近来把一个模型导出为onnx并用onnx simplifier化简后转换为TensorRT engine遇到非常奇怪的问题,在我们的网络中有多个检测头时,转换出来的engine的推理效果是正常的,当网络中只有一个检测头时,转换出来的engine的推理效果奇差,类别得分经sigmoid()计算出来的很多很大的值,导致输出上百万个3D box,这明显不正常。
开始以为3D box的C++后处理解码部分有问题,调查折腾了不少时间发现根本没什么大问题,然后想起模型只有一个检测头输出不正常,有多个头时检测头时反而正常,于是去仔细翻看模型网络的实现代码,也没发现什么不对的,很郁闷,想到把用于TensorRT生成engine的onnx可视化出来看有何差异,刚开始看也没发现什么特别的,感觉展示出来的结构都很正确没毛病啊:
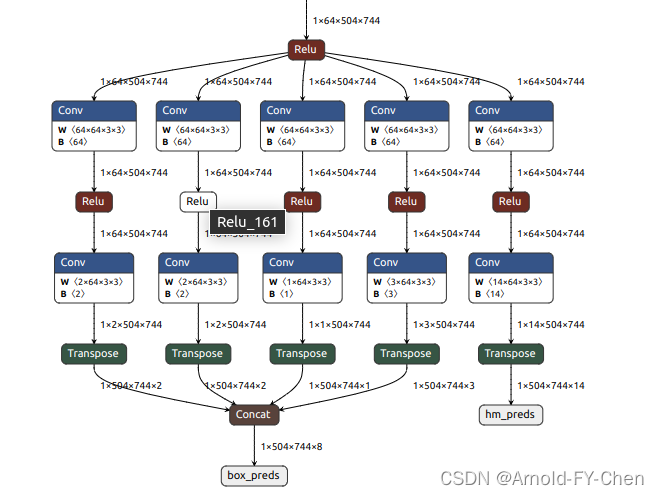

那为何多个检测头就正常一个检测头就不行呢?再仔细看代码,发现heatmap这个分支的输出tensor在作permute(onnx里对应的是Transpose)后有这么一句有关:
result['hm_preds'] = torch.cat(hm_preds_list, dim=-1)
hm_preds_list是个list,当有多个head时,会有多个hm_preds加入到这个[ ]里,只有一个检测头时就只有一个hm_preds加入这个[ ]里,很显然,当hm_preds_list里只有一个hm_preds时,torch.cat()不会作实质操作,只是依据hm_preds_list里的数据直接输出tensor而已,那我强制只有一个检测头时也作和有多个检测头时一样的算子运算会如何?于是修改代码当网络只配置有一个检测头时,将这个hm_preds tensor自己和自己强制来个Concat,也就是相当于torch.cat([hm_preds, hm_preds], dim=-1),然后为保持输出tensort的维度不变进行了切片,得到的网络结果是这样:

然后导出onnx并用onnx simplifier化简,生成TensorRT engine后推理结果就正常了!
那为何强制加了Concat后输出结果就正常了呢?再回头看从pytorch导出onnx和onnx化简全过程中网络结构上的变化,发现上面有一个检测头和有多个检测头时的网络的onnx图,发现,只有一个检测头时,像上面提到,因为torch.cat()没有实质操作,pytorch导出onnx时虽然在onnx生成了Concat算子节点,但是后面用onnx simplifier化简时,它会把这个Concat算子节点删掉,Transpose算子的输出就直接作为网络的hm_preds输出了,而有多个检测头时,torch.cat()会有实质拼接操作,Concat算子自然被onnx simplifier保留了,所以生成的TensorRT engine的推理结果正常!
于是我修改脚本,当网络只有一个检测头时,在调用onnx simplifier化简网络后,在Transpose算子节点后和网络的输出节点hm_preds之间强制增加Concat算子节点(注意指定attrs={"axis":-1})

然后再生成TensorRT engine,然后用这个engine推理就一切正常了!
再回头仔细想想这个问题的最终原因,当只有一个检测头时,TensorRT在对hm_preds tensor 作Transpose后因为后续没有其他算子了,没有触发输出Transpose后的tensor值而是把原始tensor值输出了?或者因为Transpose输出的hm_preds tensor在加入hm_preds_list后,因为hm_preds_list不是tensor,TensorRT把它丢弃了,直接用的Transpose处理前的tensor值?只能等后面哪天有时间再实验找找根本原因。
附上增加Concat节点的相关代码(:
hm_node = graph.outputs[1]
check_node = hm_node.inputs[0]
if check_node.op == 'Transpose': # only one head, no concat, need to add it forcibly
transpose_out = [gs.Variable("transpose_out", shape=hm_node.shape, dtype=hm_node.dtype)]
check_node.outputs = transpose_out
graph.layer(name="Concat_199", op= 'Concat', inputs=transpose_out, outputs=[hm_node], attrs={"axis":-1})
graph.cleanup().toposort()我们修改onnx使用的NVIDIA的ONNX GraphSurgeon,它封装后用起来比较简单,感觉比直接使用onnx的API修改网络容易得多,具体文档和examples可参见:
ONNX GraphSurgeon https://docs.nvidia.com/deeplearning/tensorrt/onnx-graphsurgeon/docs/index.html
https://docs.nvidia.com/deeplearning/tensorrt/onnx-graphsurgeon/docs/index.html
Examples![]() https://github.com/NVIDIA/TensorRT/tree/main/tools/onnx-graphsurgeon/examples
https://github.com/NVIDIA/TensorRT/tree/main/tools/onnx-graphsurgeon/examples