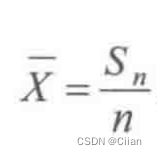第六章 样本及抽样分布
好久没更新了,重新捡起来把它更完吧,可能会再开一个机器学习的笔记系列,参考用书是周志华的西瓜书。前五章主要是概率论,现在开始的后面四章则主要是数理统计。数理统计就是将概率论的知识合理地应用到现实中的随机现象的研究中。
一、随机抽样
在概率论中,我们往往是在已知随机变量的分布的情况下去研究它的数字特征之类的。而在现实中的复杂的随机现象,我们并不能一开始就知道其分布,所以数理统计研究的主要工作就是如何通过对随机变量进行观察统计分析的方法,对其分布做出推断。
所以我们的着眼点不能再是概率分布了,而应该回到更早的随机试验随机变量的概念重新出发。首先数理统计都是研究数的,对于定性描述的随机变量也都可以通过定量化变成数,这一点是毋庸置疑的,但是明确这一点是必要的。
首先是统计分析的几个基本概念,从小学开始学统计,这几个概念也是反反复复接触了。总体:试验中所有的观察值称为总体。个体:总体包含的每个具体的观察值称为个体。容量:总体中包含的个体数量称为容量。容量有限的为有限总体,无限的为无限总体。总体的观察值就是随机变量的取值,总体对应着一个随机变量,数理统计对总体的研究就是对其对应的随机变量的研究。样本:从总体中抽取一部分个体,这些个体就叫样本。在相同条件下对总体进行独立重复的多次观察得到一系列个体就称为简单随机样本,从获取方式可以知道它的性质就是独立同分布。对于无限总体,抽取样本不会影响其分布,所以可以直接采用不放回抽样获取简单随机样本;而有限总体采用放回抽样也能获得简单随机样本,但是操作麻烦,当总体容量远大于样本容量时,可以用不放回抽样来近似放回抽样。
二、直方图与箱线图
2.1 直方图
好家伙,这东西着实没什么可讲,就当个可查阅词典,把直方图的画法过一遍吧
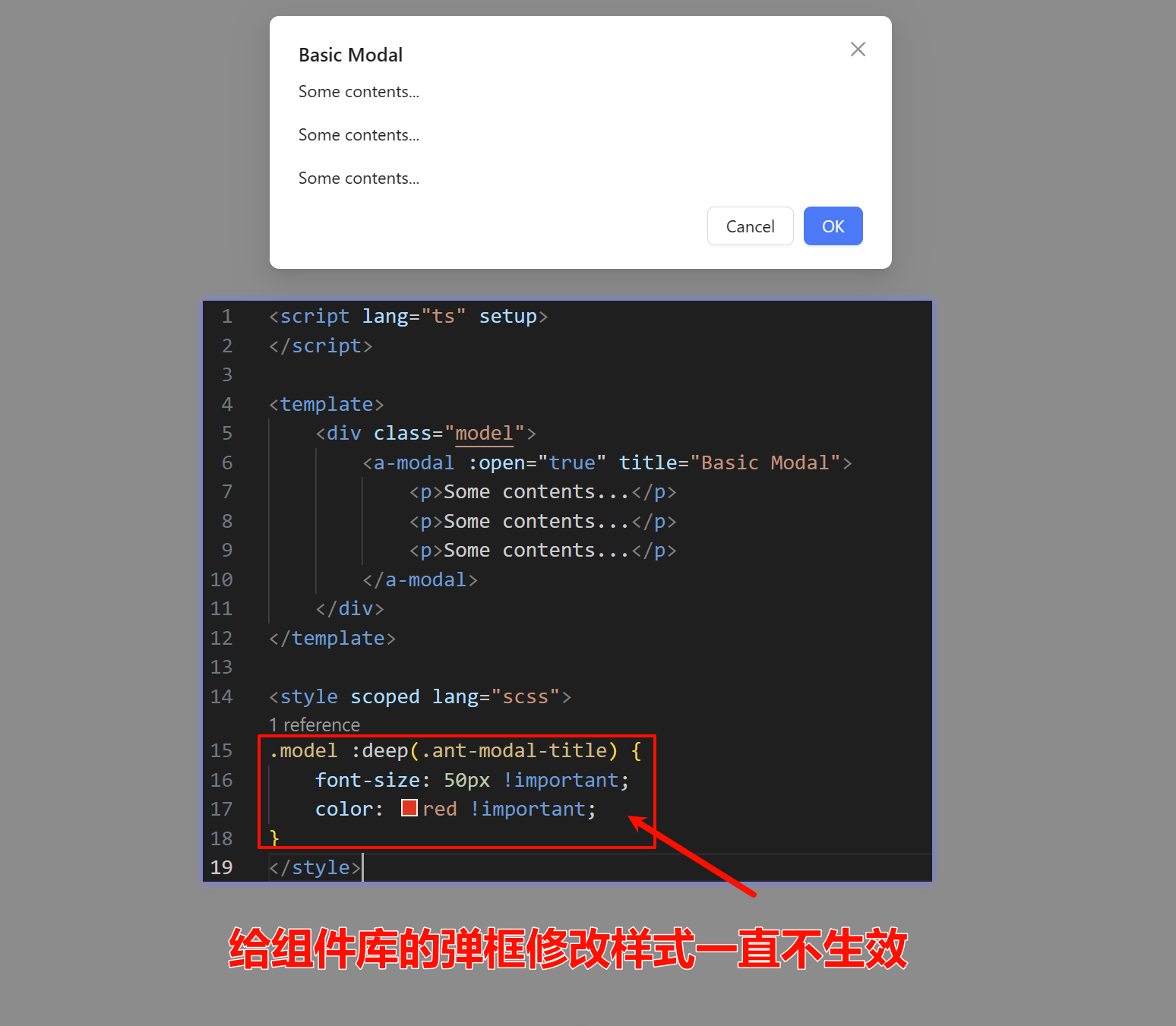
频率直方图是一种描绘样本各个区间数据发生频率的图形。作图之前先对样本做简单统计,得到最大值与最小值,再根据想要划分的区间的多少来确定组距,最后计算落在每个区间内的数据的频率,根据频率与组距的比值作出图像。如下图:

所以频率直方图中矩形的面积才是频率,而不是高度。
2.2 箱线图
样本分位数:样本的p分位数(0<p<1)记为 x p x_p xp,它满足至少有np个观察值小于等于 x p x_p xp,至少有n(1-p)个观察值大于等于 x p x_p xp。
