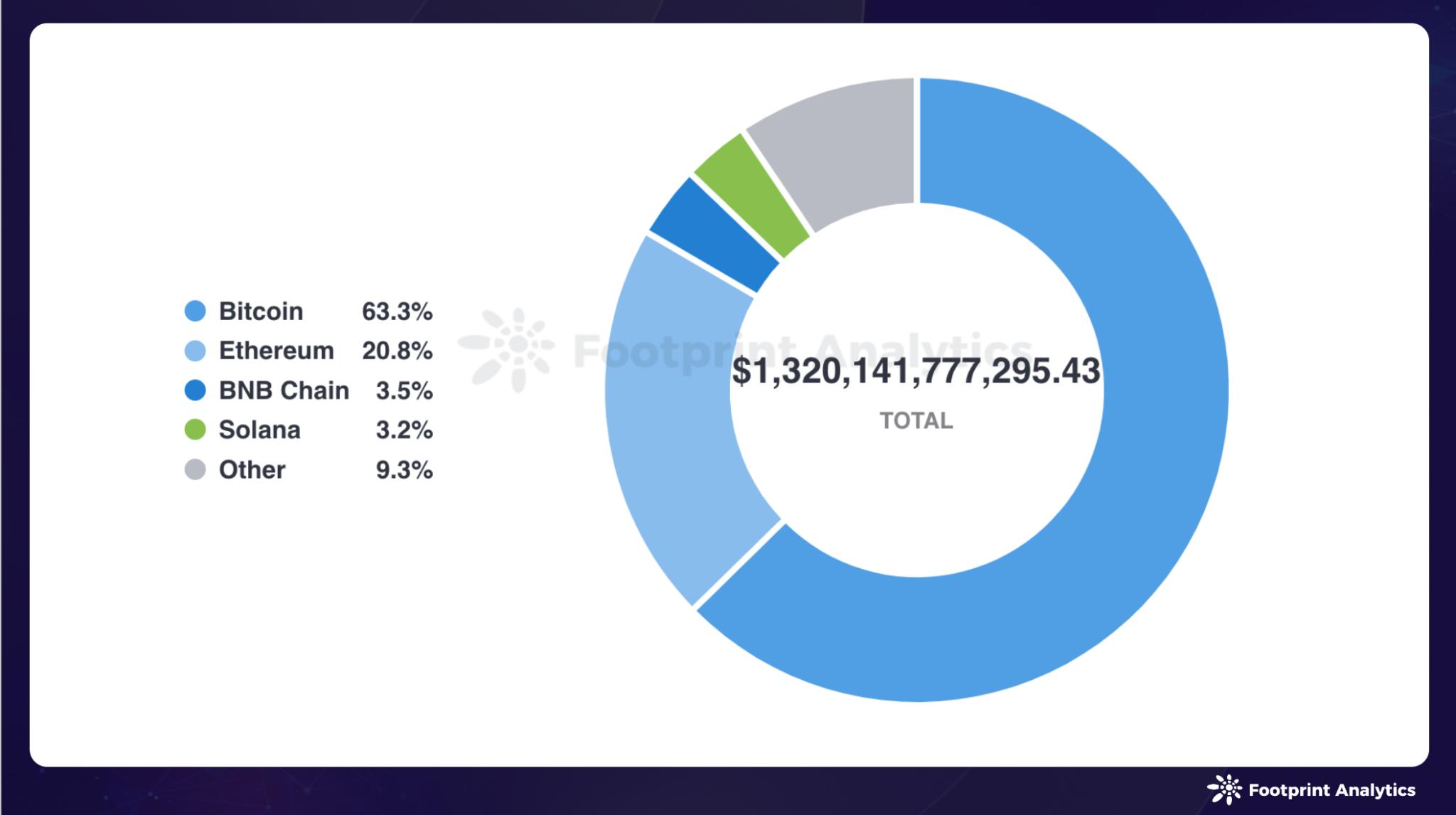
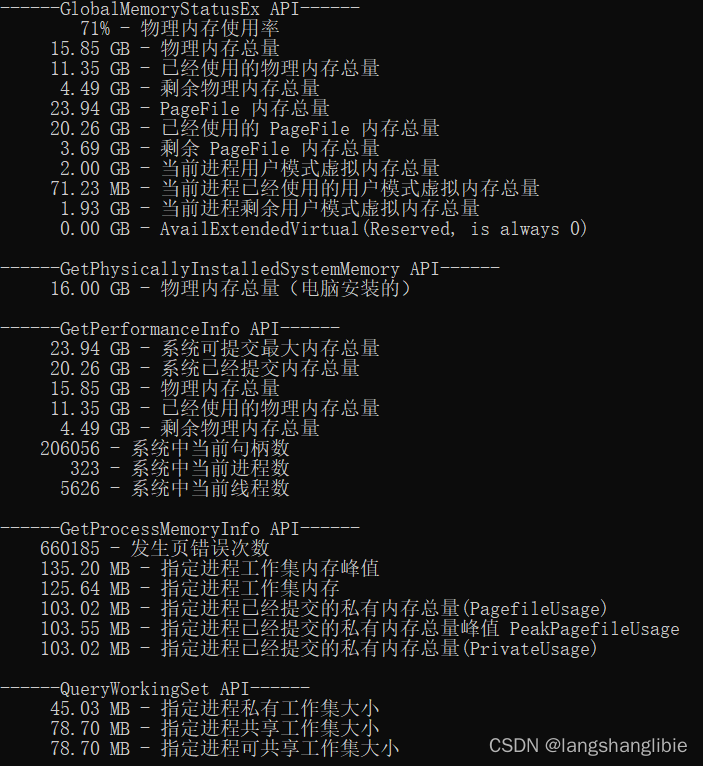
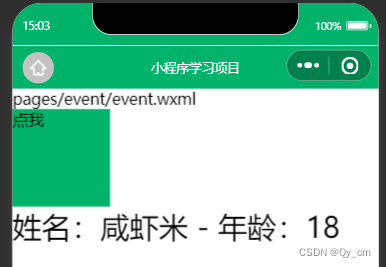
在这个项目中,我的目标是从科学论文图片中提取某些部分(标题、作者和摘要)。预期提取部分是科学论文中常见的部分,例如标题、摘要和作者。输入与最终结果。我的输入是将第一页纸转换成图像。最终结果是一个 txt 文件,其中包含标题、作者和摘要部分,如下图1和图2所示。我将使用 UNet 来了解在哪里可以找到这些部分,然后将训练学到的信息传递到 OCR 中。完整的项目可以在这里找到。

