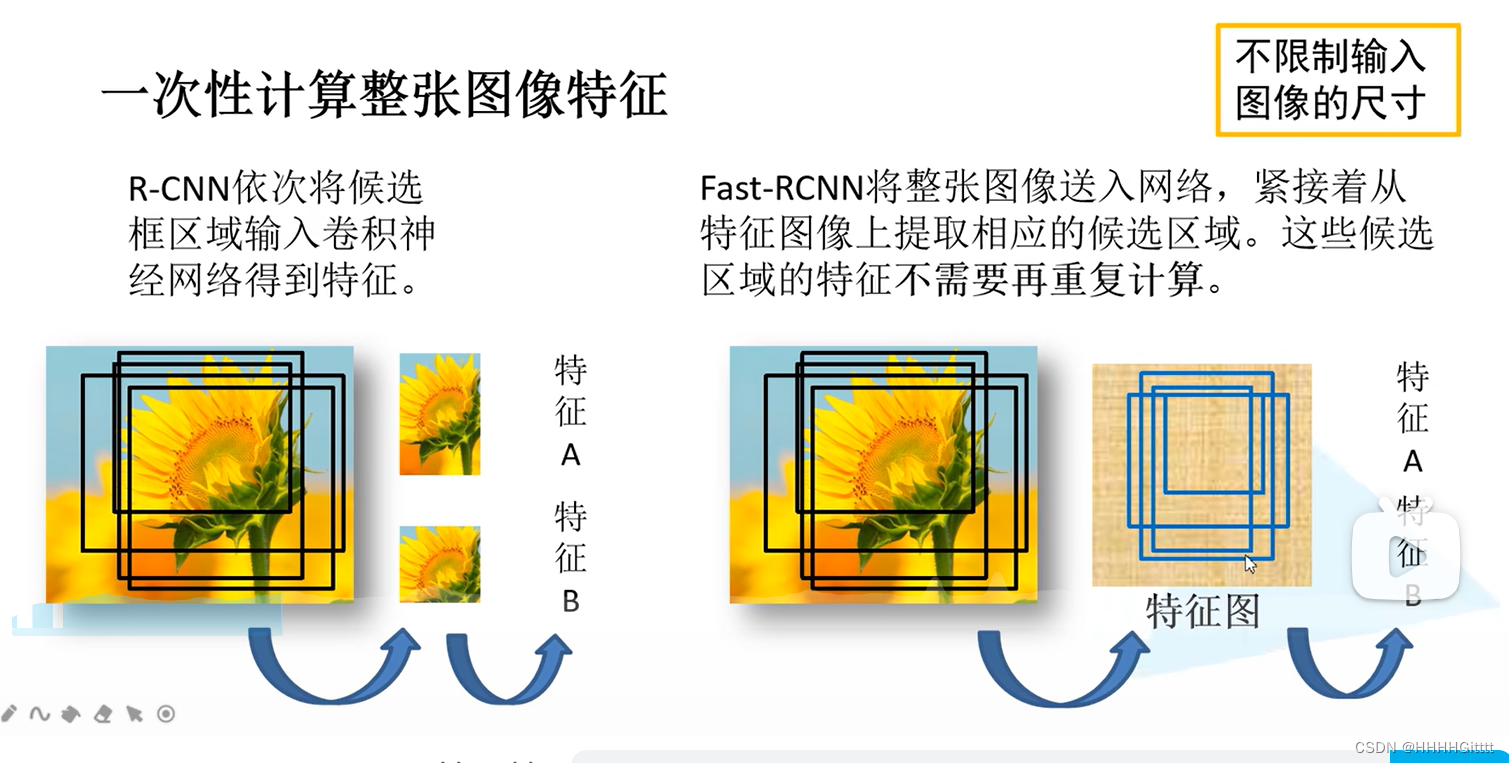
- 特征提取:对整张图片进行特征提取得到相应的特征图(这是对R-CNN的一大改进,参考了SPPNet);
- ROI Pooling:特征投影,并将每一个特征矩阵经过ROI Pooling缩放到7*7大小;---特征投影与统一尺寸
- 类别与边框预测:展平处理后通过全连接层获得预测的分类以及候选区域位置偏移信息。
2)框架
- Region proposal(SS)
- Feature extraction(CNN-VGG)
- RoI pooling
- Classification (CNN)
- Bounding Box Regression(CNN)

3)创新
- 对整张图片进行特征提取得到相应的特征图(这是对R-CNN的一大改进;
- 主要创新:使用了RoI Pooling,这一方法参考了SPPNet的空间金字塔池化;
- 使用了多任务的损失函数来简化R-CNN中的多阶段训练。
4)作者关心
在原文中,作者说Fast RCNN是R-CNN和SPPNet的一个快速更新,所以改进的内容并不是特别多,与后面的Faster RCNN提出了RPN相比,这只能算是一次打补丁的行为。
文中作者更多关心的是一些其它的问题:
- 多任务训练是否有帮助?
