output signed [AWIDTH+BWIDTH:0] pr, pi
);
reg signed [AWIDTH-1:0] ai_d, ai_dd, ai_ddd, ai_dddd ;
reg signed [AWIDTH-1:0] ar_d, ar_dd, ar_ddd, ar_dddd ;
reg signed [BWIDTH-1:0] bi_d, bi_dd, bi_ddd, br_d, br_dd, br_ddd ;
reg signed [AWIDTH:0] addcommon ;
reg signed [BWIDTH:0] addr, addi ;
reg signed [AWIDTH+BWIDTH:0] mult0, multr, multi, pr_int, pi_int ;
reg signed [AWIDTH+BWIDTH:0] common, commonr1, commonr2 ;
always @(posedge clk)
begin
ar_d <= ar;
ar_dd <= ar_d;
ai_d <= ai;
ai_dd <= ai_d;
br_d <= br;
br_dd <= br_d;
br_ddd <= br_dd;
bi_d <= bi;
bi_dd <= bi_d;
bi_ddd <= bi_dd;
end
// Common factor (ar ai) x bi, shared for the calculations of the real and
imaginary final products
//
always @(posedge clk)
begin
addcommon <= ar_d - ai_d;
mult0 <= addcommon * bi_dd;
common <= mult0;
end
// Real product
//
always @(posedge clk)
begin
ar_ddd <= ar_dd;
ar_dddd <= ar_ddd;
addr <= br_ddd - bi_ddd;
multr <= addr * ar_dddd;
commonr1 <= common;
pr_int <= multr + commonr1;
end
// Imaginary product
//
always @(posedge clk)
begin
ai_ddd <= ai_dd;
ai_dddd <= ai_ddd;
addi <= br_ddd + bi_ddd;
multi <= addi * ai_dddd;
commonr2 <= common;
pi_int <= multi + commonr2;
end
assign pr = pr_int;
assign pi = pi_int;
