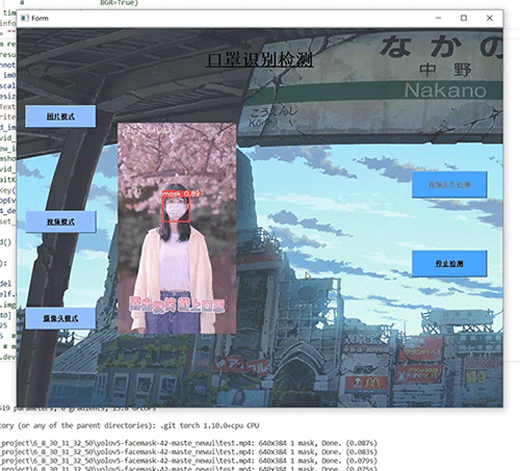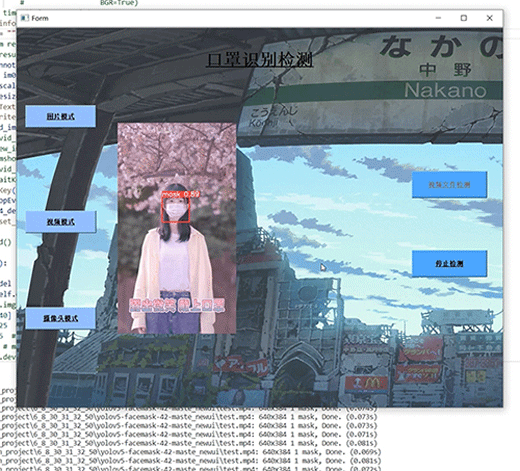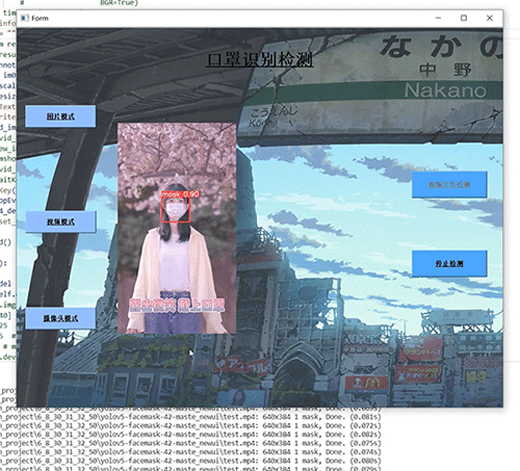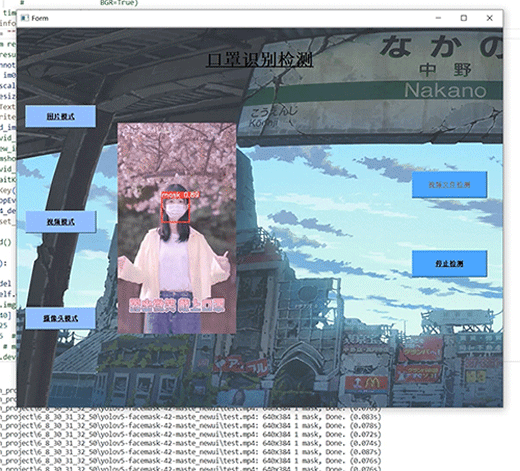
在计算机科学和人工智能领域,特别是在深度学习和自然语言处理(NLP)中,注意力机制(Attention Mechanism)是一种重要的技术,它使模型能够在处理信息时自动地聚焦于重要的部分。注意力机制受到人类注意力的启发,即我们在观察或处理信息时会集中注意力于某些关键部分,而忽略其他不太重要的信息。
注意力机制最早在序列到序列(Seq2Seq)模型中被广泛使用,用于改善机器翻译、文本摘要、语音识别等任务的性能。
它的核心思想是在模型的编码器和解码器之间建立一个动态的权重分配机制,使解码器在生成输出序列的每个步骤时能够“注意”到输入序列中最相关的部分。
基本原理
关键步骤:
- 打分(Scoring):计算一个得分(或相似度度量),以衡量解码器当前状态与编码器各个状态之间的相关性。
- 权重分配(Weighting):使用softmax函数将这些得分转换成概率形式,这些概率代表着各个输入对当前输出的重要性。
- 加权求和(Weighted Sum):根据上述得到的权重,对输入信息进行加权求和,生成一个加权的表示,这个表示被送入解码器,用于生成输出。
多种变体形式
- 软注意力(Soft Attention):权重是连续的,并且是通过可微分的操作(如softmax)计算得到的,这允许使用反向传播算法进行训练。
- 硬注意力(Hard Attention):权重是离散的,通常是通过随机采样或其他非可微分的方法选择输入的一部分。硬注意力的训练通常需要采用强化学习或者其他策略。
- 自注意力(Self-Attention)或内部注意力(Intra-Attention):允许序列中的元素直接相互“注意”对方,而不是仅仅依赖于编码器的上下文。这种机制是Transformer模型的核心组成部分,极大地推动了NLP领域的发展。
编码器与解码器
编码器:编码器的任务是接收输入序列,并将其转换成一个固定长度的内部表示(通常称为上下文向量或状态向量)。这个内部表示试图捕获输入序列中的关键信息。在循环神经网络(RNN)或长短期记忆网络(LSTM)、门控循环单元(GRU)等模型中,编码器逐步读取输入序列的元素,更新其内部状态。在Transformer模型中,编码器通过自注意力机制并行处理整个序列。
解码器:解码器的任务是接收编码器生成的内部表示,并基于这个表示生成输出序列。在生成每个输出元素时,解码器会考虑当前的内部状态(即考虑到目前为止已经生成的输出)和编码器的上下文向量。解码器逐步生成输出序列的元素,直到达到序列结束的标志。在RNN、LSTM或GRU等模型中,解码器在每个时间步更新其状态,并生成一个输出元素。在Transformer模型中,解码器同样利用自注意力机制和编码器到解码器的注意力机制来生成输出序列。





























![306_C++_QT_创建多个tag页面,使用QMdiArea容器控件,每个页面都是一个新的表格[或者其他]页面](https://img-blog.csdnimg.cn/direct/c240cfeb26144541893de61c2f797eff.png)