- 结论:是的,多任务训练效果比分阶段训练更好。
2. 尺度不变性:暴力方法还是巧妙技巧?
- 人话版:在统一图像特征尺度时,是使用SPPNet的空间金字塔池化还是本文中的ROI池化?
- 结论:两者效果差距微乎其微,甚至空间金字塔池化因为计算开销大,计算所需时间更长。
3. 训练数据是不是越多越好?
- 结论:将训练数据翻倍,可以将mAP提高2%~3%。
4. SVM的表现是否优于softmax?
- 结论:网络直接输出各类概率(softmax),比SVM分类器性能略好
5. 候选区域是不是越多越好?
- 结论:否,候选区域从1K增加到10K的过程中,mAP先有所提升,然后略有下降,而且如果使用更多的候选区域,不仅没有帮助,反而会损害精度。
5)Multi-task Training:
Multi-task Training关键步骤:
- 定义任务:确定你希望模型同时学习的任务(例如,分类和回归)。
- 设计网络:构建一个神经网络,它有能力处理多个任务。通常,这涉及共享一些层来学习通用特征,同时为每个任务提供专用的分支。
- 构建多任务损失函数:为每个任务定义损失函数,然后将这些损失结合起来形成一个总的损失函数。可以为不同任务的损失分配不同的权重来调整它们在训练中的重要性。
- 训练模型:使用包含多个任务损失的总损失函数来训练模型。通过反向传播更新模型参数,使得模型能够同时在所有任务上表现良好。
- 调参和评估:根据模型在各个任务上的表现进行调参,可能需要调整损失权重、网络结构或学习率等。
总结:多任务训练——专用分支 + 包含多个任务损失的总损失(任务损失*对应权重)
6) ROI Pooling:---候选框特征投影&统一尺寸
ROI Pooling(感兴趣区域池化)这一步骤是在RPN生成候选框之后、检测网络之前进行的,它的目的是将RPN生成的不同大小的提议区域转换为固定大小的特征图,以便后续的分类和回归操作可以说ROI Pooling是Faster R-CNN中的一个重要步骤,是连接RPN和后续检测网络的桥梁。
在目标检测中,feature map和anchor的对齐主要通过以下方法实现:ROI Pooling、ROI Align、和ROI Warp。