endmodule // cmult
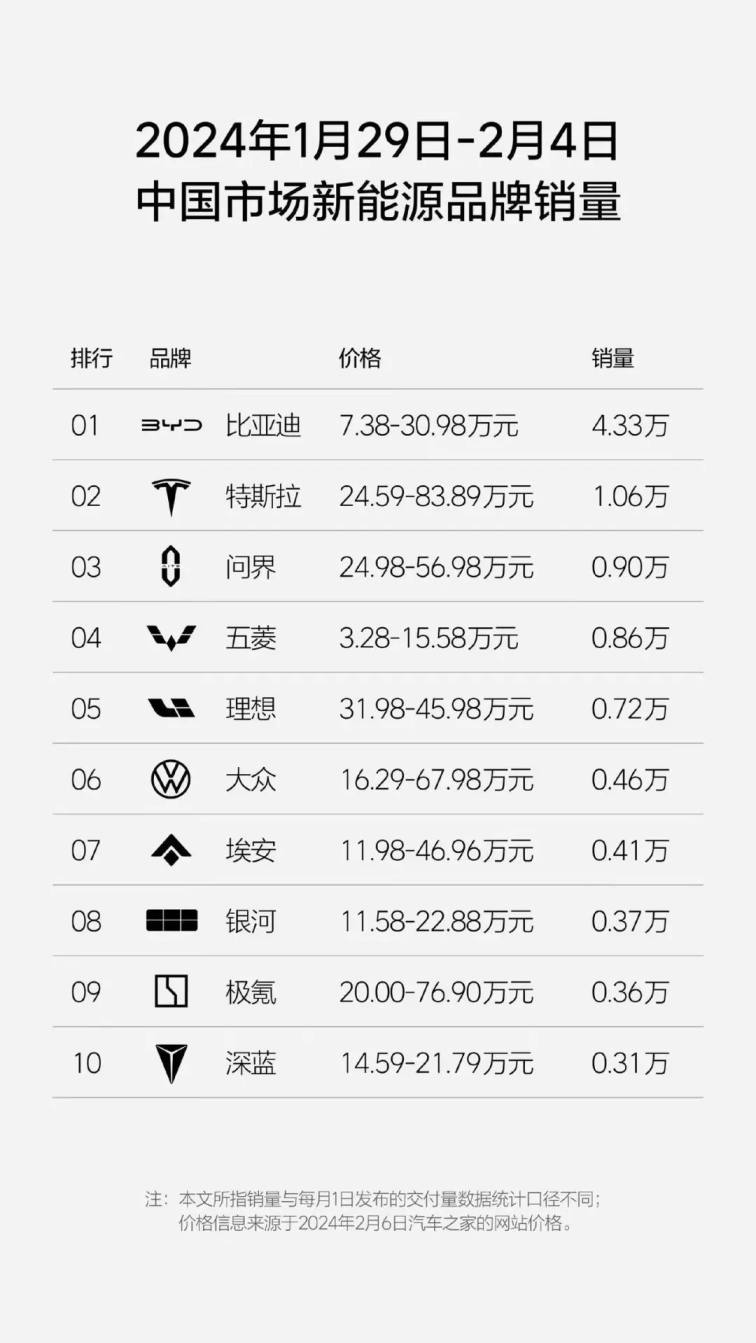
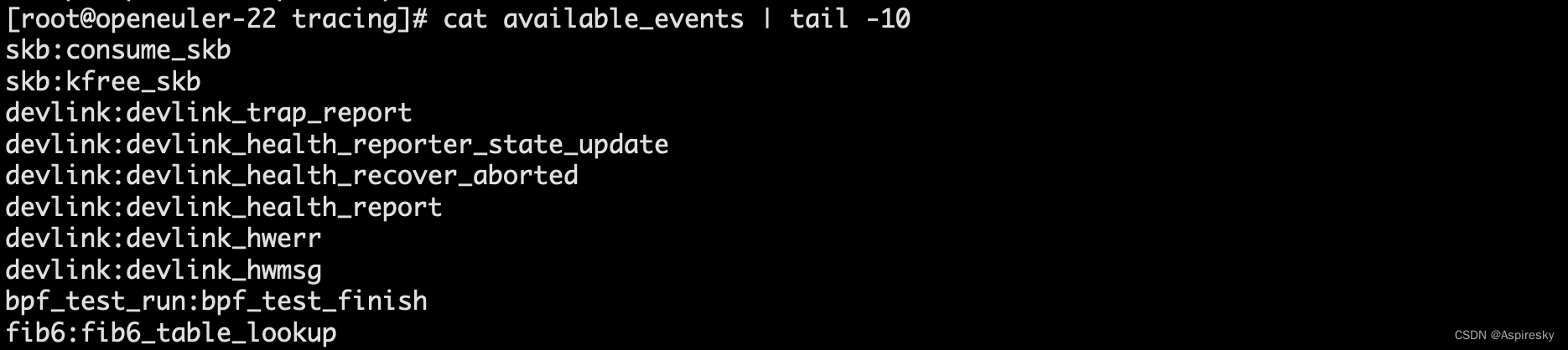
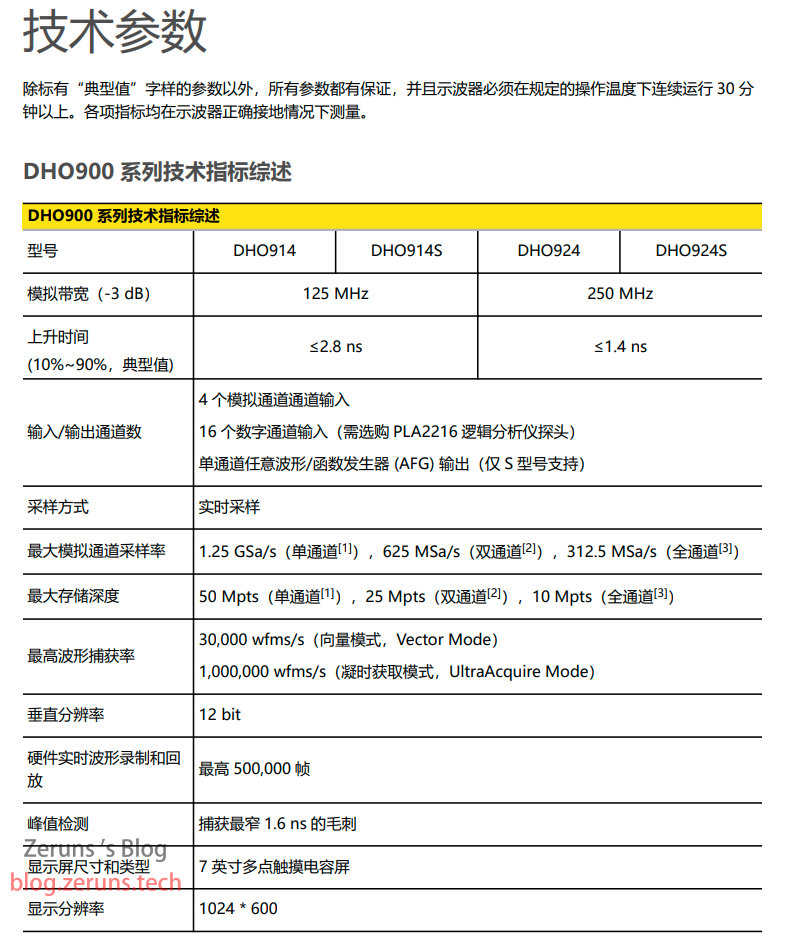
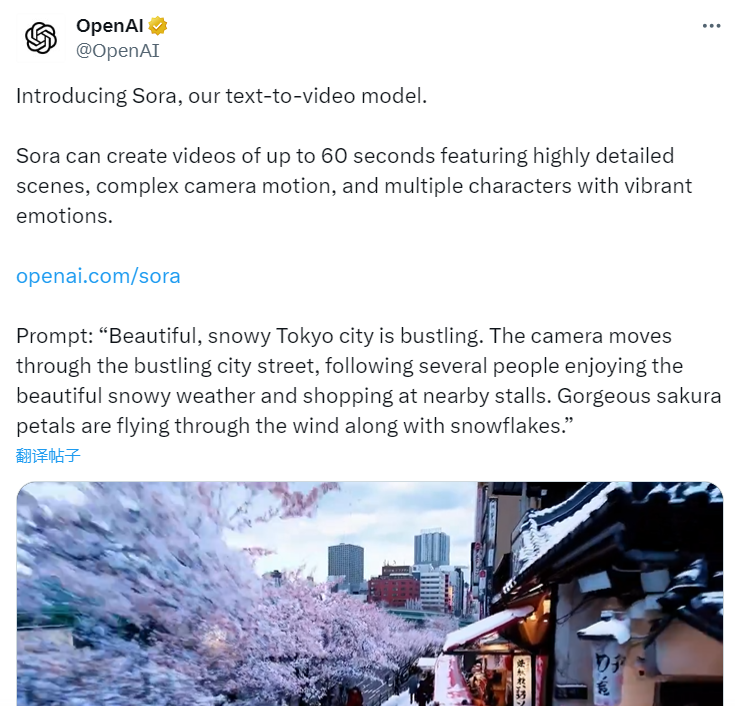
Complex Multiplier Examples (VHDL)
Fully pipelined complex multiplier using three DSP blocks.
Filename: cmult.vhd
-- Complex Multiplier (pr+i.pi) = (ar+i.ai)*(br+i.bi)
--
--
-- cumult.vhd
--
library ieee;
use ieee.std_logic_1164.all;
use ieee.numeric_std.all;
entity cmult is
generic(AWIDTH : natural := 16;
BWIDTH : natural := 16);
port(clk : in std_logic;
ar, ai : in std_logic_vector(AWIDTH - 1 downto 0);
br, bi : in std_logic_vector(BWIDTH - 1 downto 0);
pr, pi : out std_logic_vector(AWIDTH + BWIDTH downto 0));
end cmult;
architecture rtl of cmult is
signal ai_d, ai_dd, ai_ddd, ai_dddd : signed(AWIDTH - 1 downto 0);
signal ar_d, ar_dd, ar_ddd, ar_dddd : signed(AWIDTH - 1 downto 0);
signal bi_d, bi_dd, bi_ddd, br_d, br_dd, br_ddd : signed(BWIDTH - 1 downto
0);
signal addcommon : signed(AWIDTH downto 0);
signal addr, addi : signed(BWIDTH downto 0);
signal mult0, multr, multi, pr_int, pi_int : signed(AWIDTH + BWIDTH downto
0);
signal common, commonr1, commonr2 : signed(AWIDTH + BWIDTH downto 0);
begin