这个概念是不是很熟悉,中位数不就是这里所说的0.5分位数,一般记为 Q 2 Q_2 Q2。常用的分位数还有0.25分位数、0.75分位数,记作 Q 1 , Q 3 Q_1,Q_3 Q1,Q3,称为第一四分位数和第三四分位数。
有了这些,箱线图就出来了,将各个分位数的观察值以及最大最小值标注在数轴上,然后像下图一样画好箱子就行了。箱线图的好处在于,当把两个数据集的箱线图放在一个数轴下时,可以明显的看出来两者的差异。

在数据集中总有一些与众不同的数据,它和其他数据相差甚远,这种数据称为异常值。在箱线图中确定异常值的方法,是看它是否落在区间 ( Q 1 − 1.5 I Q R , Q 3 + 1.5 I Q R ) (Q_1-1.5IQR,Q_3+1.5IQR) (Q1−1.5IQR,Q3+1.5IQR)内,落在区间外就会被认为是异常值,在箱线图中用一个*符号表示即可。其中 I Q R = Q 3 − Q 1 IQR=Q_3-Q_1 IQR=Q3−Q1,称为四分位数间距。
三、抽样分布
统计量:设 X 1 , X 2 , . . . X N X_1,X_2,...X_N X1,X2,...XN是来自总体X的一个样本, g ( X 1 , X 2 , . . . X N ) g(X_1,X_2,...X_N) g(X1,X2,...XN)是样本的函数,若g中不含未知参数,则称其为统计量, g ( x 1 , x 2 , . . . x n ) g(x_1,x_2,...x_n) g(x1,x2,...xn)为其观察值。
常见的统计量有样本平均值,样本方差,标准差,原点矩等等,其定义与之前的随机变量的相关概念的定义的差别就是将期望变成了统计平均。而样本方差有一点不同,其求平均时分母为样本容量n-1,而不是n。这与估计有关,后面会讲。
经验分布函数: S ( x ) = n u m b e r ( X ≤ x ) S(x)=number(X\leq x) S(x)=number(X≤x)为样本中小于x的个体的个数,那么总体X的经验分布函数的定义为: F n ( x ) = S ( x ) n , x ∈ R F_n(x)=\frac{S(x)}{n},x\in R Fn(x)=nS(x),x∈R 其中n为样本容量。
可以看到经验分布函数其实就是用分布函数的定义,将样本中频率作为概率得到的。该经验分布函数被证明当n趋近于无穷大时,是一致收敛于总体的分布函数F(x)的。
统计量是随机变量的函数,所以它也是随机变量,那么也就有其服从的分布,将统计量的分布称为抽样分布。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。