- ROI Pooling通过分区和最大池化来调整尺寸,可能会引入定位误差。
- ROI Align使用双线性插值来精确采样,改善了对齐精度。
- ROI Warp是一种较少使用的方法,通过应用更复杂的变换来适应特征图和锚点之间的对齐。
总的来说,ROI Align通常被认为是这三种方法中最好的。(mask rcnn 中提出)
3.Faster R-CNN(2015年末)
1)具体内容
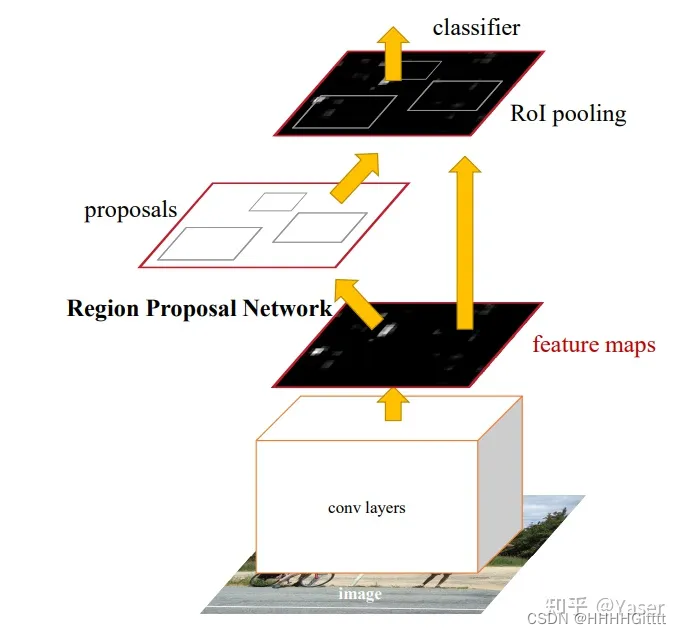
- 特征提取:输入整张图片到特征提取器(VGG16的前30层)中,得到feature maps;
- 产生候选框:将feature maps送入CNN-RPN生成候选框proposals;
- ROI pooling:特征投影,并将每一个特征矩阵经过ROI Pooling缩放到7*7大小;
- 类别与边框预测:展平处理后通过全连接层获得预测的分类以及候选区域位置偏移信息。
2)框架——全CNN:RPN+Fast RCNN
- Feature extraction(CNN-VGG16的前30层)
- Region proposal(CNN-RPN)
- RoI pooling
- Classification (CNN)
- Bounding Box Regression(CNN)

3)RPN(Region Proposal Network)——CNN
出现在Faster RCNN 主干网提取特征之后,检测网络之前。
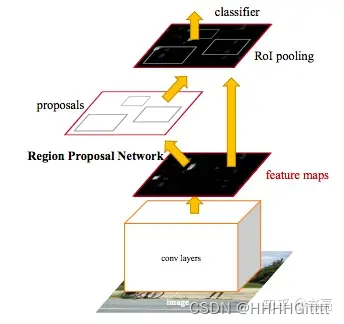
在Faster R-CNN框架中,RPN(区域提议网络)用于生成候选的对象区域,这些区域在使用roi投影和统一尺寸得到区域特征region feature后被送入检测网络进行分类和边界框回归。
目的是为下游检测任务(head task:bbox regression&classification)生成高质量的候选区域proposals。
其中proposals是anchors(x,y,w,l),not features。