process(clk)
begin
if rising_edge(clk) then
ar_d <= signed(ar);
ar_dd <= signed(ar_d);
ai_d <= signed(ai);
ai_dd <= signed(ai_d);
br_d <= signed(br);
br_dd <= signed(br_d);
br_ddd <= signed(br_dd);
bi_d <= signed(bi);
bi_dd <= signed(bi_d);
bi_ddd <= signed(bi_dd);
end if;
end process;
-- Common factor (ar - ai) x bi, shared for the calculations
-- of the real and imaginary final products.
--
process(clk)
begin
if rising_edge(clk) then
addcommon <= resize(ar_d, AWIDTH + 1) - resize(ai_d, AWIDTH + 1);
mult0 <= addcommon * bi_dd;
common <= mult0;
end if;
end process;
-- Real product
--
process(clk)
begin
if rising_edge(clk) then
ar_ddd <= ar_dd;
ar_dddd <= ar_ddd;
addr <= resize(br_ddd, BWIDTH + 1) - resize(bi_ddd, BWIDTH + 1);
multr <= addr * ar_dddd;
commonr1 <= common;
pr_int <= multr + commonr1;
end if;
end process;
-- Imaginary product
--
process(clk)
begin
if rising_edge(clk) then
ai_ddd <= ai_dd;
ai_dddd <= ai_ddd;
addi <= resize(br_ddd, BWIDTH + 1) + resize(bi_ddd, BWIDTH + 1);
multi <= addi * ai_dddd;
commonr2 <= common;
pi_int <= multi + commonr2;
end if;
end process;
--
-- VHDL type conversion for output
--
pr <= std_logic_vector(pr_int);
pi <= std_logic_vector(pi_int);
end rtl;