图1 要提取的论文首页(图片格式)

图2 提取得到的论文标题、作者和摘要
步骤说明
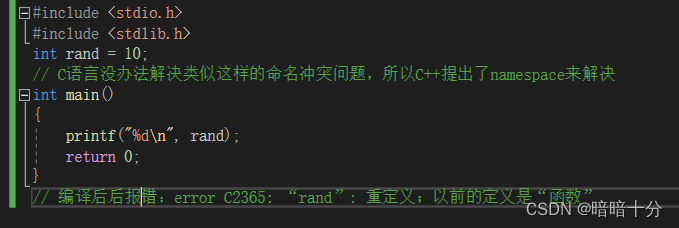
我从数据收集和科学论文开始。由于我只对标题、摘要和作者这三个部分感兴趣,所以我选择了多篇论文中的第一页。然后我将其转换pdf为图像,因为我的 UNet 模型只接受图像。我已将数据集分别按 80/20 分为训练集和测试集。接下来,我编写了一个 python 脚本mask.py来屏蔽图像。参见下图。

图3:右侧是科学论文的原始首页,左侧是相应论文的mask.py结果。
蒙版图像是一维图像,其中每个像素的值为 0(黑色)和 1(白色)。 0表示该像素不重要,1表示该像素重要。左侧图像的白色区域掩盖了重要的标题、摘要和作者部分。
我们将此掩模和原始图像传递给我们的 UNet 模型进行训练。 UNet 是一种流行的架构。您可以找到该架构的许多实现。我推荐Milesial的架构。如果您已经克隆了dagshub存储库,则无需克隆此存储库。您可以通过将工作目录更改为Unet-OCR/Pytorch-UNet然后运行来构建模型,train.py如下所示:
python train.py --epoch 6 --batch-size 1 --learning-rate 0.000001
显然您可以设置自己的参数。当然您也可以使用预训练模型MODEL.pth,您将在运行时获得:
dvc pull -r origin
确保按照下面的安装说明将 DVC 源设置为我的
![[晓理紫]每日<span style='color:red;'>论文</span>分享(有中文<span style='color:red;'>摘要</span>,<span style='color:red;'>源</span><span style='color:red;'>码</span>或项目地址)--强化<span style='color:red;'>学习</span>、模仿<span style='color:red;'>学习</span>、<span style='color:red;'>机器人</span>](https://img-blog.csdnimg.cn/direct/6389642cc7c84e53925a0718a073ba4c.jpeg#pic_center)
![[晓理紫]每日<span style='color:red;'>论文</span>分享(有中文<span style='color:red;'>摘要</span>,<span style='color:red;'>源</span><span style='color:red;'>码</span>或项目地址)--强化<span style='color:red;'>学习</span>、模仿<span style='color:red;'>学习</span>、<span style='color:red;'>机器人</span>](https://img-blog.csdnimg.cn/direct/0ef7f25422864da9b0db8d8dcf53c187.jpeg#pic_center)
![[晓理紫]每日<span style='color:red;'>论文</span>分享(有中文<span style='color:red;'>摘要</span>,<span style='color:red;'>源</span><span style='color:red;'>码</span>或项目地址)--<span style='color:red;'>机器人</span>、强化<span style='color:red;'>学习</span>、开放词汇](https://img-blog.csdnimg.cn/direct/2891925cb1cb4a3f8329d8a5f915189c.jpeg#pic_center)
![[晓理紫]每日<span style='color:red;'>论文</span>分享(有中文<span style='color:red;'>摘要</span>,<span style='color:red;'>源</span><span style='color:red;'>码</span>或项目地址)-<span style='color:red;'>机器人</span>、强化<span style='color:red;'>学习</span>](https://img-blog.csdnimg.cn/direct/fe0cfeb3bff645fbb18503bfd70d6b28.jpeg#pic_center)
![[晓理紫]每日<span style='color:red;'>论文</span>分享(有中文<span style='color:red;'>摘要</span>,<span style='color:red;'>源</span><span style='color:red;'>码</span>或项目地址)--强化<span style='color:red;'>学习</span>、<span style='color:red;'>机器人</span>等](https://img-blog.csdnimg.cn/direct/f6f124fc6bcb4fd995a26bf05958b098.jpeg#pic_center)
![[晓理紫]每日<span style='color:red;'>论文</span>分享(有中文<span style='color:red;'>摘要</span>,<span style='color:red;'>源</span><span style='color:red;'>码</span>或项目地址)--强化<span style='color:red;'>学习</span>、模仿<span style='color:red;'>学习</span>、<span style='color:red;'>机器人</span>、开放词汇](https://img-blog.csdnimg.cn/direct/ebec921a860f447eb4a230522e1bf577.jpeg#pic_center)