RPN结构图:input为整张图片提取特征后的feature maps
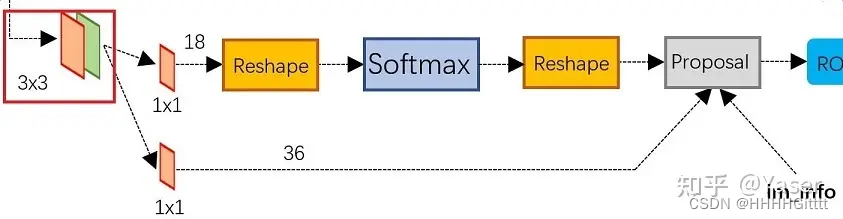
步骤:
- 在特征图上的每个位置(像素值)应用一组预定义的锚框,这些锚框具有不同的尺寸和宽高比;
- 使用一个小型的卷积网络,滑动地扫描卷积特征图上每个位置,对每组每个锚框预测物体存在概率p(背景/前景得分)和位置调整(box偏移);--CNN
- 应用非极大值抑制(NMS)选择最佳候选框。(去掉重复框)
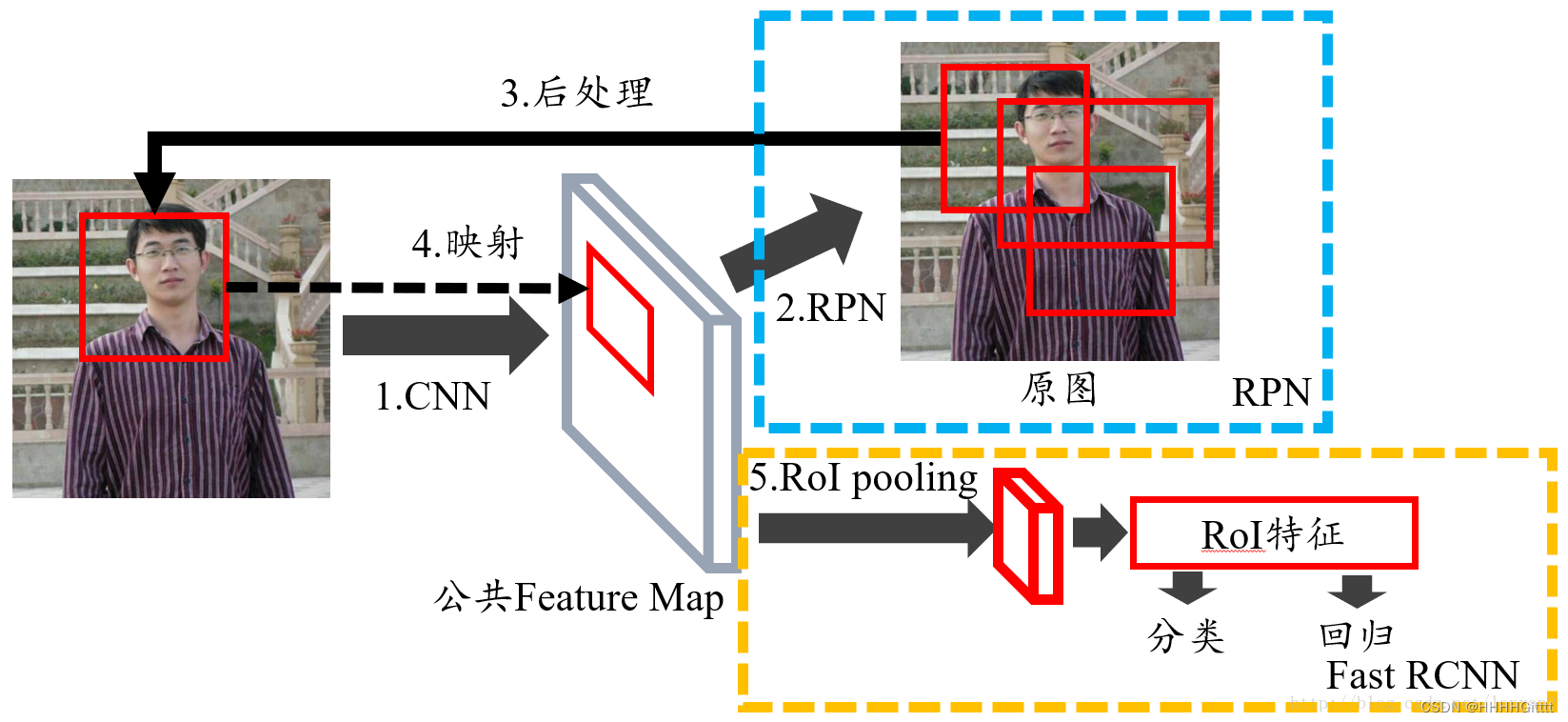
流程:① Input -> CNN -> feature maps
② RPN -> proposals
③ proposals + feature maps -> RoI pooling -> RoI features -> detect head -> class&bbox
总结:RPN用于提取好的候选框,进而定位有效特征,再经过RoI pooling进行特征规范。
4.Mask rcnn(2017)
Mask R-CNN的创新之处主要有两点:首先,引入了一个新的、与现有结构并行的分支,用于对每个感兴趣区域(ROI)生成高质量的分割掩码,实现精确的实例分割;其次,采用了ROI Align方法替代了先前的ROI Pooling,准确地从每个ROI中提取特征,解决了ROI Pooling中的量化误差问题,提高了检测的精度。这些创新使Mask R-CNN在目标检测和实例分割方面取得了显著的性能提升。
5.Sparse rcnn(2021)
Sparse R-CNN与Faster R-CNN是两种目标检测模型,主要区别在于它们处理候选区域的方式。Sparse R-CNN使用稀疏机制,直接学习一组固定数量的候选区域(提议),并通过动态实例交互和权重生成对这些提议进行迭代精化,旨在减少计算量并提高效率。而Faster R-CNN通过区域提议网络(RPN)动态生成候选区域,并使用池化层从这些区域提取特征,然后再进行分类和边界框回归。这导致Sparse R-CNN在设计上更为简洁,且可能在某些情况下提供更高的效率和性能。